프로젝트 수행 기간 : 2021.3.22 ~ 4.10 약 3주간 (4-1학기)
개인 프로젝트
주제: 멀티 스레딩 개념과 캐시에 대한 개념을 이해하고 이것을 행렬 곱셈 최적화에 활용해보자.
목표:
4096*4096 크기의 두 행렬 곱셈 시간을 기존 5.7초(naiive 연산)에서 최대한 단축시킬 것.
작년의 최고 성적이었던 1.0초의 기록을 깨기 위해 1초 안쪽의 기록 달성을 위한 목표를 설정.
진행 프로세스:
- 우선 가장 직관적인 최적화를 위해 캐시 메모리에 대한 이해가 필요하다고 판단.
- 캐시가 데이터를 저장하는 방식, 용량, conflict 관리, 캐시 매핑 유형 등을 먼저 자세하게 공부함.
- 직접 코드로 구현해가며 각각의 방법이 얼마만큼의 시간을 단축시켰는지 기록해가며 관찰. 각 방법의 조합도 기록.
문제 해결과정:
- 캐시 메모리 접근의 특성을 이해하고, 불필요한 메모리 접근을 최소화하기 위해 전치 행렬로 전환.
- 캐시 메모리 크기에 맞추기 위해 행렬을 작은 크기의 블록들로 분할하여 연산하는 방식으로 바꿈.
- 마지막으로, 캐시의 매핑 형태를 이해하고 행렬의 크기가 2의 거듭제곱 수인 경우 느려지는 현상을 패딩을 적용시켜 해결.
결론:
- 위 과정을 모두 구현하여 단순 연산에서 5.7초가 걸리던 과정을 0.7초까지 약 8배 단축시킬 수 있었음.
- 다른 학우들에 비해 월등히 뛰어난 최적화 결과였음.
- 다른 학우들은 대부분 행렬의 크기가 2의 거듭제곱 수인 경우 성능이 안나오는 현상을 인지하지 못하거나 해결하지 못했었음.
- 교수님께서 긍정적인 피드백과 함께 다음 시간에 학우들 앞에서 발표 해줄 것을 요청하셨음.
서버 캐시 사이즈 (L1 + L2) : 512 KB
행렬 크기: (4096 * 4096) X (4096 * 4096)
캐시 정보: 8-way set associative, 64 set, 64B cache line
(8-way, 그런 set이 64개, 8-way에서 각각의 way가 담을 수 있는 데이터 64B)
Keyword
캐시에 대한 이해 (3가지 종류, conflict, cache thrashing)행렬 곱셈에 대한 이해 (matrix multiplication)- 캐시를 사용해서 성능 개선을 이루는 방법들
-전치 행렬 전환 (Transpose)
-블록 분할
-캐시 메모리 conflict (사이즈 2제곱수에서 속도 느려지는 이유) 근데 여기서 멀티스레딩 개념이 적용된 부분은 어디?
캐시
서로 다른 두 주소가 캐시의 같은 인덱스 값을 가르키면 충돌이 발생할 수 있다.
인덱스가 가리키는 블록을 여러 개 만드는 방식으로 해결할 수 있는데, 이 블록의 개수에 따라 캐시의 종류를 분류할 수 있다.
Direct mapped: 인덱스가 가리키는 공간이 하나인 경우. 처리가 빠르지만 충돌 발생이 많다.Fully associative: 인덱스가 모든 공간을 가리키는 경우. 충돌이 적지만 모든 블록을 탐색해야 해서 속도가 느리다.Set associative: 인덱스가 가리키는 공간이 두 개 이상인 경우. n-way set associative 캐시라고 부른다.
Cache Thrashing
프로그램에서 자주 필요한 두 개 이상의 데이터들이 같은 캐시 값에 맵핑 될 때 일어난다.
이 중 하나의 데이터라도 삽입될 때마다 다른 필요한 데이터를 오버라이트 해, 캐시 미스를 일으키고 데이터 재사용 여부를 손상시키는 현상이다.
캐시 활용 성능 개선 방법들
전치 행렬 전환
A와 B 행렬을 곱셈할 때, A 행렬은 행을 따라, B 행렬은 열을 따라 곱셈을 한 뒤 그 모든 값들의 합을 결과로 출력한다.
하지만 cache가 접근하는 공간 지역성을 생각해보면,
B 행렬의 열을 따라가며 값을 받아올 때마다 캐시 미스가 나는 것을 알 수 있다.
심지어 캐시 사이즈가 (cache line/데이터 타입(4B))*N 보다 작은 경우에는 다음 열로 이동할 때도 캐시에 저장된 값을 사용하지 못하고 또 미스가 나게 된다.
따라서, B 행렬의 데이터들을 전치시켜 행렬 곱셈을 진행시킨다면 A 행렬과 마찬가지로 행을 따라 연산을 수행할 수 있고
그렇게 되면 읽는 연산 시, cache line 크기로 나눈 만큼의 최적화를 이룰 수 있다. (N^3 / c)
블록 분할
행렬의 한 변의 크기를 N이라 할 때, 한 개 위치에 대해 답을 내기 까지 N번의 행을 훑는 작업이 필요하다. 그리고 다음 위치에 대해 답을 계산할 때 똑같은 패턴으로 행에 접근하게 된다.
