처리율 제한 장치(Rate Limiter) 란?
- 클라이언트 또는 서비스가 보내는 처리율(rate)를 제어하기 위한 시스템
⇒ API 요청 횟수가 제한 장치에 정의된 임계치(threshold)를 넘어서면 추가로 도달한 모든 호출은 처리가 중단 (HTTP 인 경우 상태 코드 429를 반환)
사용이유?
- DoS(Denial of Service) 공격에 의한 자원 고갈(resource starvation)을 방지
⇒ 대형 IT 기업들은 필수로 API에 Rate Limiter 를 구현 - 비용을 절감 (서버 자체 + API 호출 비용)
- 우선순위 높은 API에 더 많은 자원을 할당 가능
- 서버 과부하 방지
ex) 봇(bot)에서 오는 트래픽 방지, 사용자의 잘못된 이용패턴으로 유발된 트래픽 방지
Rate Limiter 위치 고려
- Client쪽 (X) : 클라이언트 요청은 쉽게 위변조가 가능하기 때문에 구현하지 않는다(개발자도구)
- Server (O)
- MiddleWare (O) : 마이크로 서비스인 경우, API 게이트웨이 컴포넌트에 구현한다
💡 카운터는 보통 메모리상에서 동작하는 캐시에 보관, 일례로 Redis는 처리율 제한 장치를 구현할 때 자주 사용
Rate Limiter 동작 순서
- 작업 프로세스 (workers)는 수시로 처리율 제한 규칙을 디스크에서 읽어 캐시에 저장
- 클라이언트가 요청을 보내면, 요청은 먼저 Rate Limiting Middleware에게 도달
- Middleware는 제한 규칙을 캐시에서 가져온다
- 카운터 및 마지막 요청의 타임 스탬프를 Redis에서 가져온다
- 제한 규칙과 카운터 및 타임 스탬프를 확인한다
5.1 해당 요청이 처리율 제한에 걸리지 않았으면 API 서버로 전달
5.2. 해당 요청이 처리율 제한에 걸렸다면, 429 too many requests 에러를 client에게 응답(버리거나, 메시지 큐에 저장할 수 있음)
분산 환경에서 Rate Limiter 구현
-
경쟁 조건(race condition)
- 일반적인 해결책은 락(lock)이지만, 시스템의 성능을 상당히 떨어뜨린다는 문제가 있음
- Redis에서는 루아 스크립트(Lua script)와 정렬 집합(sorted set) 자료구조를 사용 -
동기화(synchronization)
- 수백만 사용자를 지원하려면 Rate Limiter 서버가 여러 대 필요
⇒ Redis 와 같은 중앙 집중형 데이터 저장소 사용 -
성능 최적화
1) 데이터센터에서 멀리 떨어지면 지연시간(latency) 증가
⇒ 세계 곳곳에 에지 서버(edge server)를 두고, 사용자 트래픽을 가까운 에지 서버로 전달
2) 최종 일관성 모델 사용
Rate Limiting Algorithm
토큰 버킷 알고리즘
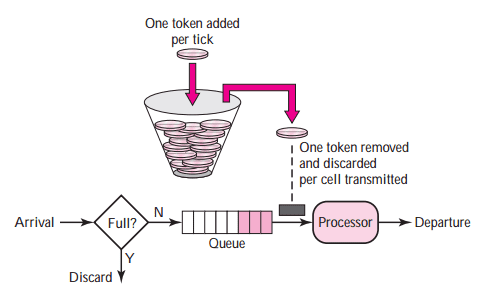
-
IT 기업들이 보편적으로 사용
-
보통 API 엔드포인트마다 별도의 버킷을 둠
ex) 사용자마다 하루에 한 번만 포스팅 + 친구 150명까지 추가 가능 + 좋아요 버튼 5번까지 가능
→ 사용자마다 3개의 버킷 -
장점
- 구현이 쉬움
- 메모리 사용량 측면에서 효율적
- 짧은 시간에 집중되는 트래픽도 처리 가능
(버킷에 남은 토큰만 있으면 요청은 시스템에 전달)
-
단점
- 버킷 크기와 토큰 공급률이라는 두 개 인자를 적절하게 튜닝하는 것이 어려움
-
동작 알고리즘
- 버킷이 있고, 사전 설정된 양의 토큰이 주기적으로 채워짐
(버킷이 가득 차면 새로 추가된 토큰은 삭제)- 요청이 도착하면 버킷에 충분한 토큰이 있는지 확인.
