
0. 목적 및 동기
컴퓨터공학부 2학년이나 됐는데 파이썬을 잘 모른다..
심지어 컴퓨터에 파이썬이 깔려있지도 않다 왜냐?
1학년때 파이썬 교양 안들음 -> 2학기때 C++ 배우느라 안배움 -> 2-1때 자료구조때 배우려고 방학때 학원 다녔으나 ㅂㄹ임 심지어 수강신청 망해서 C로 자료구조 배움
이번엔 진짜 열심히 들어서 파이썬 마스터 하구 AI 공부 해볼거다 !!
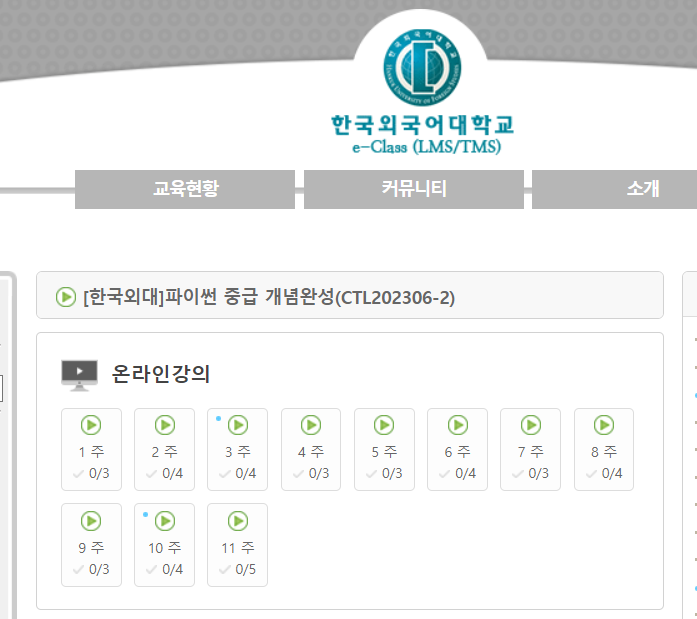
(내가 이번 방학때 들을 강의)
계획 - 1일 1주차 (한 주차에 40분 짜리 3개 강의 있음)
1.1 파이썬 개요
스루했으요
1.2 파이썬 설치
설치 완료 !
이 강의에 쓸 practice 파일도 vs code에 놓아놨당
1.3 변수와 자료형 (구문, 연산자, 표준입력장치, 문자열)
키워드
: 특별한 의미가 부여된 단어
파이썬에서 이미 특정 의미로 사용하기로 예약 해놓은 것
변수나 함수 이름으로 사용 불가능
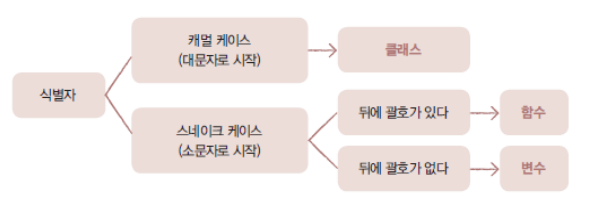
식별자
: 프로그래밍 언어에서 이름 붙일 때 사용하는 단어
변수 또는 함수 이름으로 사용
( 숫자 시작 X , 공백 X, 특수문자는 언더바만 허용)
스네이크 케이스 : 언더바를 기호 중간에 붙이는 것 ex) item_list
캐멀 케이스 : 단어의 첫글자를 대문자로 만들기 ex) ItemList
주석
: 프로그램 진행에 영향을 주지 않는 코드, #을 기호로 사용
연산자

출력
: print()함수 사용
여러개 출력하고자 하면 ,를 쓰자
ex) print(52,273, "hello")
-> 52 273 hello
줄바꿈 : print()
2.1 변수와 자료형
변수
: 필요한 자료를 일시적으로 보관하거나 처리 결과를 담을 수 있는 기억장소
var1 = "hello python"
print(var1)
print(id(var1))
print(type(var1))output
hello python
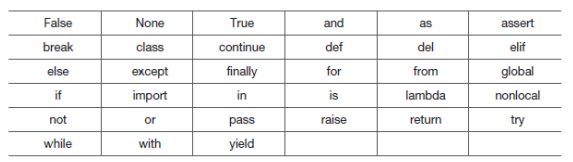
41324115예약어 확인하기
import keyword
python_keyword = keyword.kwlist
print(python_keyword)output
['False', 'None', 'True', 'and', 'as', 'assert', 'async',
'await', 'break', 'class', 'continue', 'def', 'del',
'elif', 'else', 'except', 'finally', 'for', 'from',
'global', 'if', 'import', 'in', 'is', 'lambda', 'nonlocal',
'not', 'or', 'pass', 'raise', 'return', 'try', 'while',
'with', 'yield']자료
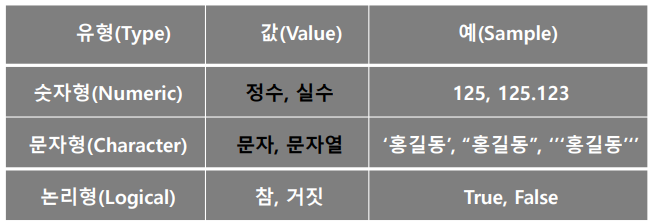
: 프로그램이 처리할 수 있는 모든 것
자료형
: 자료를 기능과 역할에 따라 구분한 것
var2 = 150.25
print(type(var2))output
hello python
<class 'str'>자료형 변환
#실수 -> 정수
a = int(10.5)
b = int(20.42)
add = a + b
print("add = ", add)
#정수 -> 실수
a = float(10)
b = float(20)
add2 = a + b
print("add2 = ", add2)
#논리형 -> 정수
print(int(True)) #1
print(int(False)) #0
#문자형 -> 정수
st = '10'
print(int(st)**2) #100output
add = 30
add2 = 30.0
1
0
1002.2 변수와 자료형 (연산자)
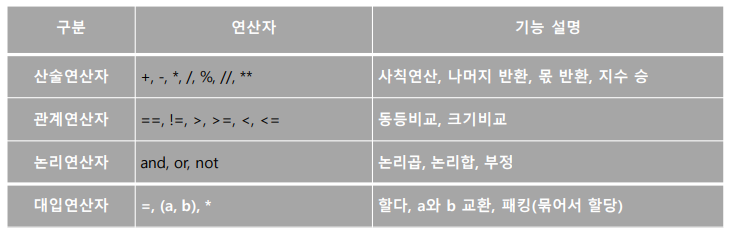
연산자
: 파이썬에서 제공되는 연산자는 산술, 관계, 논리, 대입연산자가 있다
산술연산자
num1=100
num2=20
add = num1+num2
print('add = ',add)
sub=num1-num2
print('sub = ',sub)
mul = num1*num2
print('mul = ',mul)
div = num1/num2
print('div = ',div)
div2 = num1%num2
print('div2 = ',div2)
square = num1**2
print('square = ',square)output
add = 120
sub = 80
mul = 2000
div = 5.0
div2 = 0
square = 10000관계연산자
: 관계식의 결과가 참이면 true, 거짓이면 false를 반환한다
1) 동등비교
#동등비교
bool_result = num1 == num2
print(bool_result) #false
bool_result = num1 !=num2
print(bool_result) #trueoutput
false
true2) 크기 비교
bool_result = num1>num2
print(bool_result)
bool_result = num1>=num2
print(bool_result)
bool_result = num1<num2
print(bool_result)
bool_result = num1<=num2
print(bool_result)output
true
true
false
false논리연산자
: 산술연산자와 관계연산자를 이용해서 논리식이 참이면 true, 거짓이면 false를 반환
(and가 쓰이면 둘다 참이여야지 true, or이 쓰이면 한쪽만 참이여도 true)
log_result = num1>=50 and num2<=10
print(log_result)
log_result = num1>=50 or num2<=10
print(log_result)
log_result = num1>=50
print(log_result)
log_result = not(num1>=50)
print(log_result)output
false
true
true
false대입연산자
: 우변의 값을 좌변의 변수에 할당하는 연산자 (=), 두 변수의 값을 교환하는 연산자, 그리고 여러개의 값을 묶어서 변수에 할당하는 연산자 (*)로 구성되어있음
1) 변수에 값 할당(=)
i = tot = 10
i+=1
tot+=1
print(i,tot)output
11 11같은 줄에 중복 출력
print('출력1',end =' , ')
print('출력2')output
출력1, 출력2(2) 변수 교체
v1,v2=100,200
v2,v1=v1,v2
print(v1,v2)output
200 100(3) 패킹(packing)할당
: 여러개의 값을 묶어서 변수에 할당할 경우는 패킹연산자(별*)를사용함
lst = [1,2,3,4,5]
v1, *v2=lst
print(v1,v2)output
1 [2,3,4,5]ㄴ lst 변수는 5개의 원소를 갖는 배열 형식의 변수임. 이 변수를 대상으로 v1에는 첫번째 원소가 할당되고 나머지 패킹연산자로 지정한 v2변수에 나머지 4개가 묶여서 할당되는 것
input
*v1, v2 = lst
print(v1,v2)output
[1,2,3,4]5ㄴ v1변수에 별 기호를 붙이면 앞부분 4개의 원소가 묶여서 v1변수에 할당되고 마지막 5번째 원소만 v2 변수에 할당된다
2.3 변수와 자료형 (표준입출력장치)
표준입출력장치
num=input("숫자 입력 : ")
print('num type : ',type(num))
print('num = ',num)
print('num = ',num*2)
num1 = int(input("숫자 입력 : "))
print('num1 = ',num1*2)
num2 = float(input("숫자 입력 : "))
result = num1 + num2
print('result = ',result)output
숫자입력 : 20
num type : <class 'str'>
num = 20
num = 2020
숫자입력 : 20
num1 = 40
숫자 입력 : 20
40.0value 인수
print('value = ',10 + 20 + 30 + 40 + 50)sep 인수
: 값과 값을 특수문자로 구분해준다
print("010","1234","5678",sep="-")output
010-1234-5678end 인수
: 다음에 출력되는 내용이 현재 출력되는 내용과 구분자에 의해 같은 줄에 구분되어 출력된다
print("value = ", 10 , end = ", ")
print("value = ",20)output
value = 10, value = 20format 과 양식문자
format()함수는 값을 지정한 형식으로 변환해주는 함수
ex) format(value,"format") -> builtins
# format함수 인수 : format(value,"format")
print("원주율 = ", format(3.14159, "8.3f"))
print("금액 = ",format(10000,"10d"))
print("금액 = ", format(125000, "3,d"))output
3.142
10000
125,000ㄴ 원주율을 전채 8개의 자릿수를 기준으로 소수점 이하 3째자리까지 표시됨. 전체 자릿수에서 빈 자리는 공백으로 채워지고 소숫점은 4째 자릿수에서 반올림됨
양식문자 : print("%양식문자" %(값)) 형식임
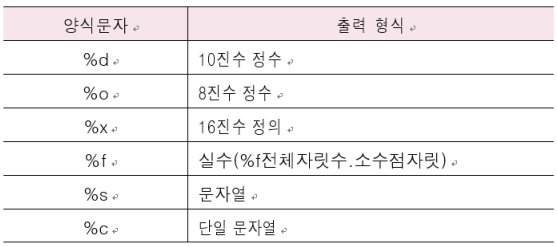
# 양식문자 인수 : print("%양식문자"%(값))
name = "이서연"
age = 21
price = 123.456
print("이름 : %s, 나이 : %d, data = %.2f" % (name, age, price))output
이름 : 이서연, 나이 : 21, data = 123.46ㄴ %.2f는 실수형 자료를 대상으로 소숫점 2자리까지 표기하는 양식임
외부상수 출력
: print("{}" .format(값)) 형식이다. {}를 이용해서 외부 값을 순서대로 받아서 출력함
print("이름 : {}, 나이 : {}, data ={}".format(name,age,price))
print("이름 : {1}, 나이 : {0}, data ={2}".format(age,name,price))output
이름 : 이서연, 나이 : 21, data = 125.46
이름 : 이서연, 나이 : 21, data = 125.456format 축약형
: forma(값)을 {값} 형식으로 직접 {} 기호 안에 값을 표기하고 따옴표 왼쪽에 f를 표시하는 format 함수의 축약형
uid = input("id input : ")
query = f"select * from member where uid = {uid}"
print(query)output
id input : yiseo
select * from member where uid = yiseo2.4 변수와 자료형 (문자열)
문자열
: 문자들의 집합으로 ', ", """ 를 사용하여 문자들을 감싼 형태로 표현함
"""(삼중따옴표) = 여러줄의 문자열을 표현할 때 사용한다
ex)
oneLine = "this is one line string"
print(oneLine)output
this is one line string따옴표 안에서 강제 줄바꿈하기
multiLine = """this is
multi line
string """
print(multiLine)output
this is
multi line
string줄바꿈의 기능을 갖는 이스케이프 문자(\n) 이용하기
multiLine2 = "this is \nmulti line\nstring"
print(multiLine2)output
this is
multi line
string문자열의 특징
: 문자들의 집합이어서 일정한 순서(index)를 가짐
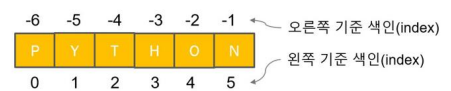
1) 문자열 색인
string = "PYTHON"
print(string[0])
print(string[5])
print(string[-1])
print(string[-6])output
P
N
N
P2) 문자열 연산
print("python"+" program") #결합연산자
print("python-"+str(3.7)+".exe")
print("-"*30) #반복연산자output
python program
python-3.7.exe
------------------------------문자열 처리함수
: 문자열을 수정하거나 조작하는 함수
형식 = 문자열객체.함수([인수])
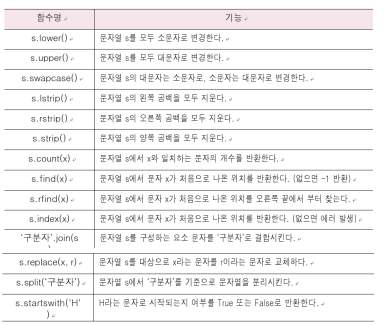
(1) 특정 글자 수 반환
count()함수는 특정 문자가 출현된 수를 반환하는 함수이다
oneLine = "this is one line string"
print("t 글자수 : ", oneLine.count("t"))output
t 글자 수 : 2(2) 접두어 문자 비교 판단
startswith()함수는 접두어가 'this'이면 true를 반환하고 다른 접두어이면 false를 반환함
print(oneLine.startswith("this"))
print(oneLine.startswith("that"))output
True
False(3) 문자열 교체
replace() 함수는 첫번째 매개변수를 두번째 매개변수로 교체하는 역할을 한다
print(oneLine.replace("this", "that"))output
this is one line string(4) 문자열 분리(split) : 문단 -> 문장
split() 함수는 안에 들어가는 걸 기준으로 문자열을 분리함
multiLine = """this is
multi line
string"""
sent = multiLine.split("\n")
print("문장 : ", sent)output
문장 : ['this is ', 'multi line', 'string'](5) 문자열 분리 (split2) : 문장 -> 단어
words = oneLine.split(' ')
print('단어 : ', words)output
단어 : ['this', 'is', 'one', 'line', 'string'](6) 문자열 결합 (join) : 단어 -> 문장
join() 함수는 앞에 ''안에 들어가는 구분자를 기준으로 다시 하나의 문자열로 결합해줌
sent2=','.join(words)
print(sent2)output
this,is,one,line,string이스케이프 문자
: 명령어 이외에 특수기능을 갖는 문자들
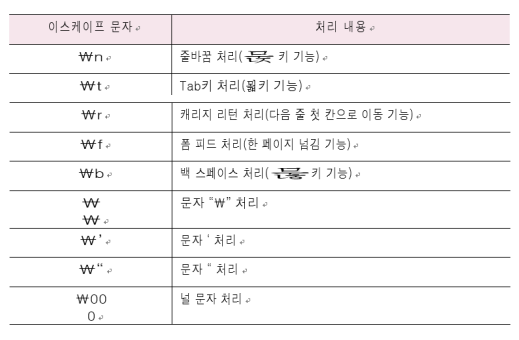
#(1) escape 문자 기능 차단
역슬래시를 하나 더 붙이거나 문자열 앞에 r을 붙이면 된다
print('\\n출력 이스케이프 기능 차단1')
print(r'\n출력 이스케이프 기능 차단2')output
\n출력 이스케이프 기능 차단1
\n출력 이스케이프 기능 차단2#(2) 경로 표현 : C:\Python\test
print('path = ', 'C:\Python\test')
print('path = ', 'C:\\Python\\test')
print('path = ', r'C:\Python\test')output
path = C:\Python est
path = C:\Python\test
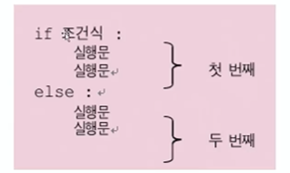
path = C:\Python\test3.1 제어문 (조건문)
제어문
: 프로그램의 흐름을 변경해주는 조건문과 특정 명령문들을 반복해서 수행하는 반복문으로 구성됨
조건문
: 특정 조건식에 따라서 실행문의 실행이 결정되는 명령문 ex) if, elif, else
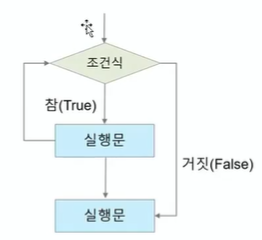
단일조건문
: 조건식 한개를 기준으로 비교판단하여 처리하는 형식
# 단일조건문
var = 10
if var >= 5:
print("var = ", var)
print("var는 5보다 크다")
print("조건이 참인 경우 실행")output
var = 10
var는 5보다 크다
조건이 참인 경우 실행단일조건문 2
score = int(input("점수 입력 : "))
if score >= 85 and score <= 100:
print("우수")
else:
if score >= 70:
print("보통")
else:
print("저조")output
87을 넣었을 때 )
우수
50을 넣었을 때 )
저조중첩 조건문
: if 불록 내에 또 다른 if 블록이 포함된 형태

