Summary
- 4-layers LSTM을 사용해서 기존 RNN의 단점을 최소화 했다.
- Input/Output LSTM을 사용해서 (인코딩-디코딩) 도메인에 자유로움을 부여했다.
- Input Sequence의 단어의 순서를 바꿈으로써 정확도를 향상시켰다.
기존의 Deep Learning의 Input size가 고정되 것을 극복하기 위해 LSTM을 활용했다는 것이 특징이다.
-
기존 DNN의 한계점 : sequence와 sequence를 매핑하는데 사용할 수 없음
-
이 논문에서는 문장 구조에 대한 최소한의 가정만 하는 sequence learning에 관한 end-to-end approach를 제시한다.
입력 문장을 고정된 차원의 벡터로 매핑하기 위해 multilayered LSTM을 사용함
벡터를 target 문장으로 decode하기 위해 multilayered LSTM을 사용함
-
Translation task (WMT-14 dataset)에서 34.8 BLUE score를 기록하였다. 이와 반대로, phrase-base SMT system에서는 33.3으로 보다 낮은 score를 보였다.
-
LSTM은 long sentences에 RNN에 비해 좋은 성능을 보여준다.
-
입력 문장의 순서를 역순으로 바꾸어 학습하는 것이 성능이 훨씬 뛰어나다. 그렇게 함으로써 입력 문장과 target 문장 사이의 많은 short term dependencies를 도입하여 최적화 문제를 더 쉽게 만들었다.
Introduction
- DNN은 speech recognition 등 어려운 문제에 대해 뛰어난 성능을 보이는 ML model이다.
- step에서의 병렬 계산, 오직 2개의 은닉층을 사용하여 NxN bit 수 계산 등 강력한 힘을 보여줌
- labeled training dataset이 network 매개변수를 지정하는데 충분하다면, large DNN은 supervised backpropagation으로 학습시킬 수 있다.
- Fixed 된 Input size는 항상 걸림돌이 된다.
- 이를 위해서 LSTM 을 제시했다.
LSTM
자세한 설명은 다음 링크를 참조하도록 한다.
architecture
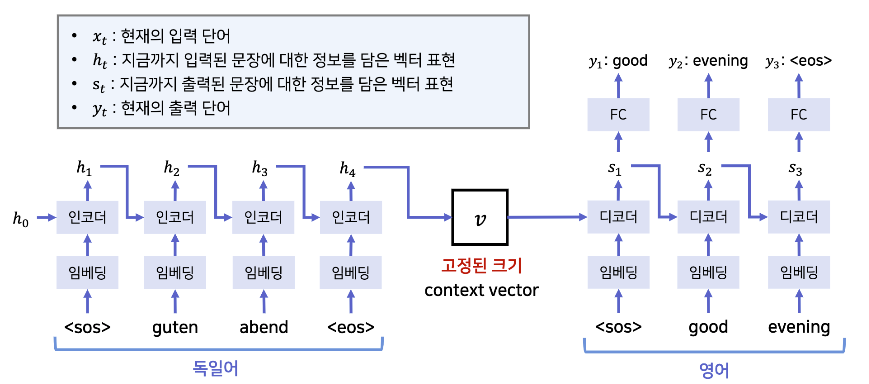
- 위에서 언급한 LSTM의 셀이 인코더에 해당한다고 생각하면 된다.
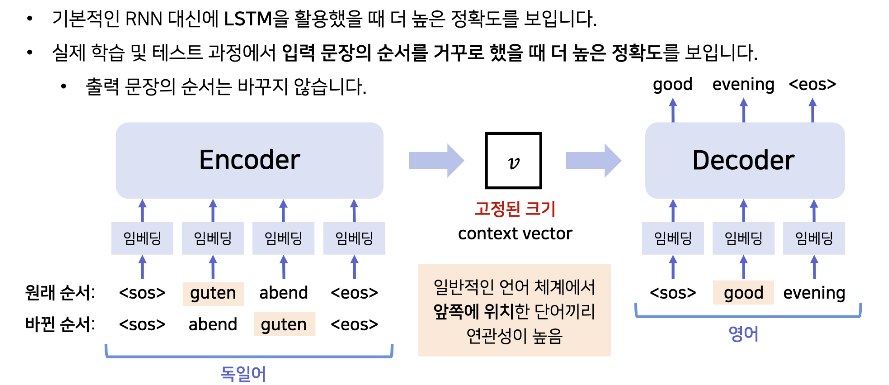
- 학습할 떄는 바뀐 순서로 학습을 해서 먼저 나오는 단어들에 대해 더 민감하게 반응 할 수 있도록 한다.
- RNN 의 경우 결국 순차적인 단어의 순서를 서로 학습 과정에서 영향을 줘서 context vector를 찾는 것으로 이해했고, 결국 마지막에 사용된 단어들 위주로 먼저 input으로 넣어줌으로 써, 더욱 근접한 context vector가 나올 수 있도록 하는 것으로 이해하면 좋을 것 같다.
Experiment
WMT' 14 English to French dataset
프랑스어 348억개, 영어 340억개 단어로 구성된 12M (1,200만) 문장들로 모델을 훈련함
Decodeing and Rescoring
- 목적함수는 log(p(T / S))를 활용한다.
- 여기서 T는 타겟, S는 SOURCE SENTENCE로 이해하면 된다.
- 가장 확률이 높은 translation을 찾는데 간단한 left-to-right beam search decoder를 사용한다.
- Beam search이란?
Greedy Decoding 방식은 단순하게 해당 시점에서 가장 확률이 높은 후보를 선택하는 것이다. 예를 들어, 특정 시점 t에서의 확률분포 상에서 상위 1등과 2등의 확률 차이가 작든 크든, 무조건 가장 큰 1등에게만 관심이 있을 뿐이다. 이러한 예측에서 한 번이라도 틀린 예측이 나오게 된다면, 이전 예측이 중요한 디코딩 방식에서는 치명적인 문제가 된다.
Beam Search는 Greedy Decoding 방식의 단점을 보완하기 위해 나온 방식이다. 빔서치는 해당 시점에서 유망한 빔의 개수만큼 골라서 진행하는 방식이다.
start 토큰이 입력되면 이를 바탕으로 나온 예측값의 확률 분포 중 가장 높은 확률 K개를 고른다. 이제부터 이 K개의 갈래는 각각 하나의 빔이 된다. K개의 빔에서 각각 다음 예측값의 확률 분포 중 가장 높은 K개를 고른다. K개의 빔에서 다음 예측값의 확률 분포 중 가장 높은 K개(자식 노드)를 고른다. 총 K^2개의 자식 노드 중 누적확률 순으로 상위 K개를 뽑는다.
- Beam search이란?
Conclusion
- 입력 문장 순서를 바꾸는 트릭으로 성능을 향상시켰다.
- LSTM 활용을 하여 디코더 인코더를 설계했다.

Mechanical & Computer Science