2강 내용 정리

고등학교 1학년 수학과목에 함수란 단어를 처음 봤을때가 생각이 난다. 선생님께서 함수란 무엇인가? 라는 질문을 하셨고, 무수히 많은 학생들은 학원 또는 인강에서 배운대로 정의를 읊었다. 결국 선생님이 원하셨던 정답은 관계(식) 이었다. 즉 우리가 어떠한 input 을 넣었을 때, 특정 output이 나오는 것, 그것을 함수라고 정의 내릴 수 있다고 했다.
이미지 분류도 그러한 함수를 복잡한 알고리즘을 통해 학습 및 정의내리는 것으로 이해하면 된다. 그러면 2강에서 핵심은 끝이 난다. 위 그림에서 이미지를 input으로 넣엇을때, 정확히 Cat이라고 분류해 낼 수 있다면 훌륭한 함수의 역할을 하는 알고리즘을 개발했다고 할 수 있다.
사람은 위 과정을 쉽게 할 수 있지만 컴퓨터는 그렇지 못한다. 그 이유는 컴퓨터는 이것을 H x W x 3 와 같이 3차원의 배열로 인식하기 때문이다. 우리에게 3차원 배열을 주고 무엇인지 판단하라고 한다면 정확히 어떤 물체인지 인식하지 못할 것이다.
문제는 이것 뿐만이 아니다. 사진을 찍는 각도에 따라 숫자들이 변하기 마련이다. 아무리 같은 고양이사진을 찍어도 위, 아래, 좌, 우 등 여러 각도에 따라 숫자 배열이 천차 만별로 달라질테니 이는 더욱 어려운 과정임을 우리는 직접 확인해 보지 않아도 알 수 있다.
또한 조명에 문제, 고양이의 종류, 객체(고양이) 의 개체수, 배경 등 여러 문제들로 인해 이미지 분류문제는 쉽지 않다.

따라서 사람들은 데이터에 기반한 접근법 을 생각하게 된다. 결론부터 말하면 무수히 많은 사진들을 이용해 컴퓨터에게 정답을 알려주고, 이를 통해 과거에 학습했던 데이터를 바탕으로 우리가 원하는 고양이(정답) 인지 맞춰달라는 것이다. 이 해결책 또한 사실 우리 인간이 발달 과정에서 여러가지 배움을 터득하는 방법 중 한가지와 동일하다. 'Data Driven' 이라는 단어가 굉장히 익숙한 것 같다.