score = int(input('점수 입력 : '))
grade = ''
if score >=85 and score <=100:
grade = '우수'
elif score>=70:
grade = '보통'
else:
grade = '저조'
print('당신의 점수는 %d이고 등급은 %s'%(score,grade))output
점수 입력 : 89
당신의 점수는 89이고, 등급은 우수입니다.
점수 입력 : 75
당신의 점수는 75이고, 등급은 보통입니다.삼항 조건문 (삼항연산자)
: 조건식이 참인 경우와 거싲인 경우의 처리할 문장을 한줄로 작성하고 실행문이 실행되는 것

num=9
result2 = num*2 if num>=5 else num+2
print('result2 = ',result2)output
result2 = 183.2 반복문 (while)
반복문
: 특정 부분을 반복해서 실행하는 명령문 ex) while, for
while문
: 조건식과 루프로 블록을 구성한다

(1) 카운터와 누적변수
cnt = tot = 0
while cnt<5:
cnt +=1
tot +=cnt
print(cnt,tot)output
1 1
2 3
3 6
4 10
5 15(2) 1~100 사이의 3의 배수 합과 원소 추출하기
cnt = tot =0
dataset=[]
while cnt<100:
cnt+=1
if cnt%3==0:
tot+=cnt
dataset.append(cnt)
print('1~100 사이 3의 배수의 합 = %d'%tot)
print('dataset = ',dataset)output

무한루프
: 반복문에서 사용되는 조건식이 True인 경우를 말함.조건식이 True이기 때문에 반드시 exit 조건을 지정해줘야한다.
random모듈
: 임의의 난수를 발생시키는 함수들을 제공
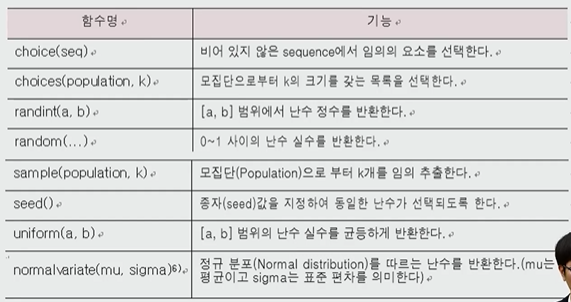
(1) random모듈 추가
import random
help(random)(2) random모듈의 함수 도움말
help(random.random)(3) 0~1 사이 난수 실수
r = random.random()
print('r=',r)output
r= 0.10730612691136654(4) 난수 0.01 미만이면 종료 후 난수 개수 출력
cnt=0
while True:
r=random.random()
print(random.random())
if r<0.01:
break
else:
cnt+=1
print('난수 개수 = ',cnt)(5) 이름 list에 전체이름, 특정이름 출력
import random
names = ['일서연','이서연','삼서연']
print(names)
print(names[2])output
['일서연', '이서연', '삼서연']
삼서연(6) list 에서 자료 유무 확인하기
if'이서연'in names:
print('이서연 있음')
else:
print('이서연 없음')output
이서연 있음(7) 난수 정수로 이름 선택하기
- randint(,) 첫번째 매개변수 ~ 두번째 매개변수 사이의 정수를 랜덤하게 꺼내줌
idx = random.randint(0,2)
print(names[idx])output
삼서연break, continue
i=0
while i<10:
i+=1
if i==3:
continue
if i==6:
break
print(i,end=' ')output
1 2 4 5 3.3 반복문 (for문)
for문
: 별도의 조건식이 없는 대신에 열거형객체를 이용한다