각 요청은 처리될 때마다 하나의 토큰을 사용
2.1) 토큰이 충분한 경우, 버킷에서 토큰을 하나 꺼낸 후 요청을 시스템에 전달
2.2) 토큰이 없는 경우, 해당 요청은 버려짐누출 버킷 알고리즘
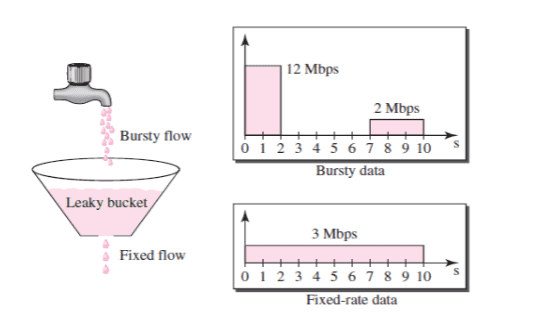
-
요청 처리율이 고정
-
FIFO 큐로 구현
-
장점
- 메모리 사용량 측면에서 효율적
- 고정된 처리율을 갖고 있기 때문에 안정된 출력이 필요한 경우 적합
-
단점
- 짧은 시간에 트래픽이 몰려서 큐가 가득차면, 최신 요청들은 버려짐
- 버킷 크기와 처리율이라는 두 개 인자를 적절하게 튜닝하는 것이 어려움
-
동작 알고리즘
- 요청이 도착하면 큐가 가득차 있는지 확인
1.1) 큐가 가득 차 있으면 해당 요청은 버려짐
1.2) 큐에 빈 자리가 있으면 큐에 요청을 추가 - 지정된 시간마다 큐에서 요청을 꺼내서 처리
- 요청이 도착하면 큐가 가득차 있는지 확인
고정 윈도우 카운터 (FIXED WINDOW COUNTER)
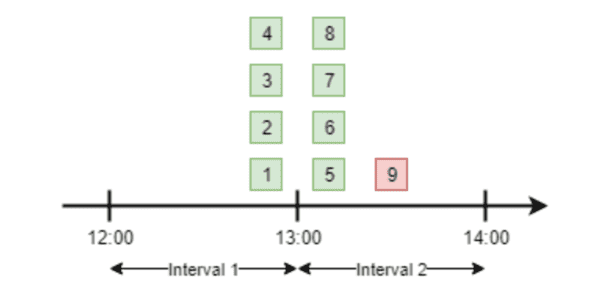
-
타임라인을 고정된 간격의 윈도우로 나눔
-
장점
- 메모리 효율이 좋음
- 이해하기 쉬움
- 윈도가 닫히는 시점에 카운터를 초기화하는 방식은 특정한 트래픽 패턴을 처리하기에 적합
ex) 매 시간 선착순 100명 이벤트
-
단점
- 윈도우 경계 부근에서 트래픽이 몰리면, 설정 허용 한도의 2배까지 시스템이 요청 받을 수 있음
-
동작 알고리즘
- 타임라인을 고정된 윈도우로 나누고, 각 윈도우마다 카운터를 붙임
- 요청이 접수될 때마다 카운터의 값을 1씩 증가
- 카운터의 값이 사전에 설정된 임계치(threshold)에 도달하면, 새로운 요청은 새로운 윈도우가 열릴 때까지 버려짐
이동 윈도우 로깅
- 요청 받은 시간을 기준으로 근접한 시간을 계산해서 요청 건수를 확인 후, 정해진 요청 건수를 넘으면 요청이 거부
이동 윈도우 카운터
- 고정 윈도 카운터 알고리즘 + 이동 윈도 로깅 알고리즘

Mechanical & Computer Science