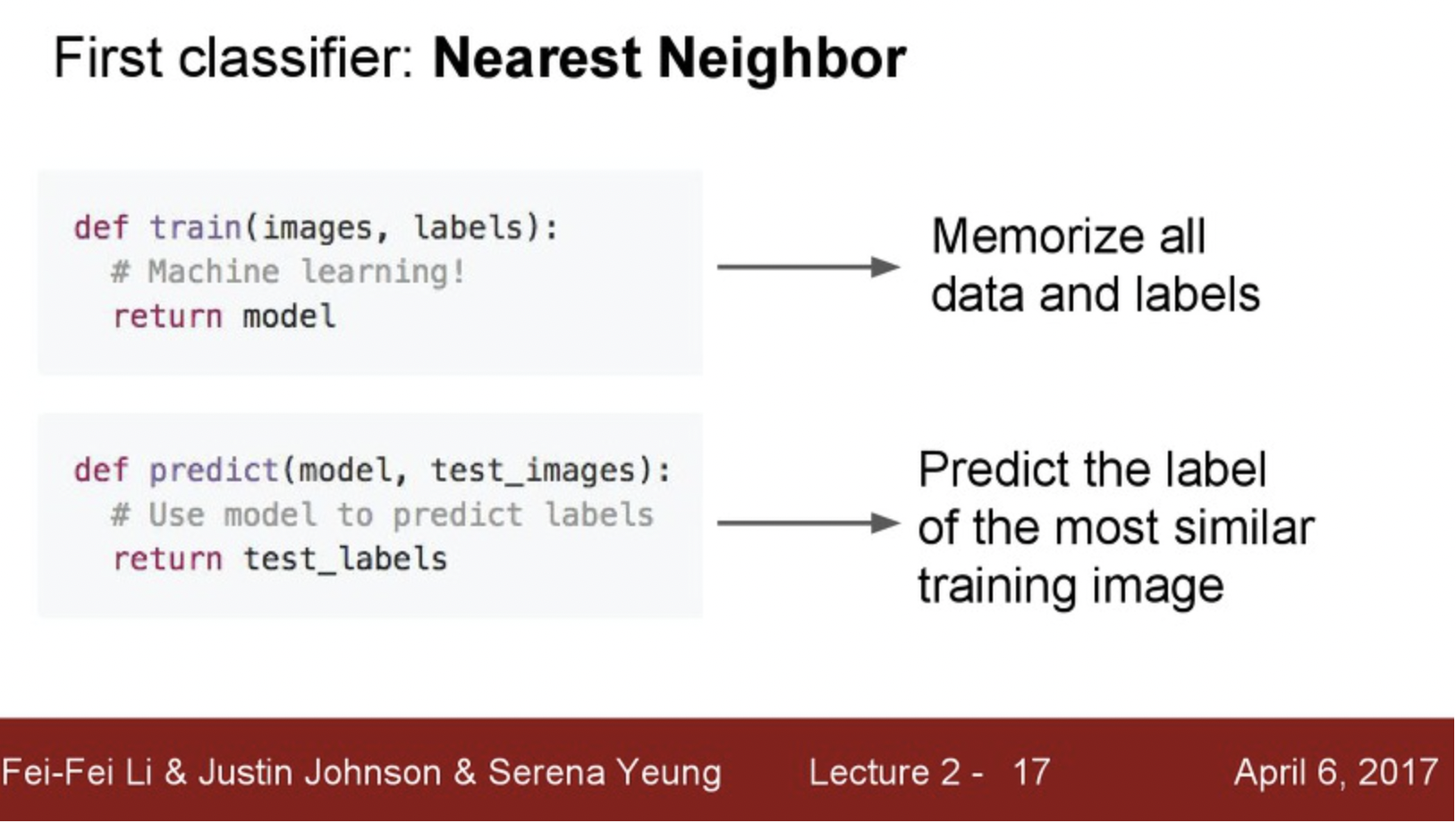
여기서 가장 처음으로 생각해낸 분류법은 Nearest Neighbor(가까운 이웃 찾기) 방법이다. 직관적으로 이해할 수 있듯이 기존에 학습데이터(정답지) 와 가장 가까운 객체로 분류해 달라는 것이다.
수업에서 예시로 드는 이미지 학습 데이터는 CIFAR-10 와 같다. 자세한 설명은 아래 위키 백과에서 확인해보자
https://en.wikipedia.org/wiki/CIFAR-10

위에서 컴퓨터는 사진을 볼 때, 3차원 배열로 인식한다고 했다. 따라서 위 이미지에서 볼 수 있듯이 test image 와 training image 의 배열을 빼서 나온 결과값을을 더해서 나온 대표값이 가장 작은 결과와 동일한 객체로 분류한다는 아이디어이다. 굉장히 1차원적인 사고이지만 이 것이 어쩌면 이미지 분류의 시발점이 되었던 아이디어가 될 수 있겠다. 참고로 레이레이 교수는 이러한 이미지 분류의 역사와 더불어 대표적인 수식, 알고리즘 등을 수업에서 배우길 원하는 것 같다. 개인적인 견해로는 그 과정에서 각 수식들의 특징을 이해하고 추후 네트워크를 설계할 때 응용 할 수 있기를 바라는 것으로 이해했다.
앞서 말한 nearist kneighbor 방법의 경우 시간 복잡도를 생각해보면 은근히 비효율적이라는 것을 알 수 있다. 기존 학습 데이터가 5만개가 존재한다면, input 데이터를 계속 5만개의 데이터와 비교해야 한다는 단점이 있고, 뿐만 아니라 평균값을 구하고, 더하고... 너무 복잡하다고 할 수 있다.