(1) 문자열 열거형객체 이용
string = '이서연'
print(len(string))
for s in string:
print(s)output
3
이
서
연(2) list 열거형객체 이용
lstset=[1,2,3,4,5]
for e in lstset:
print('원소 : ',e)output
원소 : 1
원소 : 2
원소 : 3
원소 : 4
원소 : 5for & range
#1 range(a,b)
: a ~ b-1 까지
#2 range(1,b)
: 1 ~ b-1 까지
#3 range(a,b,c)
: a ~ b-1 까지인데 c만큼 퐁당퐁당
(1) range 객체 생성
num1 = range(10)
print('num1 : ',num1)
num2 = range(1,10)
print('num2 : ',num2)
num3 = range(1,10,2)
print('num3: ',num3)output
num1 : range(0, 10)
num2 : range(1, 10)
num3: range(1, 10, 2)(2) range 객체 활용
for n in num1:
print(n,end = ' ',)
for n in num2:
print(n, end = ' ')
for n in num3 :
print(n, end = ' ')output
0 1 2 3 4 5 6 7 8 9
1 2 3 4 5 6 7 8 9
1 3 5 7 9 for & list
: 순차적으로 자료를 저장하고, 저장된 자료를 인덱스로 참조할 수 있다
(1) list에 자료 저장하기
lst =[]
for i in range(10):
r = random.randint(1,10)
lst.append(r)
print('lst = ',lst)output
lst = [2,4,5,4,3,9,1,10,9,5](2) list에 자료 참조하기
lst = [1,2,3,4,5,6,7,8,9,10]
for i in range(10):
print(lst[i]*0.25)output
0.25
0.5
0.75
1.0
1.25
1.5
1.75
2.0
2.25
2.5중첩반복문
: 반복문 안에 또 다른 반복문이 포함된 명령문
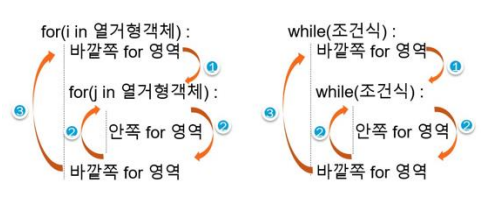
(1) 구구단 출력
for i in range(2,10):
print('~~~ {}단 ~~~'.format(i))
for j in range(1,10):
print('%d * %d = %d'%(i,j,i*j))output
~~~ 2단 ~~~
2 * 1 = 2
2 * 2 = 4
2 * 3 = 6
2 * 4 = 8
2 * 5 = 10
2 * 6 = 12
2 * 7 = 14
2 * 8 = 16
2 * 9 = 18
~~~ 3단 ~~~
3 * 1 = 3
3 * 2 = 6
3 * 3 = 9
3 * 4 = 12
3 * 5 = 15
3 * 6 = 18
3 * 7 = 21
3 * 8 = 24
3 * 9 = 27
~~~ 4단 ~~~
4 * 1 = 4
4 * 2 = 8
4 * 3 = 12
4 * 4 = 16
4 * 5 = 20
4 * 6 = 24
4 * 7 = 28
4 * 8 = 32
4 * 9 = 36
~~~ 5단 ~~~
5 * 1 = 5
5 * 2 = 10
5 * 3 = 15
5 * 4 = 20
5 * 5 = 25
5 * 6 = 30
5 * 7 = 35
5 * 8 = 40
5 * 9 = 45
~~~ 6단 ~~~
6 * 1 = 6
6 * 2 = 12
6 * 3 = 18
6 * 4 = 24
6 * 5 = 30
6 * 6 = 36
6 * 7 = 42
6 * 8 = 48
6 * 9 = 54
~~~ 7단 ~~~
7 * 1 = 7
7 * 2 = 14
7 * 3 = 21
7 * 4 = 28
7 * 5 = 35
7 * 6 = 42
7 * 7 = 49
7 * 8 = 56
7 * 9 = 63
~~~ 8단 ~~~
8 * 1 = 8
8 * 2 = 16
8 * 3 = 24
8 * 4 = 32
8 * 5 = 40
8 * 6 = 48
8 * 7 = 56
8 * 8 = 64
8 * 9 = 72
~~~ 9단 ~~~
9 * 1 = 9
9 * 2 = 18
9 * 3 = 27
9 * 4 = 36
9 * 5 = 45
9 * 6 = 54
9 * 7 = 63
9 * 8 = 72
9 * 9 = 81배열을 써서 특정 단만 출력시킬 수 있다
for i in [2,3,5]:
print('~~~ {}단 ~~~'.format(i))
for j in [1,2,3,4,5,6,7,8,9]:
print('%d * %d = %d'%(i,j,i*j))(2) 문장과 단어 추출
string = """나는 이서연입니다.
주소는 수원시입니다.
나이는 21세 입니다."""
sents = []
words=[]
for sen in string.split(sep="\n"): #줄바꿈을 기준으로 나눠주고
sents.append(sen) # sents 배열에 넣어준다
for word in sen.split(): # 공백을 기준으로 나눠주고
words.append(word) #words 배열에 넣어준다
print('문장 : ',sents)
print('문장 수 : ',len(sents))
print('단어 : ',words)
print('단어 수 : len(words))3.4 자료구조 (str, 리스트)
자료구조
: 프로그래밍에 의해 만들어진 객체가 메모리에 배정될 때 기억공간에 적재되는 구조
순서 자료구조
: str, list, tuple 등의 클래스를 자료구조를 생성하기 위해 제공된다
str
: 이 클래스는 문자열 객체를 만들어주는 클래스임
ex) str_var = str(object = '대한민국') 으로 '대한민국' 문자열 객체를 생성할 수 있음
근데 그냥 간편하게 str_var = '대한미국'으로 작성할 수는 있다
(1) str 클래스 형식
str_var = str(object = 'string')
print(str_var)
print(type(str_var))
print(str_var[0])
print(str_var[-1])output
string
<class 'str'>
s
g(2) str 클래스 간편 형식
str_var2='string' #간편형식
print(str_var)
print(type(str_var2))
print(str_var2[0])
print(str_var2[-1])output
string
<class 'str>
s
g리스트
: 여러개의 자료를 순서대로 적재하는 가변길이 순차 자료구조를 생성하는 클래스
대괄호 안에 콤마를 이용하여 순서대로 값을 나열함

(1) 단일 리스트 객체
lst =[1,2,3,4,5]
print(lst)
print(type(lst))
for i in lst :
print(lst[:i]) #i 까지여기서 [:i]는 슬라이싱 기법이 이용된 것임. 원래는 lst[시작:끝]으로 쓰여서 시작 부터 끝까지를 추출하는데 여기선 시작이 생략되었기 때문에 그냥 리스트의 시작부터 끝까지 서브리스트를 추출하는것임
output
[1, 2, 3, 4, 5]
<class 'list'>
[1]
[1, 2]
[1, 2, 3]
[1, 2, 3, 4]
[1, 2, 3, 4, 5](2) 단일 lsit 색인
x = list(range(1,11))
print(x)
print(x[:5]) #처음부터 5번째까지
print(x[-5:]) #-5번째 부터
# index 2씩 증가
print(x[::2]) #홀수 인덱스
print(x[1::2]) #1부터 시작하는 짝수 인덱스[start:stop:step]이라고 볼 수 있음 !
output
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
[1, 2, 3, 4, 5]
[6, 7, 8, 9, 10]
[1, 3, 5, 7, 9]
[2, 4, 6, 8, 10]중첩 리스트
: 리스트 내에 또 다른 리스트가 포함된 형식
a= ['a','b','c']
print(a)
b=[10,20,a,5,True,'문자열']
print(b[0])
print(b[2])
print(b[2][0])
print(b[2][1:])output
['a', 'b', 'c']
10
['a', 'b', 'c']
a
['b', 'c']리스트 연산
: 사칙연산에서 제공되는 기호를 이용하여 + 와 * 가 가능하다.
(1) 리스트 결합
x=[1,2,3,4]
y=[1.5,2.5]
z=x+y
print(z)output
[1, 2, 3, 4, 1.5, 2.5](2) 리스트 확장
x.extend(y) # 확장
print(x)output
[1, 2, 3, 4, 1.5, 2.5](3) 리스트 추가
x.append(y) # x 추가
print(x)output
[1, 2, 3, 4, 1.5, 2.5, [1.5, 2.5]](4) 리스트 두 배 확장
lst = [1,2,3,4]
result = lst*2 # 각 원소가 연산되는 것이 아님
print(result)output
[1, 2, 3, 4, 1, 2, 3, 4]리스트 정렬과 요소 검사
리스트 원소가 숫자이면 오름차순 또는 내림차순으로 정렬할 수 있음
리스트 원소 중에서 특정 값의 존재 유무를 알려주는 기능도 있어서 찾는 값이 있으면 True가, 없으면 False가 반환됨
(1) 리스트 정렬
print(result)
result.sort() #오름차순 정렬
print(result)
result.sort(reverse = True) # 내림차순 정렬
print(result)result.sort() = 오름차순
result.sort(reverse = True) = 내림차순
output
[1, 2, 3, 4, 1, 2, 3, 4]
[1, 1, 2, 2, 3, 3, 4, 4]
[4, 4, 3, 3, 2, 2, 1, 1](2) 리스트 요소 검사
import random
r = []
for i in range(5):
r.append(random.randint(1,5))
print(r)
if 4 in r:
print('있음')
else:
print('없음')output
[1,3,5,2,2]
없음4.1 자료구조 (리스트 내포, 튜플)
리스트 내포
: list안에서 for와 if를 사용하는 문법

for문에서 열거형 객체의 원소 하나를 변수로 넘겨 받는다 -> 변수에 할당된 값을 실행문으로 처리한다 -> 처리된 결과를 변수에 순차적으로 추가(append)한다
for과 if를 함께 사용하기

for문에서 열거형 객체의 원소 하나를 변수로 넘겨 받는다 -> 변수에 할당된 값을 조건식으로 사용하여 비교 판단한다 -> 조건이 참이면 변수에 할당된 값을 실행문으로 처리한다 -> 처리된 결과를 변수에 순차적으로 추가(append)한다.
(1) 변수 = [실행문 for ]
lst = [i**2 for i in x] # x변량에 제곱 계산
print(lst)output
[4, 16, 1, 25, 49](2) 변수 = [실행문 for if]
# 1~10 -> 2의 배수 추출 -> i*2 -> list 저장
num = list(range(1,11))
lst2=[i*2 for i in num if i % 2 ==0]
print(lst2)output
[4, 8, 12, 16, 20]튜플
: 리스트랑 유사하지만 읽기 전용으로 원소를 수정하거나 삭제할 수 없고 리스트에 비해 처리속도가 빠르다는 차이점이 있다.
- 특징
순서 자료구조를 갖는 열거형객체 생성 가능
소괄호 안에 콤마를 이용해서 순서대로 값을 나열

값의 자료형은 숫자, 문자, 논리 등을 함께 사용할 수 있음
index를 이용해서 자료 참조할 수 있고 슬라이싱, 연결, 반복, 요소검사 등이 가능
읽기 전용이여서 값을 추가, 삽입 수정 삭제가 불가능
(1) 원소가 한 개인 경우
- 형식적으로 원소 뒤에 콤마를 붙여야 함
t=(10, )
print(t)output
(10,)(2) 원소가 여러 개인 경우
t2=(1,2,3,4,5,3)
print(t2)output
(1, 2, 3, 4, 5, 3)(3) 튜플 인덱스
print(t2[0],t2[1:4],t2[-1])output
1 (2, 3, 4) 3(4) 수정 불가
- 수정 삽입 하고 싶다면 리스트 자료형으로 변환해야함
ex)lst = list(t2)
t2[0]=10output
Traceback (most recent call last):
File "<pyshell#91>", line 1, in <module>
t2[0]=10
TypeError: 'tuple' object does not support item assignment(5) 요소 반복
for i in t2:
print(i, end=' ')output
1 2 3 4 5 3 (6) 요소 검사
if 6 in t2:
print('6 있음')
else:
print('6 없음')output
6 없음튜플 관련 함수
- 원소를 수정이나 삭제 작업이 불가능해서 지원하는 함수가 리스트에 비해서는 적다는 특징이 있음
(1) 튜플 자료형 변환
lst = list(range(1,6))
t3 = tuple(lst)
print(t3)output
(1, 2, 3, 4, 5)(2) 튜플 관련 함수
count(a)함수 = 원소 a의 개수를 반환받아서 출력
index(a)함수 = 원소 a의 위치를 받환받아서 출력하는 예문
print(len(t3), type(t3))
print(t3.count(3))
print(t3.index(4))output
5 <class 'tuple'>
1
34.2 자료구조 (리스트 내포, 튜플)
비순서 자료구조
: 리스트 처럼 칸막이로 구분되지 않고 공통의 영역에 값들이 적재된다
ex) set, dict 등의 클래스