만약 이 때 캐시의 전체 용량이 그 전의 과정(N번 훑기) 에서 저장한 데이터만으로 가득 차거나 부족해진다면,
똑같은 패턴으로 행에 접근함에도 불구하고 캐시에 저장된 값이 남아있지 않기 때문에 전혀 캐시를 이용하지 못하게 되고 성능 개선을 이룰 수 없다.
따라서 한 과정의 연산을 마치고 다음 연산까지 캐시에 계속 접근할 값을 남겨두는 것이 관건일 것이고, 캐시에 크기에 맞춰 한 과정의 크기를 결정하는 것이 맞다.
따라서, 전체 행렬의 크기보다 작은 여러 개의 블록들로 나누어 계산하는 기법을 사용한다면 보다 효율적으로 캐시 값을 활용할 수 있을 것이다.
캐시 충돌 (사이즈 2제곱수에서 속도 느려지는 이유)
Cache aliasing ,Set-associative cache(2-way, 4-way...)
- Cache aliasing: Multiple data mapping to the same cache set.
- 평소 대로라면, 2의 거듭제곱 수 size 에서 더 regular access 패턴이 나타나기 때문에 성능이 좋아지는게 맞다. 하지만, 위의 cache aliasing 이슈 때문에 성능이 갑자기 뚝 떨어지는 것.
- Set-associative cache 패턴이 2의 제곱 수 (2-way, 4-way, 8-way …) 이기 때문에 일어나는 일이다.
아래 그림은 N=2^n (2제곱수인 경우)
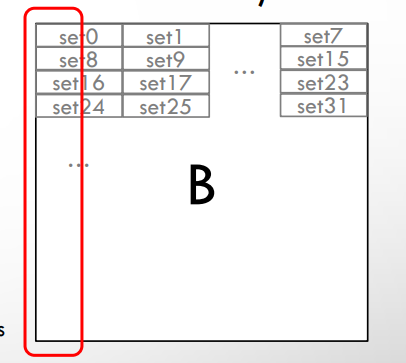
아래 그림은 N이 2제곱수가 아닌 경우 -> 모든 캐시 라인을 사용할 수 있다.
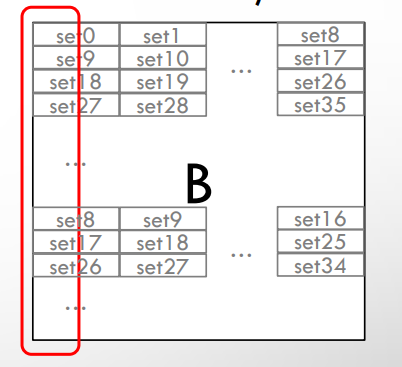
반면에 N=2제곱수인 경우,
8-way set 캐시의 8의 배수 단위의 set 개수들이 행렬의 한 줄에 들어가기 때문에 (캐시 라인 사이즈 64B)
ex. N=128 -> 128*4B/64B = 8 cache lines
ex2. N=144 -> 144*4B/64B = 9 cache lines
모든 캐시 라인을 사용할 수도 없는 데다가 같은 패턴으로 캐시 충돌이 계속 일어나게 된다.
그럼 왜 set-associative 사이즈는 2의 제곱 수인가?
← 하드웨어 적으로 2의 제곱 수의 사이즈 캐시 set을 사용하는게 유리하기 때문에.
캐시 셋을 동일한 크기의 subset으로 나누는게 간편하고, 캐시 인덱싱을 위한 bit연산을 하는게 편리해서
왜 Padding을 두르는게 효과가 있나?
← 행렬의 여러 부분들의 데이터가 캐시 라인 한 개에 적절히 분배되는 효과.
따라서 cache conflict가 나도 특정 캐시 라인에 겹치는 데이터가 더 적어질 수 있다.
하지만, 공간을 더 쓰는 것이므로 메모리 오버헤드와 trade-off 관계에 있다.
P P P P P P P P
P A11 A12 A13 A14 P P P
P A21 A22 A23 A24 P P P
P A31 A32 A33 A34 P P P
P A41 A42 A43 A44 P P P
P P P P P P P P이렇게 패딩을 두르면 캐시 라인 사이즈가 4라고 할 때,
**(Before)**
Cache Line 1: A11 A12 A13 A14
Cache Line 2: A21 A22 A23 A24
Cache Line 3: A31 A32 A33 A34
Cache Line 4: A41 A42 A43 A44이런 식으로 한 개의 캐시 라인에 규칙적으로 같은 데이터가 쌓이는 반면,
**(After)**
Cache Line 1: P P P P
Cache Line 2: P A11 A12 A13
Cache Line 3: A14 P P P
Cache Line 4: P A21 A22 A23
Cache Line 5: A24 P P P
Cache Line 6: P A31 A32 A33
Cache Line 7: A34 P P P
Cache Line 8: P A41 A42 A43
Cache Line 9: A44 P P P
Cache Line 10: P P P P패딩을 두르면 이렇게 행렬 데이터가 적절하게 분배되는 효과가 있다.
따라서 cache conflict가 날 확률을 감소시킬 수 있다.
근데 여기서 멀티스레딩 개념이 적용된 부분은 어디?
블록 분할을 이용한 기법에서 멀티스레딩 개념이 들어가게 되어 전체 연산 속도를 더 끌어올릴 수 있었다고 생각합니다.
즉, 각 스레드는 여러 개로 분할된 블록을 각각 처리할 수 있고 이 과정은 동시에 일어나기 때문에
이런병렬 처리로 전체 연산 속도를 크게 끌어 올릴 수 있었다고 생각합니다.