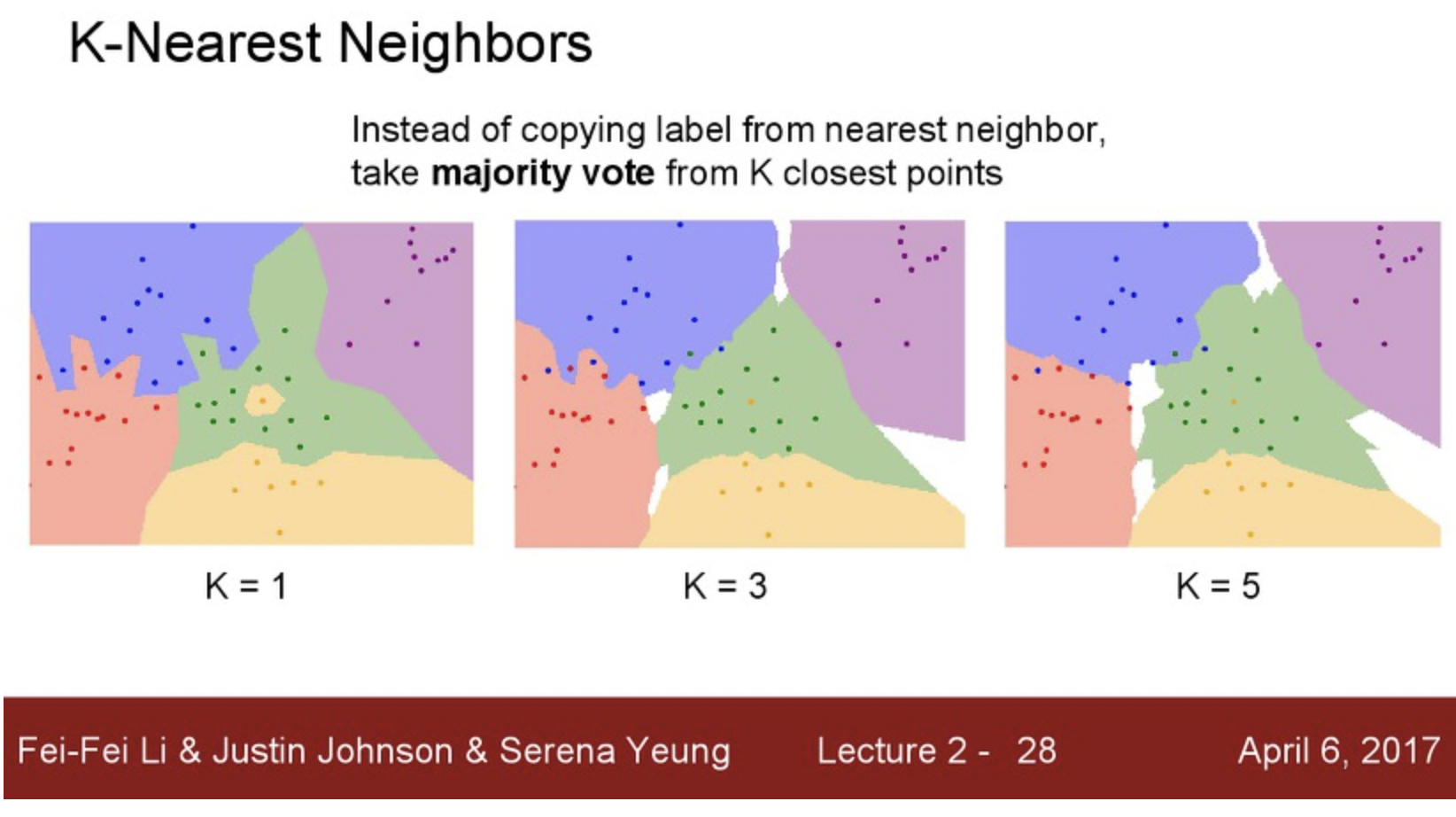
위에 그림에서 가장 좌측이 위에서 예시로 든 Nearest Neighbor이다. 가장 가까운 사진을 찾는건 그대로지만 주변 K 개를 봤을 때 점점 보편성을 갖게 되는 것은 K 값을 증가시키는 것이고 이 것을 K-nearest-neighbors 알고리즘이다.
여기서 K 값은 무엇일까?

일종의 거리라고 할 수 있다. L1 맨하탄 거리와 L2 유클리드 거리는 무엇인지 우리는 기본적으로 알 고 있다고 생각하고 생략하겠다. 위의 공식이 K 라고 직관적으로 생각하면 된다.