셋 객체 (set)
: 여러개의 자료를 비순서로 적재하는 가변 길이 비순차 자료구조를 생성하는 클래스
중괄호 안에 콤마를 이용하여 원소를 구분함

중복을 허용 X, index 사용 X, 추가 삭제 및 집합 연산등이 가능함
(1) 중복 불가
s = {1,3,5,3,1}
print(len(s))
print(s)output
3
{1,3,5}(2) 요소 반복
for d in s:
print(d, end=' ')output
1 3 5(3) 집합 관련 함수
s2 = {3,6}
print(s.union(s2)) #합집합
print(s.difference(s2)) #차집합
print(s.intersection(s2)) #교집합output
{1, 3, 5, 6}
{1, 5}
{3}(4) 추가, 삭제 함수
s3 = {1,3,5}
print(s3)
s3.add(7)
print(s3)
s3.discard(3)
print(s3)output
{1, 3, 5}
{1, 3, 5, 7}
{1, 5, 7}딕트 (dict)
: set 클래스와 동일하게 공통의 영역에 원소들이 적제되지만 차이점은 key에 값을 저장하고 키를 통해서 값을 참조하는 형식이라는 것이다.
키는 중복이 허용되지 않고 , 값은 중복이 허용됨.
index 대신에 key를 이용해서 값을 참조함 !
원소 수정, 삭제 추가 등이 가능하다
(1) dict 생성방법 1
dic = dict(key1 = 100, key2=200, key3=300)
print(dic)output
{'key1': 100, 'key2': 200, 'key3': 300}(2) dict 생성방법 2
person = {'name':'이서연', 'age':21, 'address' : '수원시'}
print(person)
print(person['name'])
print(type(dic), type(person))output
{'name': '이서연', 'age': 21, 'address': '수원시'}
이서연
<class 'dict'> <class 'dict'>(3) 원소 수정, 삭제, 추가
#원소 수정
person['age']=45 #인덱스 쓸 때는 [] 쓰기
print(person)
#원소 삭제
del person['address']
print(person)
#원소 추가
person['pay']=350
print(person)output
{'name': '이서연', 'age': 45, 'address': '수원시'}
{'name': '이서연', 'age': 45}
{'name': '이서연', 'age': 45, 'pay': 350}- 요소 검사와 반복
(1) 요소 검사
print(person['age'])
print('age' in person)output
45
True(2) 요소 반복
for key in person.keys(): # key 넘김
print(key)
for v in person.values(): # value 넘김
print(v)
for i in person.items(): # (key,value) 넘김
print(i)output
name
age
pay
이서연
45
350
('name', '이서연')
('age', 45)
('pay', 350)-단어 출현 빈도수 구하기
: get()함수를 이용하여 단어 빈도수를 계산할 수 있다.
(1) 단어 데이터 셋
charset = ['abc','code','band','band','abc']
wc={} # 빈 셋(2) get()함수 이용 : key 이용해서 value 가져오기
charset 리스트 객체를 for문의 요소 반복으로 단어를 하나씩 key 변수로 넘겨 받음 -> 넘겨받은 단어를 wc의 키로 지정하고 get()함수를 이용해서 키에 해당하는 값을 꺼내옴 -> 이때 값이 없는 경우 0을 초기화 하고 1을 더해서 값을 만든다 or 값이 있는 경우(2회 이상 발견된 단어)에는 꺼내온 값+1을 더해서 단어를 카운트
for key in charset:
wc[key]=wc.get(key,0)+1
print(wc)output
{'abc': 2, 'code': 1, 'band': 2}4.3 자료구조 (자료구조 복제, 알고리즘)
자료구조 복제
: 객체의 주소를 복사하는 것
-얕은복사 : 객체의 주소를 그대로 넘겨주는 복사
-깊은복사 : 객체의 내용만 넘겨주는 복사
(1) 얕은 복사
name =['이서연','김지원','김소정']
print('name address = ', id(name))
name2 = name #주소 복사
print('name2 address = ',id(name2))
print(name)
print(name2)
#원본 수정
name2[0]='이서여니'
print(name)
print(name2)output
name address = 2495989439552
name2 address = 2495989439552
['이서연', '김지원', '김소정']
['이서연', '김지원', '김소정']
['이서여니', '이서', '김소정']
['이서여니', '이서', '김소정'](2) 깊은 복사
copy.deepcopy(name) = copy 모듈에서 제공하는 deepcopy() 함수에 의해서 name이 참조하고 있는 내용만 넘겨주는 형식으로 복사됨 (=name3이 참조하는 객체의 내용은 동일하지만 주소는 다름, 원본 객체의 원소가 수정되면 사본 객체의 원소는 변경X 왜냐? 서로 다른 주소를 참조하기 때문)
import copy
name3=copy.deepcopy(name)
print(name)
print(name3)
print('name address = ',id(name))
print('name3 address = ', id(name3))
#원본 수정
name[1]='이서'
print(name)
print(name3)output
['이서연', '김지원', '김소정']
['이서연', '김지원', '김소정']
name address = 2495989439552
name3 address = 2495989438272
['이서연', '이서', '김소정']
['이서연', '김지원', '김소정']알고리즘
: 어떤 문제를 해결하기 위한 일련의 절차 / 입력, 출력, 명백성, 유한성, 효과성을 만족해야함
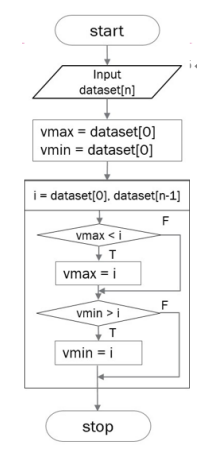
최댓값 & 최솟값
# 입력 자료 생성
import random
dataset=[]
for i in range(10):
r=random.randint(1,100)
dataset.append(r)
print(dataset)
#변수 초기화
vmax = vmin = dataset[0]
#최댓값/최솟값 구하기
for i in dataset:
if vmax<i:
vmax = i
if vmin>i:
vmin=i
#결과 출력
print('max = ', vmax, 'min = ',vmin)output
[68, 65, 3, 80, 77, 70, 63, 61, 70, 39]
max = 80 min = 3알고리즘 정렬 (algorithm sort)
: 전체 자료의 원소를 일정한 순서로 나열하는 알고리즘, 방식으로는 오름차순과 내림차순이 있음, 정렬 알고리즘은 선택정렬 (selection sort) , 버블정렬 (bubble sort) 등이 있음
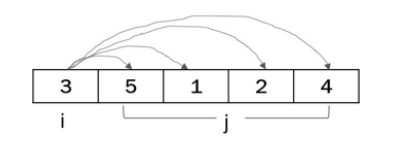
- 선택정렬 : 첫번째 원소를 기준으로 나머지 모든 원소를 비교하여 정렬하는 방식
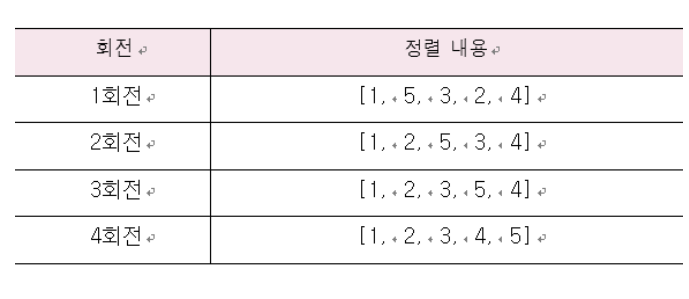
첫번째 원소를 변수 i로 지정 -> 나머지 원소를 변수 j로 지정 -> i변수는 기준 변수가 되고 j 변수는 비교 변수가 된다 -> 원소가 n개이면 n-1회전에 의해 모든 원소가 정렬됨
(1) 오름차순 정렬
기준 변수의 값과 비교변수의 값을 비교하여 기준변수의 값보다 더 작은 값이 나타나면 기준변수의 값과 비교변수의 값을 서로 교체한다
dataset = [3,5,1,2,4]
n=len(dataset)
for i in range(0,n-1):
for j in range(i+1,n):
if dataset[i]>dataset[j]:
tmp=dataset[i]
dataset[i]=dataset[j]
dataset[j]=tmp
print(dataset)
print(dataset)output
[1, 5, 3, 2, 4]
[1, 2, 5, 3, 4]
[1, 2, 3, 5, 4]
[1, 2, 3, 4, 5]
[1, 2, 3, 4, 5](2) 내림차순 정렬
기준 변수의 값과 비교변수의 값을 비교하여 기준변수의 값보다 더 큰 값이 나타나면 기준변수의 값과 비교변수의 값을 서로 교체한다
dataset=[3,5,1,2,4]
n=len(dataset)for i in range(0,n-1):
for j in range(i+1,n):
if dataset[i]<dataset[j]:
tmp=dataset[i]
dataset[i]=dataset[j]
dataset[j]=tmp
print(dataset)
print(dataset)output
[5, 3, 1, 2, 4]
[5, 4, 1, 2, 3]
[5, 4, 3, 1, 2]
[5, 4, 3, 2, 1]
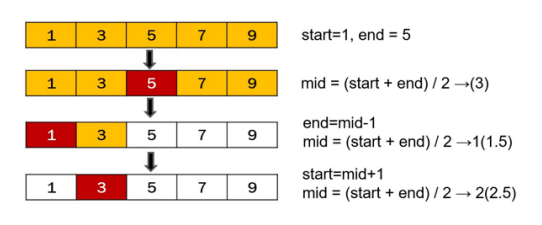
[5, 4, 3, 2, 1]이진 검색 (binary search)
: 전체 원소가 정렬된 상태에서 중앙 위치를 계산하여 절반은 버리고, 나머지 절반을 대상으로 검색을 수행하는 알고리즘

dataset = [5,10,18,22,35,55,75,103]
value = int(input('검색할 값 입력 : '))
low=0 #시작 위치
high=len(dataset)-1 #끝 위치
loc=0 # 찾은 값의 인덱스를 저장할 변수
state = False #값의 유무를 알려주는 상태 변수
while(low<=high):
mid = (low+high)//2
if dataset[mid]>value: #중앙값이 큰 경우
high=mid-1
elif dataset[mid]<value: # 중앙값이 작은 경우
low = mid+1
else: #찾은 경우
loc = mid
state=True
if state:
print('찾은 위치 : %d 번째'%(loc+1))
else:
print('찾는 값은 없습니다.')output
검색할 값 입력 : 55
찾은 위치 : 6번째
검색할 값 입력 : 16
찾는 값은 없습니다.5.1 모듈과 패키지 및 함수의 유형
모듈과 패키지
모듈은 다수의 함수나 클래스를 묶어서 파일형식 으로 제공함
패키지는 비슷한 유형의 모듈이 많은 경우 폴더 형태로 묶어서 꾸러미로 제공함
내장함수
: 모듈이나 패키지에서 제공되는 함수를 이용하려면 import 명령어를 이용해야함
import 안해도 되는 내장함수는 builtins라는 모듈에 의해 제공됨
import 모듈명 - 해당 패키지 또는 모듈이 포함하고 있는 모든 구성요소를 포함시키는 방식
from 모듈명 import 함수명1, 함수명2, ... - 해당 패키지 또는 모듈이 포함하고 있는 구성요소 중에서 특정 요소만 포함시키는 방식
(1) builtins 함수
dataset = list(range(1,6))
print(dataset)
print('len = ',len(dataset))
print('sum = ', sum(dataset))
print('max = ', max(dataset))
print('min = ', min(dataset))output
[1, 2, 3, 4, 5]
len = 5
sum = 15
max = 5
min = 1(2) import 함수
import statistics
from statistics import variance, stdev
print('평균 = ', statistics.mean(dataset))
print('중위수 = ', statistics.median(dataset))
print('표본 분산 = ',variance(dataset))
print('표본 표준편차 = ',stdev(dataset))output
평균 = 3
중위수 = 3
표본 분산 = 2.5
표본 표준편차 = 1.5811388300841898builtins 모듈
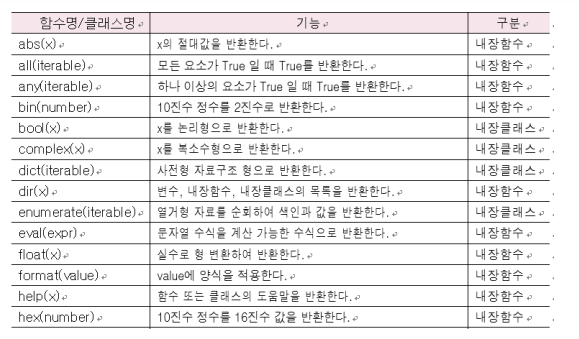


(1) abs(x)
abs(10)
10
abs(-10)
10(2) all(iterable)
all([1,True,10,-15.2])
True
all([1,True,0,10])
False
all([1,False,10,9])
False(3) any(iterable)
any([1,False,0,-15.2])
True
any([False,0,0])
False(4) bin(number)
bin(10)
'0b1010'
bin(15)
'0b1111'(5) dir(x)
x=[1,2,3,4,5]
dir(x)
['__add__', '__class__', '__class_getitem__', '__contains__', '__delattr__', '__delitem__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__getstate__', '__gt__', '__hash__', '__iadd__', '__imul__', '__init__', '__init_subclass__', '__iter__', '__le__', '__len__', '__lt__', '__mul__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__reversed__', '__rmul__', '__setattr__', '__setitem__', '__sizeof__', '__str__', '__subclasshook__', 'append', 'clear', 'copy', 'count', 'extend', 'index', 'insert', 'pop', 'remove', 'reverse', 'sort']
x.append(6)
x
[1, 2, 3, 4, 5, 6](6) eval(expr)
eval("10 + 20")
30
eval("20*30")+10
610(7) hex(number)
hex(10)
'0xa'
hex(15)
'0xf'
hex(64)
'0x40'(8) oct(number)
oct(10)
'0o12'
oct(7)
'0o7'
oct(8)
'0o10'(9) ord(character)
ord('0')
48
ord('9')
57
ord('A')
65(10) pow(x,y)
pow(10,2)
100
pow(10,3)
1000
pow(10,-1)
0.15.2 사용자 정의 함수
: 사용자가 직접 함수 내에 필요한 코드를 작성 해놓고, 외부의 값을 인수로 받아서 처리한 후 처리 결과를 반환하는 함수