그럼 어떤 K를 사용하는 것이 중요할까? 이것이 우리가 직접 정해야하는 값, 즉 Hyperparameter(초모수) 라고 한다. 상황, 학습하려고 하는 데이터 들에 따라 다르고, 직접 하나씩 넣어보면서 어떤 것이 가장 정답률이 높은지 알아내는 것이 중요하다. 기존에 알려진 방식이 있지만 가장 원초적으로 Trial & Error 를 해보는 것이 중요하다고 머신러닝 교과서(도서) 에도 나와잇을 만큼 딥러닝은 인내심이 필요한 분야라고 할 수 있는 것 같다.

그럼 학습할 수 있는 데이터는 어떻게 갖추는 것이 좋을까? 단순하게 생각해서 학습한 데이터로 다시 평가를 하면 성능이 좋게 나올 것임을 알 수 있다. 결론부터말하면 이것을 Holdout이라고 하는데, 준비한 데이터를 3개로 나누는 것이다.
우선 train + validation + test 로 나눈다. train 을 통해서 열심히 훈련된 값을 validation 데이터 셋으로 확인하여 hyperparameter를 바꾸어주고, test로는 마지막 한번 실행을 해서 정확도, 정밀도, 재현율 등을 평가해보는 형태로 가면 된다. 여기서 정확도와 정밀도 재현율 용어는 추후에 나올 것으로 생각하고 넘어가겠다. 단순하게 성능이라고 생각해도 좋다.
그럼 데이터셋이 부족하면 어떻게 하는게 좋을까?
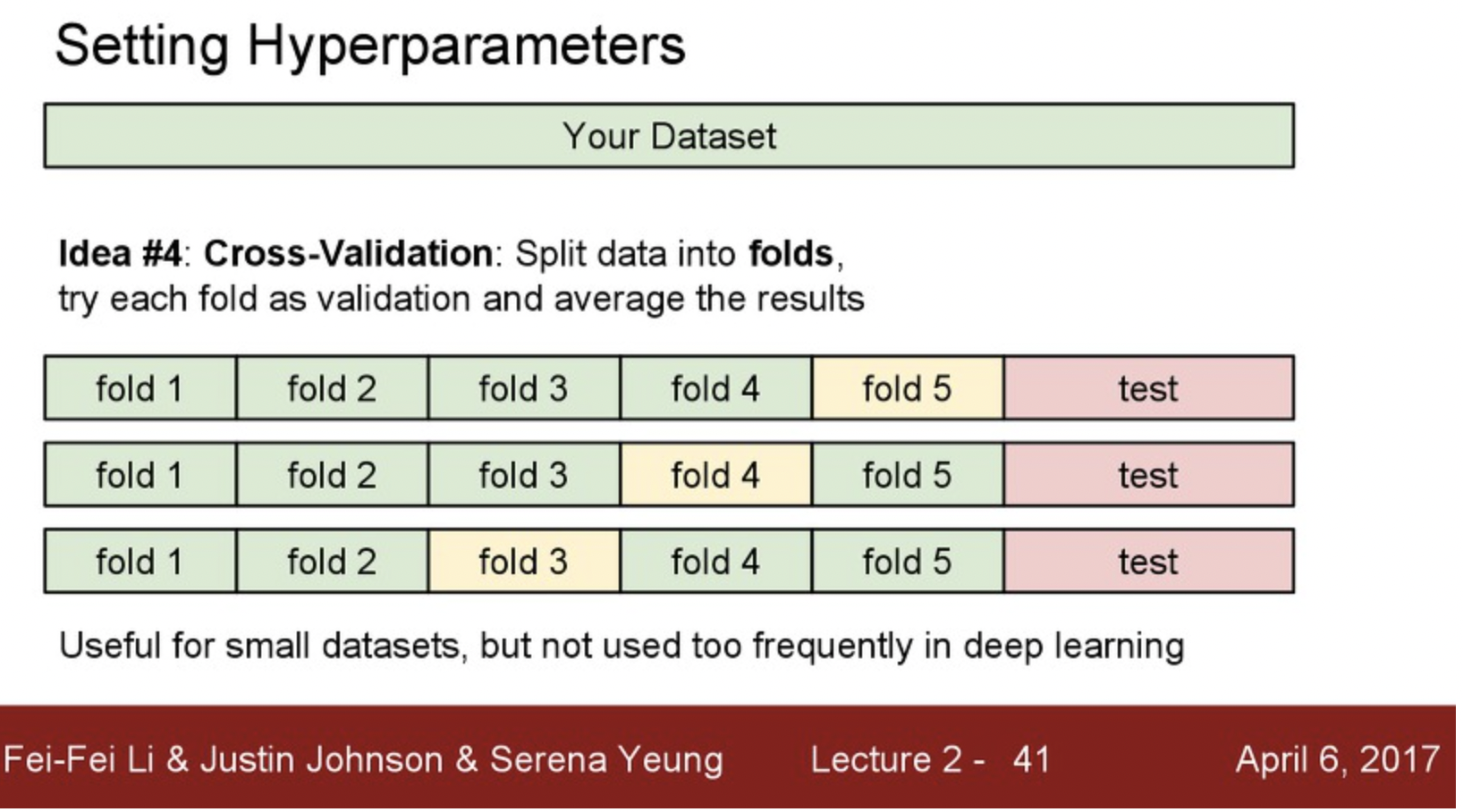
Cross-Validation을 활용하면된다. K-fold validation이라고도 하는데 준비한 데이터를 K + 1개로 나눈다고 가정해보자. K-1을 test, 1을 validation, 1을 test 로 진행해서 성능을 평가하는 것으로 이해하면 좋다. 여기서 K + 1이 데이터 수와 동일하다면 LOOCV 라고도 하는데 이러한 방식들은 매번 Validation set 이 변화하게 되는데 데이터셋이 적은 경우 hyperparameter를 학습시키는데 굉장히 좋은 성능을 보여준다고 알려져 있다.