(1) 인수가 없는 함수
def useFunc1():
print('인수가 없는 함수')
print('useFunc1')
useFunc1()output
인수가 없는 함수
useFunc1(2) 인수가 있는 함수
def userFunc2(x,y):
print('userFunc2')
z=x+y
print('z = ',z)
userFunc2(10,20)output
userFunc2
z = 30(3) return이 있는 하뭇
def userFunc3(x,y):
print('userFunc3')
tot=x+y
sub=x-y
mul=x*y
div=x/y
return tot,sub,mul,div
x=int(input('x 입력 : '))
y = int(input('y 입력 : '))
t,s,m,d=userFunc3(x,y) # 4개의 변수로 사칙연산의 결과를 순서대로 받아줌
print('tot = ',t)
print('sub= ',s)
print('mul = ',m)
print('div = ',d)output
x 입력 : 20
y 입력 : 10
tot = 30
sub= 10
mul = 200
div = 2.0산포도 구하기
산포도 : 평균으로부터 얼마나 값이 분산되어 있는지의 정도를 나타내는 처고돌 분산과 표준편차를 이용함
(1) 산술평균
from statistics import mean, variance
from math import sqrt
dataset = [2,4,5,6,1,8]
def Avg(data):
avg=mean(data)
return avg
print('산술평균 = ',Avg(dataset))output
산술평균 = 4.333333333333333(2) 분산/표준편차
def var_sd(data):
avg=Avg(data) #Avg() 함수 호출해서 산술평균 반환받기
diff = [(d-avg)**2 for d in data]
var = sum(diff)/(len(data)-1) # 표본 분산이 계산됨
sd = sqrt(var) #표준편차 = 분산의 제곱근
return var,sd
v,s = var_sd(dataset)
print('분산 = ',v)
print('표준편차 = ',s)output
분산 = 6.666666666666666
표준편차 = 2.581988897471611피타고라스 정리
: 직각삼각형의 세변의 길이에서 a^2+b^2=c^2의 관계가 성립한다는 이론
def pytha(s,t):
a=s**2-t**2
b=2*s*t
c=s**2+t**2
print('세 변의 길이 : ',a,b,c)
pytha(2,1)output
세 변의 길이 : 3 4 5몬테카를로 시뮬레이션
: 현실적으로 불가능한 문제의 해답을 얻기 위해서 난수의 확률분포를 이용하여 모의실험으로 근사적 해를 구하는 기법
ex) 동전을 1000번 던져서 앞면, 뒷면이 나올 확률을 구하는 거
(1) 단계 1 : 동전 앞면과 뒷면의 난수 확률분포 함수 정의
def coin(n):
result=[]
for i in range(n):
r = random.randint(0,1)
if(r==1):
result.append(1)
else:
result.append(0)
return result
print(coin(10))output
[0, 0, 0, 1, 1, 0, 1, 1, 1, 0](2) 단계 2 : 몬테카를로 시뮬레이션 함수 정의
def montaCoin(n):
cnt = 0
for i in range(n):
cnt +=coin(1)[0]
result = cnt/n
return result
print(montaCoin(10))
print(montaCoin(30))
print(montaCoin(100))
print(montaCoin(1000))
print(montaCoin(10000))output
0.6
0.2
0.42
0.516
0.49645.3 특수함수
: 특정한 문제의 해결 과정에서 요로 하는 함수를 의미
가변인수
: 하나의 매개변수로 여러개의 실수 인수를 받을 수 있는 거
여러개의 실인수를 하나의 매개변수로 받을 때 *매개변수는 튜플 자료구조로, **매개변수는 딕트 자료구조로 받음

(1) 튜플형 가변인수
def Func1(name,*names):
print(name)
print(names)
Func1("일서연",'이서연','삼서연')output
일서연
('이서연', '삼서연')(2) 통계량 구하는 함수
from statistics import mean, variance,stdev
def statis(func,*data):
if func == 'avg':
return mean(data)
elif func == 'var':
return variance(data)
elif func == 'std':
return stdev(data)
else:
return 'TypeError'
print('avg = ',statis('avg',1,2,3,4,5))
print('var = ', statis('var',1,2,3,4,5))
print('std = ',statis('std',1,2,3,4,5))output
avg = 3
var = 2.5
std = 1.5811388300841898(3) 딕트형 가변인수
def emp_func(name,age,**other):
print(name)
print(age)
print(other)
emp_func('이서연',21,addr = '수원시',height=169,weight=1000)output
이서연
21
{'addr': '수원시', 'height': 169, 'weight': 1000}람다 함수 (=인라인 함수)
: 정의와 호출을 한 번에 하는 익명함수
lambda 명령어 다음에 오는 매개변수에 의해서 외부의 값을 받고 : 다음에는 실행문의 실행결과가 반환됨

# (1) 일반 함수
def Adder(x,y):
add = x+y
return add
print('add = ',Adder(10,20))
# (2) 람다 함수
print('add = ',(lambda x,y : x+y)(10,20))output
add = 30
add = 30스코프 (scope)
: 변수가 사용되는 범위

(1) 지역 변수
x=50 # 전역변수
def local_func(x):
x+=50 # 지역변수
local_func(x)
print('x= ',x)output
x= 50(2) 전역 변수
def global_func():
global x # 전역변수 x 사용
x+=50 # x+50=100
global_func()
print('x = ',x)output
x = 1006.1 중첩함수
: 함수 내부에 또 다른 함수가 내장된 형태

일급함수와 함수클로저
일급힘수 : 중첩함수가 외부함수나 내부함수를 변수에 저장할 수 있는 특징
함수 클로저 : 내부함수가 외부함수의 return 명령문을 이용하여 반환하는 형태
(1) 일급함수
def a():
print('a 함수')
def b():
print('b 함수')
return b
b=a() # 외부함수 호출
b() # 내부함수 호출output
a 함수
b 함수(2) 함수 클로저
data=list(range(1,101))
def outer_func(data):
dataset=data # 값 1~100 생성
def tot():
tot_val=sum(dataset)
return tot_val
def avg(tot_val):
avg_val = tot_val/len(dataset)
return avg_val
return tot,avg
tot,avg = outer_func(data)
tot_val=tot()
print('tot = ',tot_val)
avg_val = avg(tot_val)
print('avg = ',avg_val)output
tot = 5050
avg = 50.5중첩함수 역할
from statistics import mean
from math import sqrt
data = [4,5,3.5,2.5,6.3,5.5]
# 산포도 함수
def scattering_func(data):
dataset = data
#산술평균 반환
def avg_func():
avg_val = mean(dataset)
return avg_val
#분산 반환
def var_func(avg):
diff = [(data - avg)**2 for data in dataset]
print(sum(diff))
var_val = sum(diff)/(len(dataset-1))
return var_val
#표준편차 반환
def std_func(var):
std_val = sqrt(var)
return std_val
#함수 클로저 반환
return avg_func, var_func, std_func
avg,var,std = scattering_func(data)
print('평균 = ',avg())
print('분산 = ',var(avg()))
print('표준편차 = ',std(var(avg())))output
평균 = 4.466666666666667
분산 = 1.9466666666666668
표준편차 = 1.39522996909709획득자, 지정자, nonlocal
획득자 함수 : 함수 내부에서 생성한 자료를 외부로 반환하는 함수, 반드시 return 명령문을 가짐
지정자 함수 : 함수 내부에서 생성한 자료를 외부에서 수정하는 함수, 반드시 매개변수를 가짐
nonlocal : 지정자 함수에서 내부 함수에서 외부함수의 변수를 사용할 경우 변수 앞에 붙여줘야하는 명령어

def main_func(num):
num_val = num #자료 생성
def getter(): #획득자 함수
return num_val
def setter(value): # 지정할 함수 ㅇㅣㄴ수가 있음
nonlocal num_val
num_val = value
return getter,setter
getter,setter = main_func(100) #num 생성
print('num = ',getter()) #획득한 num 확인
setter(200)
print('num = ',getter()) #num 수정 확인ㄴ setter를 이용해서 200으로 지정자 함수를 호출하면 외부 함수에서 만들어진 num_val의 값이 200으로 수정됨
output
num = 100
num = 200함수 장식자
: 기존 함수의 시작부분과 종료부분에 기능을 장식해서 추가해주는 별도의 함수를 의미
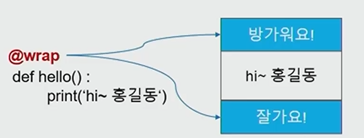
@함수명의 형태로 함수앞에 @기호를 붙여준다

def wrap(func):
def decorated():
print('방가워요!')
func() # 함수(hello)를 인수로 받는 매개변수
print('잘가요 !')
return decorated
@wrap
def hello():
print('hi ~ ',"이서연")
hello()output
방가워요!
hi ~ 이서연
잘가요 !6.2 재귀함수
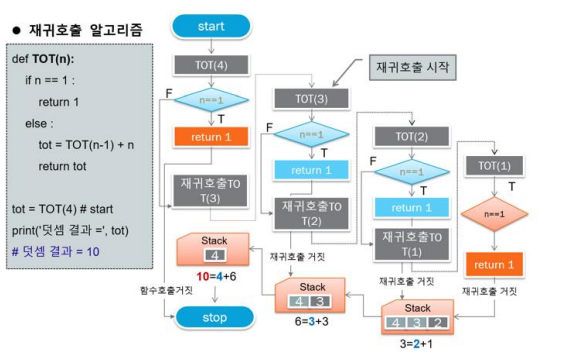
: 함수 내부에서 자신의 함수를 반복적으로 호출하는 함수를 의미, 재귀함수는 반복적으로 호출하기 때문에 반드시 함수 내에는 탈출 조건이 필수임
카운트
def counter(n):
if n==0:
return 0
else:
counter(n-1)
print('n = 0 : ',counter(0))
counter(5)output
n=0 : 0
1 2 3 4 5누적합
def adder(n):
if n==1:
return 1
else:
result = n+adder(n-1)
print(n,end=' ')
return result
print('n=1 : ',adder(1))
print('\nn=5 : ',adder(5))output
n=1 : 1
n=5 : 156.3 클래스와 객체
클래스 : 프로그램을 이용해서 객체를 만들어주는 역할 (속성과 행위로 구성)
ㄴ 변수와 함수들을 하나로 묶어놓은 집합체라고 볼 수 있음
객체 : 클래스에 의해서 만들어지는 결과물, 클래스의 속성에 실제 자료가 들어가고, 실제 자료를 동작시키는 함수가 하나로 묶여진 단위를 말함

(1) 함수
def calc_func(a,b):
x=a
y=b
def plus():
p=x+y
return p
def minus():
m=x-y
return m
return plus,minus
p,m = calc_func(10,20)
print('plus = ',p())
print('minus = ',m())output
plus = 30
minus = -10(2) 클래스
#클래스 정의
class calc_class:
#클래스 변수
x=y=0
#생성자
def __init__(self,a,b):
self.x=a
self.y=b
def plus(self):
p=self.x+self.y
return p
def minus(self):
m=self.x-self.y
return m
#객체 생성
obj=calc_class(10,20)
#멤버 호출
print('plus = ',obj.plus())
print('minus = ',obj.minus())output
plus = 30
minus = -10클래스 예시
class Car :
cc=0
door=0
carType=None
def __init__(self,cc,door,carType):
self.cc=cc
self.door=door
self.carType = carType
def display(self):
print('자동차는 %dcc이고 문짝은 %d개, 타입은 %s'%(self.cc,self.door,self.carType))
car1=Car(2000,4,"승용차")
car2=Car(3000,5,"SUV")
car1.display()
car2.display()output
자동차는 2000cc이고 문짝은 4개, 타입은 승용차
자동차는 3000cc이고 문짝은 5개, 타입은 SUV6.4 생성자
생성자
: init()이라는 이름으로 제공되고 객체가 생성될 때 자동으로 실행됨
객체 생성 시 멘버변수에 값을 초기화 하는 역할을 함