하지만 안타깝게도 이렇게 길게 설명했던 KNN(K-Nearest-Neighbor)알고리즘은 잘 사용하지 않는다. 위치가 고려된 비교를 하기 때문이다. 또한 차원이 넓어질수록(이미지 사이즈와 색상..등) 필요한 데이터의 갯수가 기하급수적으로 많아진다. 1차원의 경우 4개만 필요했다면 3차원은 4^3가 필요해지며 앞서 언급한 바와 같이 속도에도 큰 문제가 생기기도 한다.
그럼 KNN을 공부한 것이 무용지물일까? 결론은 아니다. 이를 통해 이미지 분류를 위해서는 트레이닝 이미지를 분류해서 작업할 필요가 있으며, 학습에 속도를 개선할 수 있는 방식의 트레이닝 및 예측 알고리즘을 작성할 필요가 있다는 것도 알았다. 또 L1, L2 ...distance가 무엇이며 우리는 궁극적으로 HyperParameter를 최적화할 필요가 있다는 것도 알았다.
그 다음으로 Linear Classification 이 등장한다.

여기서도 함수를 활용하는데 연산량을 줄이는 아이디어를 개진했다. W라는 행렬과 x(flattend image) 를 행렬곱을 시킨후 bias 벡터를 더해줌으로서 나온 결과를 통해서 객체를 분류하는 것이다. 즉 선형 벡터 연산을 통해서 기준값을 바탕으로 객체는 인식하는 아이디어이다.

단순한 예제는 위와 같으며 직관적으로 이해 할 수 있을 것이다.

위 이미지는 각 Hyperparameter(W) 벡터를 이미지화 시킨 결과값인데 놀랍게도 우리가 원하는 객체와 뭔가 비슷한 패턴을 보인다. 특히 car 의 경우는 놀라울 정도이다..
하지만 horse의 경우는 머리가 양쪽으로 두개 달려있는 형상을 띄고 있다. 이것이 사실 Linear Classifier의 문제중 하나인데, 다양한 학습이미지를 바탕으로 파라미터를 튜닝(학습) 하다보니 평균값으로 결정되어 버린다는 점이다.