(1) 생성자 이용 멤버변수 초기화
class multiply:
x=y=0
def __init__(self,x,y): #생성자
self.x=x
self.y=y
def mul(self):
return self.x*self.y
obj=multiply(10,20)
print('곱셈 : ',obj.mul())output
곱셈 : 200(2) 메서드 이용 멤버변수 초기화
class multiply2:
x=y=0
def __init__(self): # 생성자 안씀
pass # 블록의 내용이 없는 경우 쓰는 명령어
def data(self,x,y): #객체 생성 + 멤버변수 초기화
self.x=x
self.y=y
def mul(self):
return self.x*self.y
obj=multiply2()
obj.data(10,20)
print('곱셈 = ',obj.mul())output
곱셈 = 200소멸자
: 생성자의 반대 역할을 하며 객체 사용이 완료되면 자동으로 실행되어 객체를 메모리에서 소멸시키는 역할
del self.x,del self.y
self
: 클래스를 구성하는 멤버들 즉, 멤버변수와 메서드를 호출하는 역할
(클래스의 생성자와 메서드는 기본적으로 self를 갖고 생략하면 오류가 발생함)

class multiply3:
# 멤버변수 없음
#생성자 없음
def data(self,x,y): #동적 멤버변수 생성/초기화
self.x=x
self.y=y
# 곱셈 연산
def mul(self):
result = self.x*self.y
self.display(result) #메서드 호출
# 결과 출력
def display(self,result):
print('곱셈 = %d'%(result))
obj = multiply3() # 기본 생성자
obj.data(10,20)
obj.mul()output
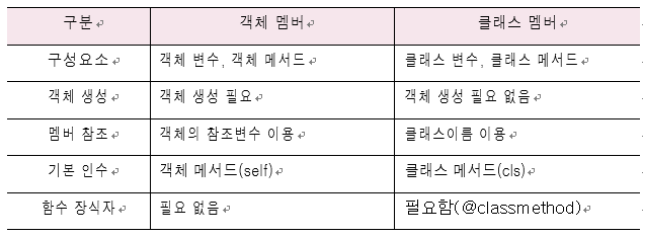
곱셈 = 200클래스 멤버
: 클래스 이름으로 호출하라 할수 있는 클래스 변수와 클래스 메서드를 말함
class DatePro:
content='날짜 처리 클래스' #(1) 멤버 변수
def __init__(self,year,month,day): #(2) 생성자
self.year = year
self.month=month
self.day=day
def display(self): #(3) 객체 메서드
print('%d-%d-%d'%(self.year,self.month,self.day))
# (4) 클래스 메서드
@classmethod # 함수 장식자
def date_string(cls,dateStr):
year = dateStr[:4]
month=dateStr[4:6]
day=dateStr[6:]
print(f'{year}년 {month}달 {day}일')
# (5) 객체 멤버
date = DatePro(1995,10,25) # 생성자
print(date.content)
print(date.year)
date.display()
# (6) 클래스 멤버
print(DatePro.content)
DatePro.date_string('19951025')output
날짜 처리 클래스
1995
1995-10-25
날짜 처리 클래스
1995년 10월 25일7.1 객체지향 기법
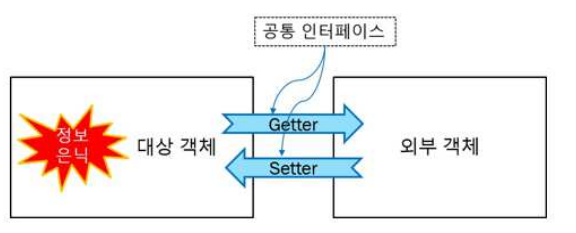
캡슐화
: 자료와 알고리즘이 구현된 함수를 하나로 묶고 공용 인터페이스만으로 접근을 제한하여 객체의 세부 내용을 외부로부터 감추는 기법
(1) __를 변수 앞에 넣으면 외부에서 접근이 불가능한 private변수가 됨
(2) 은닉 변수를 외부에서 접근할 수 있는 공용 인터페이스를 getter와 setter로 분류함
(3) getter는 외부에서 은닉된 값을 꺼내오는 메서드, setter는 외부에서 값을 수정하는 메서드
class Account:
# (1) 은닉 멤버 변수
__balance = 0 # 잔액
__accName = None # 예금주
__accNo= None # 계좌번호
# (2) 생성자 : 멤버변수 초기화
def __init__(self,bal,name,no):
self.__balance = bal
self.__accName = name
self.__accNo = no
# (3) 계좌 정보 혹인 : getter
def getBalance(self):
return self.__balance, self.__accName, self.__accNo
# (4) 입금하기 : setter
def deposit(self,money):
if money<0:
print('금액 확인')
return
self.__balance+=money
# (5) 출금하기
def withdraw(self,money):
if self.balance< money:
print('잔액 부족')
return
self.__balance-=money
# (6) object 생성
acc=Account(1000,'이서연','125-152-4125-41')
# (7) getter 호출
bal=acc.getBalance()
print('계좌 정보 : ',bal)
# (8) setter 호출
acc.deposit(10000)
bal=acc.getBalance()
print('계좌 정보 : ',bal)output
계좌 정보 : (1000, '이서연', '125-152-4125-41')
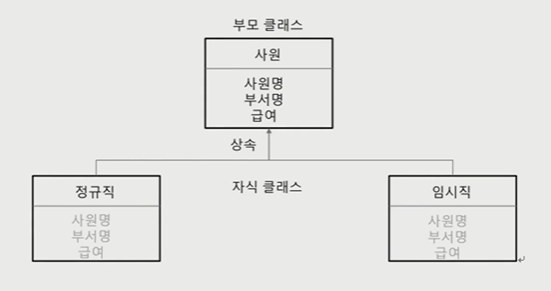
계좌 정보 : (11000, '이서연', '125-152-4125-41')상속
: 클래스 간의 계층적 관계를 구성하여 높은 수준의 코드 재사용성과 다형성의 문법적 토대를 마련할 수 있는 것
class Super:
def __init__(self,name,age):
self.name=name
self.age=age
def display(self):
print('name : %s, age = %d'%(self.name,self.age))
sup=Super("부모",55)
sup.display()
class Sub(Super):
gender = None
def __init__(self,name,age,gender):
self.name = name
self.age = age
self.gender = gender
def display(self):
print('name : %s , age = %d, gender = %s'%(self.name,self.age,self.gender))
sub = Sub('자식',25,'여자')
sub.display()ㄴ 원래 부모에서 상속받은 display는 name과 age 변수만 출력되도록 되어있으나 자식 클래스에서 추가한 gender 변수를 출력할 수 없기 때문에 상속받은 display() 메서드를 확장하여 3개의 멤버변수가 모두 출력되도록 재정의 함.
output
name : 부모, age = 55
name : 자식 , age = 25, gender = 여자super 클래스
: 자식 클래스에서 부모 클래스의 생성자를 호출하기 위해서 super 클래스를 제공함.

class Parent:
def __init__(self,name,job):
self.name=name
self.job=job
def display(self):
print('name : {}, job : {}'.format(self.name,self.job))
p=Parent('이서연','회사원')
p.display()
class Children(Parent):
gender = None
def __init__(self,name,job,gender):
super().__init__(name,job)
self.gender = gender
def display(self):
print('name : {}, job : {}, gender : {}'.format(self.name,self.job,self.gender))
c=Children('이서연','회사원','여자')
c.display()output
name : 이서연, job : 회사원
name : 이서연, job : 회사원, gender : 여자메서드 재정의
: 부모 클래스의 멤버변수가 자식 클래스로 상속되는 것 처럼 부모 클래스가 가지고 있는 메서드도 자식 클래스로 상속된다. 또한, 상속받은 메서드는 자식 클래스에서 다시 작성해서 사용할 수 있음.
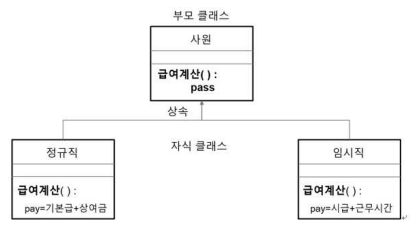
class Employee:
name = None
pay =0
def __init__(self,name):
self.name = name
def pay_calc(self):
pass
class Permanent(Employee):
def __init__(self,name):
super().__init__(name)
def pay_calc(self,base,bonus):
self.pay=base+bonus
print('총 수령액 : ',format(self.pay,'3, 총 수령액 : 3,200,000원d','원'))
class Temporary(Employee):
def __init__(self,name):
super().__init__(name)
def pay_calc(self,tplay,time):
self.pay=tpay*time
print('총 수령액 : ',format(self.pay,'3, 총 수령액 : 1,200,000원d'),'원')
p=Permanent('일서연')
p.pay_calc(3000000,200000)
t=Temporary('이서연')
t.pay_calc(15000,80)7.2 객체 지향 기법 (다형성, 내장클래스)
다형성
: 하나의 참조변수로 여러 타입의 객체를 참조할 수 있는 것 ( 부모 객체의 참조변수로 자식 객체를 다룰 수 있다는 의미가 객체지향에서의 다형성임)
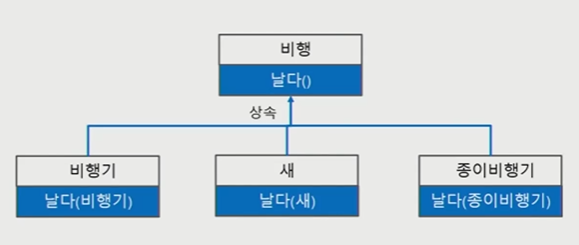
class Flight:
def fly(self):
print('날다, fly 원형 메서드')
class Airplane(Flight):
# 함수 재정의
def fly(self):
print('비행기가 날다')
class Bird(Flight):
def fly(self):
print("새가 날다")
class PaperAirplane(Flight):
def fly(self):
print('종이 비행기가 날다')
flight = Flight()
air = Airplane()
bird = Bird()
paper = PaperAirplane()
flight.fly()
flight = air
flight.fly()
flight=bird
flight.fly()
flight=paper
flight.fly()output
날다, fly 원형 메서드
비행기가 날다
새가 날다
종이 비행기가 날다내장클래스
: 라이브러리 형식으로 제공되는 클래스
import 명령어를 이용하여 모듈을 포함시켜야함. 하지만 builtins 모듈에서 제공하는 내장클래스는 import 없이 사용 가능하다

(1) date 클래스
import datetime
from datetime import date,time
today = date(2019,10,23)
print(today)
print(today.year)
print(today.month)
print(today.day)
w=today.weekday()
print('요일 정보 : ',w)output
2019-10-23
2019
10
23
요일 정보 : 2(2) time 클래스
currTime = time(21,4,30)
print(currTime)
print(currTime.hour)
print(currTime.minute)
print(currTime.second)
isoTime = currTime.isoformat()
print(isoTime)output
21:04:30
21
4
30
21:04:30(3) builtins 모듈 내장클래스
builtins 모듈의 enumerate 내장 클래스의 생성자를 이용하여 객체를 생성
ㄴ enumerate 내장클래스는 열거형 자료를 순회하여 인덱스와 값을 반환하는 객체를 생성함
#리스트 열거형 객체 이용
lst = [1,3,5]
for i,c in enumerate(lst):
print('인덱스 : ',i, end =', ')
print('내용 : ',c)output
인덱스 : 0, 내용 : 1
인덱스 : 1, 내용 : 3
인덱스 : 2, 내용 : 5#튜플 열거형 객체 이용
dit = {'name' : '이서연','job' : '회사원', 'addr':'수원시'}
for i,k in enumerate(dit):
print('순서 : ',i,end=', ')
print('키 : ',k,end =', ')
print('값 : ',dit[k])output
순서 : 0, 키 : name, 값 : 이서연
순서 : 1, 키 : job, 값 : 회사원
순서 : 2, 키 : addr, 값 : 수원시7.3 객체지향 기법 (패키지와 모듈)
패키지 = 관련있는 모듈들을 하나의 꾸러미 형태로 묶어주는 역할
모듈 = PyCharm에서 작성한 파이썬 파일들, 모듈 안에는 관련 함수와 클래스들로 구성되어있음 ex) '수학_통계.py'
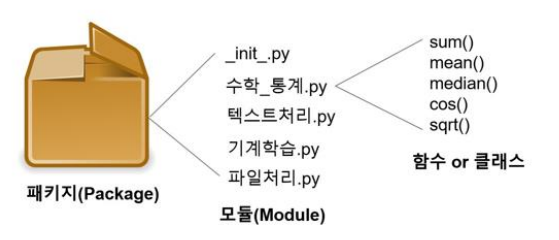
라이브러리 import

산포도 패키지는 산포도 모듈을 포함하고 있고, 산포도 모듈은 산포도의 통계를 구하는 분산과 표준편차를 계산하는 함수를 포함하고 있음 & 사용패키지는 사용모듈을 포함하고 있고 사용 모듈은 산포도 모듈의 분산과 표준편차 함수를 import 하여 사용하는 모듈임
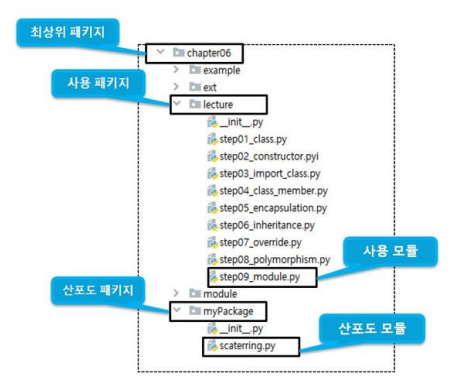
(1) 산포도 모듈
(산포도 : 평균을 중심으로 자료들이 얼마나 흩어져 있는지의 정도를 나타내는 용어/ 산포도가 클수록 많이 흩어져있고, 작을수록 평균을 중심으로 고루 분포되어있다는 의미)
from statistics import mean #평균 모듈
from math import sqrt # 제곱근 모듈
#산술평균 함수
def Avg(data):
avg=mean(data)
return avg
#분산/표준편차 함수
def var_sd(data):
avg=Avg(data)
diff=[(d-avg)**2 for d in data]
var=sum(diff)/(len(data)-1)
sd = sqrt(var)
return var,sd시작점(main)만들기

from statistics import mean
from math import sqrt
#산술평균 함수
def Avg(data):
avg=mean(data)
return avg
#분산/표준편차 함수
def var_sd(data):
avg=Avg(data)
diff=[(d-avg)**2 for d in data]
var = sum(diff)/(len(data)-1)
sd = sqrt(var)
return var,sd
data = [1,3,5,7]
print('평균 = ',Avg(data))
if __name == '__main__':
data=[1,3,5,7]
print('평균 = ','Avg(data))
var,sd=var_sd(data)
print('분산 = ',var)
print('표준편차 = ',sd)output
평균 = 4
분산 = 6.666666666666667
표준편차 = 2.5819888974716118.1 정규식 표현식
정규 표현식
: 특정한 규칙을 가진 문자열의 집합을 표현하는데 사용하는 형식 언어
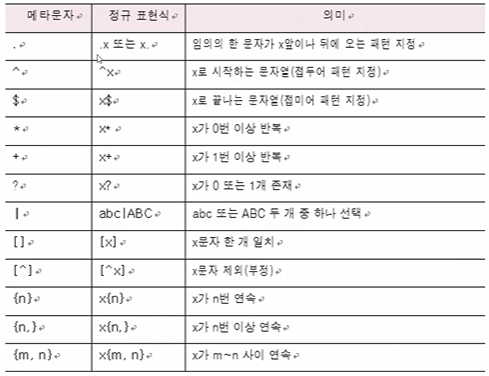
ex) 자연어를 대상으로 원하는 단어만 추출하기 위해서는 단어의 일정한 패턴이 있는데 이 패턴을 표준화된 텍스트 형식으로 나타낸 것 = 메타문자
메타문자
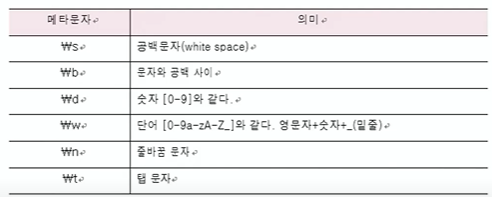
: 정규 표현식에서 일정한 의미를 가지고 있는 특수문자
정규 표현식 모듈
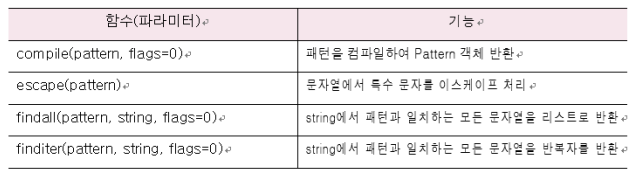
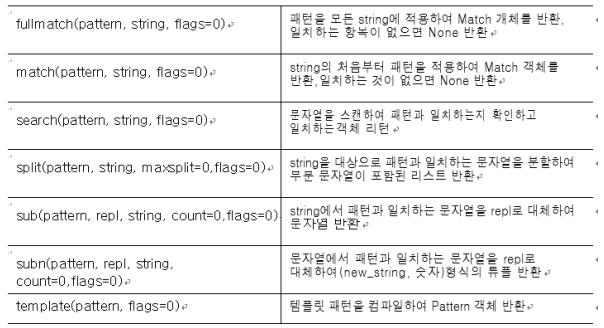
: 메타문자를 이용하여 패턴(정규표현식)을 만들고, 이러한 패턴을 특정 문자열에 적용하여 문자열을 처리할 수 있는 re모듈을 제공함
#1 문자열 찾기
: findall()함수가 패턴과 일치되는 문자열이 있으면 해당 문자열을 리스트로 반환하고 없으면 빈 리스트로 반환함

(1) 숫자 찾기
import re
from re import findall
st1 = '1234 abc이서연 ABC_555_6 이사도시'
print(findall('1234',st1))
print(findall('[0-9]',st1))
print(findall('[0-9]{3}',st1))
print(findall('[0-9]{3,}',st1)) # 3개 이상 연속된 경우
print(findall('\\d{3,}',st1))output
['1234']
['1', '2', '3', '4', '5', '5', '5', '6']
['123', '555']
['1234', '555']
['1234', '555'](2) 문자열 찾기
print(findall('[가-힇]{3,}',st1))
print(findall('[a-z]{3}',st1))
print(findall('[a-z|A-Z]{3}',st1))output
['이서연', '이사도시']
['abc']
['abc', 'ABC'](3) 특정 위치의 문자열 찾기
st2='test1abcABC 123mbc 45test'
print(findall('^test',st2)) # 접두어 test
print(findall('st$',st2)) #접미어 st
print(findall('.bc',st2)) #종료 문자 찾기
print(findall('t.',st2)) # 시작 문자 찾기output
['test']
['st']
['abc', 'mbc']
['te', 't1', 'te'](4) 단어 찾기
st3 = 'test^이서연 abc 대한*민국 123$tbc'
words = findall('\\w{3,}',st3)
print(words)output
['test', '이서연', 'abc', '123', 'tbc'](5) 문자열 제외
print(findall('[^^*$]+',st3))output
['test', '이서연 abc 대한', '민국 123', 'tbc']#2 문자열 검사
match() = 문자열에서 패턴과 일치하는 문자열이 있으면 객체를 반환하고 일치되는 문자열이 없으면 None을 반환

(1) 패턴이 같은 경우
from re import match
jumin = '123456-3234567'
result = match('[0-9]{6}-[1-4][0-9]{6}',jumin)
print(result)
<re.Match object; span=(0, 14), match='123456-3234567'>
if result:
print('주민번호 일치')
else:
print('잘못된 주민번호')output
주민번호 일치(2) 패턴이 다른 경우
jumin = '123456-5234567'
result = match('[0-9]{6}-[1-4][0-9]{6}',jumin)
print(result)
None
if result:
print('주민번호 일치')
else:
print('잘못된 주민번호')output
잘못된 주민번호#3 문자열 치환
sub() = 대상 문자열에서 패턴과 일치되는 문자열을 찾아서 다른 문자열로 치환하는 경우에 사용

(1) 특수문자 제거
from re import sub
st3 = 'test^이서연 abc 대한*민국 123$tbc'
text1=sub('[\^*$]+','',st3)
print(text1)output
test이서연 abc 대한민국 123tbc(2) 숫자 제거
text2=sub('[0-9]','',text1)
print(text2)output
test이서연 abc 대한민국 tbc8.2 텍스트 처리
: 자연어를 분석하기 위해 한글 문서나 영문문서를 대상으로 문장부호나 특수문자 등을 제거하는 과정
from re import split,match,compile
multi_line = """http://www.naver.com
http://www.daum.net
www.yiseonline.com"""
# 구분자를 이용하여 문자열 분리
web_site = split('\n',multi_line)
print(web_site)
# 패턴 객체 만들기
pat = complie('http://')
# 패턴객체를 이용하여 정상 웹 주소 선택하기
sel_site = [site for site in web_site if match(pat,site)] #match()함수는 string에서 pattern과 일치하는 문자열이 있으면 match 객체 반환, 없으면 None 반환
print(sel_site)output
['http://www.naver.com', 'http://www.daum.net', 'www.yiseonline.com']
['http://www.naver.com', 'http://www.daum.net']자연어 전처리
: 자연어를 대상으로 토픽분석이나 감성분석 등을 수행하기 위해서는 해당 문서를 전처리해야함.
(1) 소문자 변경
from re import findall,sub
texts = ['우리나라 대한민국, 우리나라%$만세','비아그&라500GRAM 정력 최고!', '나는 대한민국 사람','보험료 15000원에 평생 보장 마감 임박','나는 홍길동']
texts_rel = [t.lower() for t in texts] #lower 함수 = 영문자를 소문자로 변경시켜줌 (대문자 변경은 t.upper() 함수를 사용)
print('texts_rel : ',texts_rel)output
texts_rel : ['우리나라 대한민국, 우리나라%$만세', '비아그&라500gram 정력 최고!', '나는 대한민국 사람', '보험료 15000원에 평생 보장 마감 임박', '나는 홍길동'](2) 숫자 제거
# sub() 을 이용해서 숫자를 공백으로 치환
texts_re2 = [sub("[0-9]",'',text) for text in texts_rel]
print('texts_re2 :',texts_re2)output
texts_re2 : ['우리나라 대한민국, 우리나라%$만세', '비아그&라gram 정력 최고!', '나는 대한민국 사람', '보험료 원에 평생 보장 마감 임박', '나는 홍길동'](3) 문장 부호 제거
texts_re3 = [sub('[,.?!:;]','',text) for text in texts_re2]
print('texts_re3 : ',texts_re3)output
texts_re3 : ['우리나라 대한민국 우리나라%$만세', '비아그&라gram 정력 최고', '나는 대한민국 사람', '보험료 원에 평생 보장 마감 임박', '나는 홍길동'](4) 특수문자 제거 : re.sub() 이용
spec_str = '[@#$%^&*()]'
texts_re4=[sub(spec_str,'',text) for text in texts_re3]
print('texts_re4 : ',texts_re4)output
texts_re4 : ['우리나라 대한민국 우리나라만세', '비아그라gram 정력 최고', '나는 대한민국 사람', '보험료 원에 평생 보장 마감 임박', '나는 홍길동'](5) 영문자 제거
#findall()를 이용해서 영문자를 제외시키고 join()를 이용해서 문자들을 결함하여 단어를 만듬 ('우','리','나','라' -> '우리나라')
texts_re5 = [''.join(findall("[^a-z]",text)) for text in texts_re4]
print('texts_re5 : ',texts_re5)output
texts_re5 : ['우리나라 대한민국 우리나라만세', '비아그라 정력 최고', '나는 대한민국 사람', '보험료 원에 평생 보장 마감 임박', '나는 홍길동'](6) 공백 제거
#split()으로 한 칸 이상의 공백을 기준으로 문자열을 분리하고join()을 이용해서 공백 기준으로 결합
texts_re6 = [' '.join(text.split()) for text in texts_re5]
print('texts_re6 : ',texts_re6)output
texts_re6 : ['우리나라 대한민국 우리나라만세', '비아그라 정력 최고', '나는 대한민국 사람', '보험료 원에 평생 보장 마감 임박', '나는 홍길동']전처리 함수
- 텍스트 전처리
from re import findall,sub
texts = ['우리나라 대한민국, 우리나라%$만세','비아그&라500GRAM 정력 최고!', '나는 대한민국 사람','보험료 15000원에 평생 보장 마감 임박','나는 홍길동']
def clean_text(text):
texts_re = text.lower()
texts_re2 = sub('[0-9]','',texts_re)
texts_re3 = sub('[,.?!;:]','',texts_re2)
texts_re4 = sub('[@#$%^&*()]','',texts_re3)
texts_re5 = sub('[a-z]','',texts_re4)
texts_re6 = ' '.join(texts_re5.split())
return texts_re6
texts_result = [clean_text(text) for text in texts]
print(texts_result)output
['우리나라 대한민국 우리나라만세', '비아그라 정력 최고', '나는 대한민국 사람', '보험료 원에 평생 보장 마감 임박', '나는 홍길동']8.3 예외 처리
: 프로그램이 처리되는 동안 특정한 문제가 일어났을 때 프로그램이 중단되지 않도록 하는 특별한 처리
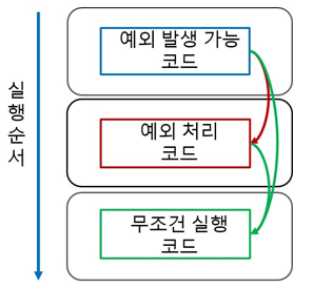
예외 처리 프로그램 로직은 try~except~finally 블록을 제공함
try : 예외가 발생할 가능성이 있는 코드를 작성하는 영역
except : 예외가 발생할 경우 예외를 적절하게 처리하는 코드를 작성하는 영역
finally : 예외와 상관없이 무조건 처리할 코드를 작성하는 영역 (생략 가능)