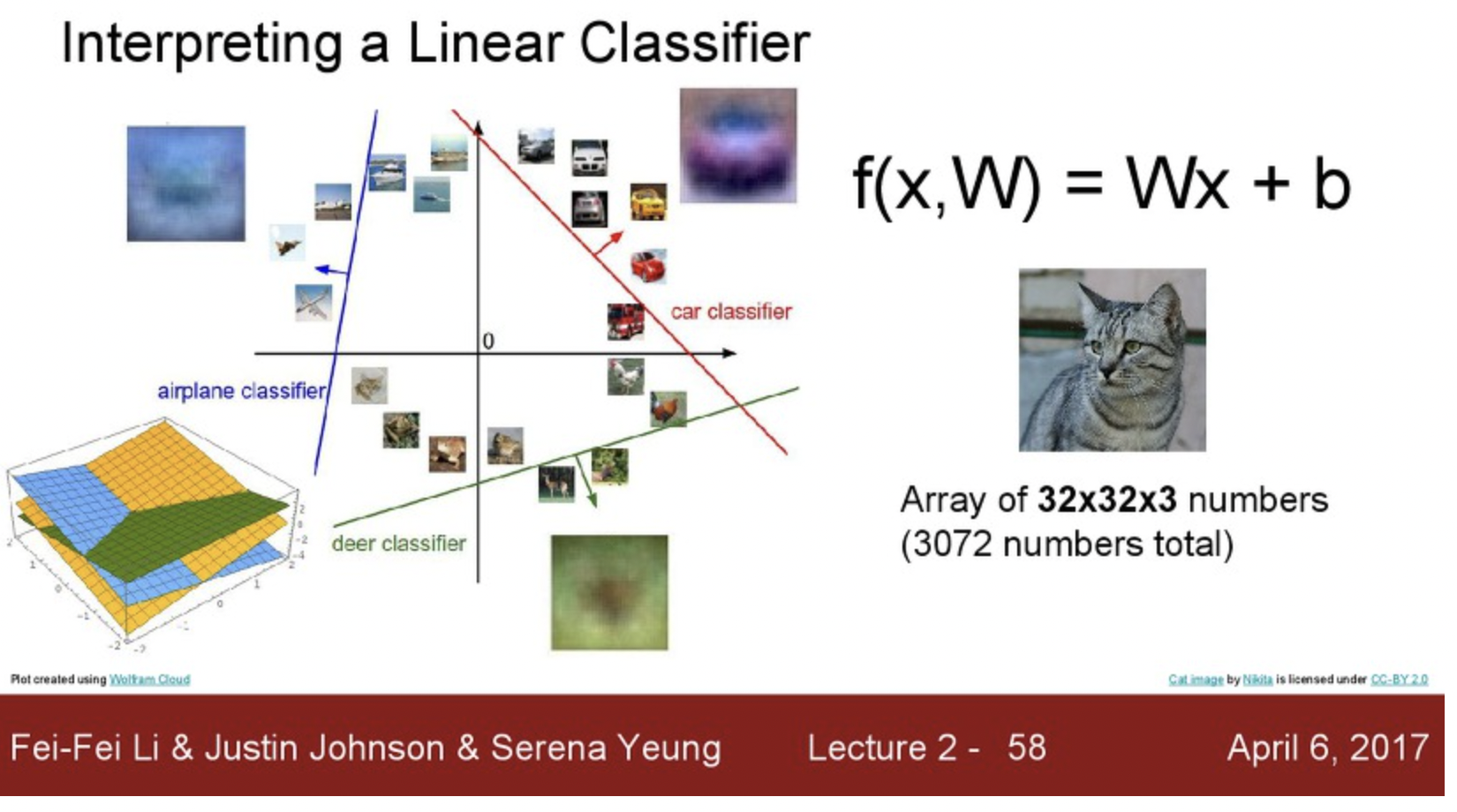
그래서 결과적으로 1차 선형 벡터연산을 통해서 이미지를 2차원 평면에 뿌려놓았다고 가정해보면 선을 그어서 영역을 분류시키는 작업을 한다고 생각하면 된다.

하지만 선형결과로 분리하지 못하는 경우는 위와 같은 반례 사례를 통해 확인 할 수 있다.
다음 강좌에서는 Loss function + Optimization + ConvNets 에 대한 기초 이론을 배운다고 한다.