(1) 예외 발생 코드
print('프로그램 시작 !!!')
x=[10,30,25.2,'num',14,51]
for i in x :
print(i)
y=i**2
print('y= ',y)
print('프로그램 종료')output
프로그램 시작 !!!
10
y= 100
30
y= 900
25.2
y= 635.04
num
Traceback (most recent call last):
File "<pyshell#133>", line 3, in <module>
y=i**2
TypeError: unsupported operand type(s) for ** or pow(): 'str' and 'int'
프로그램 종료(2) 예외 처리 코드
print('프로그램 시작 !!!')
for i in x :
try :
y=i**2 # 예외 발생
print('i= ',i,', y = ',y)
except:
print('숫자 아님 ; ',i)
print('프로그램 종료')output
프로그램 시작 !!!
i= 10 , y = 100
i= 30 , y = 900
i= 25.2 , y = 635.04
숫자 아님 ; num
i= 14 , y = 196
i= 51 , y = 2601
프로그램 종료다중 예외처리
: try 블록에서 여러 유형의 예외가 발생할 경우 각 유형별로 예외를 처리하기 위해서 여러개의 except 블록 지정 가능하다
except 예외 처리 클래스 as 변수 = except는 except 다음에 예외를 처리할 수 이는 클래스와 as 다음에 예외 정보를 저장할 수 있는 참조 변수를 지정할 수 있음
print('\n유형별 예외처리')
try :
div = 1000/2.53
print('div = %5.2f'%(div))
div = 1000/0
f = open('c:\\test.txt')
print('num = ',num)
# 다중 예외처리 클래스
except ZeroDivisionError as e: # 산술적 예외 처리
print('오류 정보 : ',e)
except FileNotFoundError as e: # 파일 열기 예외 처리
print('오류 정보 : ',e)
except Exception as e: # 기타 예외 처리
print('오류 정보: ',e)
finally:
print('finally 영역 - 항상 실행되는 영역')output
유형별 예외처리
div = 395.26
오류 정보 : division by zero
finally 영역 - 항상 실행되는 영역8.4 텍스트 파일
: 텍스트 파일을 대상으로 텍스트 자료를 읽어오는 방법 & 읽어온 자료를 처리하고 처리결과를 파일에 저장하는 방법 알아보기
텍스트 파일 입출력
: 텍스트파일을 읽고 쓰려면 io 모듈에서 open()함수를 이용해야함

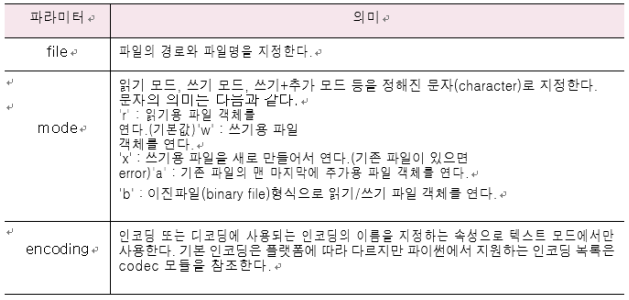
import os
print('\n현재 경로 : ',os.getcwd()) #getcwd() = 현재 기본 작업 디렉토리 확인시켜주는 함수
현재 경로 : C:\Users\pc\AppData\Local\Programs\Python\Python311
try : 3 파일 입출력 관련 코드 작성
ftest1 = open('chapter08\data\ftest2.txt', mode = 'r') # 파일 읽기
print(ftest1.read()) # 파일 전체 읽기
ftest2 = open('chapter08\data\ftest2.txt', mode = 'w') # 파일 쓰기
ftest2.write('my first text ~~~')
ftest3 = open(chapter08\data\ftest2.txt', mode = 'a') # 파일 쓰기 + 내용 추가
ftest3.write('\nmy second text ~~~')
except Exception as e : # 입출력 과정에서 발생되는 예외를 처리하는 코드 작성
print('Error 발생 : ',e)
finally : # 파일 입출력을 위해 생성된 객체를 닫는 코드 작성
ftest1.close() #파일 객체 닫기
ftest2.close()
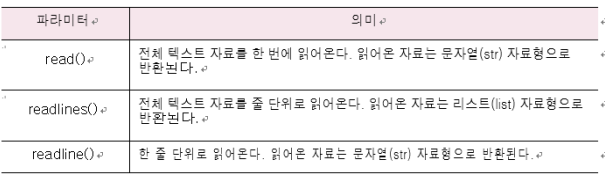
ftest3.close()텍스트 자료 읽기
읽기 모드 (mode = 'r')로 객체 생성하면 아래의 함수가 제공됨
try:
ftest = open('C:/Users/pc/Desktop/ftest.TXT',mode = 'r')
full_text = ftest.read()
print(full_text)
print(type(full_text))
ftest = open('C:/Users/pc/Desktop/ftest.TXT',mode = 'r')
lines = ftest.readlines()
print(lines)
print(type(lines))
print('문단 수 : ',len(lines))
print(lines.strip())
docs.append(lines.strip())
print(docs)
ftest = open('C:/Users/pc/Desktop/ftest.TXT',mode = 'r')
line = ftest.readline()
print(line)
print(type(line))
except Exception as e:
print('Error 발생 : ',e)
finally:
ftest.close()ㄴread() : 전체 텍스트 자료 읽기
readlines() : 전체 텍스트 줄 단위 읽기
strip() : x변수의 문자열 끝 부분에 오는 이스케이프 문자를 제거하는 예문
output
programming is fun
very fun!
have a good time
mouse is input device
keyboard is input device
computer is input output system
<class 'str'>
['programming is fun\n', 'very fun!\n', 'have a good time\n', 'mouse is input device\n', 'keyboard is input device\n', 'computer is input output system']
<class 'list'>
문단 수 : 6
Error 발생 : 'list' object has no attribute 'strip'with 블록과 인코딩방식
: with 명령어를 이용해서 블록 형식으로 파일 객체 생성 & 인코딩 방식을 지정하여 텍스트 파일을 작성하는 방법 알아보기

ㄴ with 블록을 이용하여 파일 객체 생성
try :
with open('C:/Users/pc/Desktop/ftest.TXT',mode = 'w',encoding = 'utf-8') as ftest: # 텍스트 파일을 쓰기 모드로 파일 객체를 생성하고 인코딩방식(utf-8)을 파라미터로 지정
ftest.write('파이썬 파일 작성 연습')
ftest.write('\n파이썬 파일 작성 연습2')
with oepn('C:/Users/pc/Desktop/ftest.TXT',mode = 'r',encoding='utf-8') as ftest: # 동일한 파일을 대상으로 읽기모드와 인코딩 파라미터를 이용하여 파일 객체를 생성
print(ftest.read()) # 파일에 저장된 두 줄의 한글 텍스트가 출력
except Exception as e :
print('Error 발생 : ',e)
finally: # with블록을 벗어나면 자동으로 객체가 소멸돼서 finally 블록의 내용을 생략함
passoutput
12
14
Error 발생 : name 'oepn' is not definedwith 블록을 이용하면 블록 내에서 참조변수를 이용하여 파일 객체를 사용할 수 있고, 블록을 벗어나면 자동으로 객체가 close된다.
9.1 파일 시스템
: 파일로 부터 자료를 읽고 쓰려면 운영체제에서 지원하는 파일 시스템의 도움을 받아야함
파일과 디렉토리 관련 함수
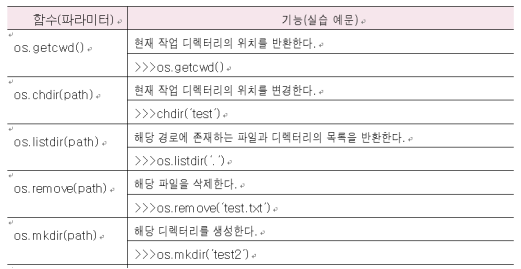

import os.path #파일 경로를 조작하는 모듈
os.getcwd() # 현재 경로 확인
os.chdir('chapter08') # 경로 변경
os.getcwd()
# lectue 디렉토리의 step01_try_except.py의 파일 절대 경로
os.path.abspath('lecture/step01_tr_except.py')
#step01_try_except.py 파일의 디렉토리 이름
os.path.dirname('lecture/step01_try_except.py')
# workspace 디렉토리 유무 확인
os.path.exists('D:\\Pywork\\workspace')
#step01_try_except.py 파일 유무 확인
os.path.isfile('lecture/step01_try_except.py')
#lecture 디렉토리 유무 확인
os.path.isdir('lecture')
# 디렉토리와 파일 분리
os.path.split('c:\\test\\test1.txt')
# 디렉토리와 파일 결합
os.path.join('c:\\test','test1.txt')
#step01_try_except.py 파일 크기
os.path.getsize('lecture/step01_try_except.py')glob 모듈
: 유닉스 셀이 사용하는 규칙에 의해서 지정된 패턴과 일치하는 모든 파일과 디렉토리의 목록을 반환하는 관련 함수들을 제공하는 모듈 (특수문자를 이용해서 패턴 저장 가능)
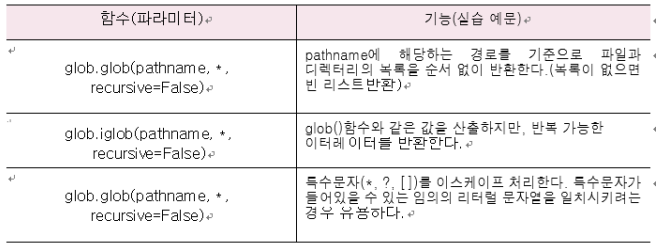
#프롬포트에서 glob()함수와 특수문자를 패턴으로 지정하여 파일의 목록을 반환
import glob
>>>glob.glob('test*.py') # 현재 경로에서 test로 시작하는 모든 목록 반환
>>>glob.glob('c:/test[0-9]') # test 문자열 다음에 숫자 1개가 오는 목록 반환
['c:/test1','c:/test9']
>>>glob.glob('c:/test[0-9]/*.txt') # test1, test9 디렉토리에 포함된 *.txt 파일 반환
['c:/test1\\1.txt.txt','f:/test1\\test.txt.txt','f:/test9\\10.jpg.txt']
>>>glob.glob('c:test[0-9]/[0-9].*') # test1, test9 디렉토리에서 숫자 1개 파일 반환
['c:/test1\\1.txt.txt']
>>>glob.glob('c:/test1/*.txt') # test1 디렉토리에서 *.txt 파일 반환
['c:/test1\\1.txt.txt','c:/test1\\test.txt.txt']
>>glob.glob('c:/test1/?.txt') # test1 디렉토리에서 파일명이 1자인 txt 파일 반환
['c:/test1\\1.txt']
>>>glob.glob('c:/test1/*.txt',recursive=True # .txt 파일을 내림차순 정렬하여 반환
['c:/test1\\1.txt','c:/test1\\test.txt']마무리
: 6월 26일 ~ 7월 12일 까지 한 2주 반? 동안 강의랑 피피티를 보면서 정리를 해보았다 ! 원래는 이게 11.5 까지 있는 40강 짜리인데 나는 30강에서 마무리 하려한다. 왜냐하면!! 뒤로 갈수록 파일쪽을 건드리고 마지막엔 패키지 다운, 데이터베이스 까지 나오는데 아무래도 같이 따라하는 실습형 강의가 아니다 보니 내 컴퓨터의 파일 경로랑 맞지 않아서 직접 코딩을 해도 에러가 너무 나고 결과물 출력이 어렵기 때문이다 ㅠㅠ
이제는 여태까지 배웠던 파이썬을 바탕으로 신찬수교수님 자료구조 강의 -> 알고리즘 강의 순으로 개강때 까지 공부할 것 같고 이 역시 벨로그에 적어야겠당 아 그리고 저 강의들을 들으면서 한두시간 정도는 머신러닝 쪽을 공부해볼 생각이당 ~~ 기대된다 !!
