드디어 파이썬...
파이썬
:서버를 만들 수 있는 언어/1-2주차 css,html,javascript는 눈에 보이는 것을 다루는 언어
훨씬 직관적이다
파이참에서 그냥 새로만들기-파이썬파일을 하면 여지껏 하던 자바스크립트랑 다른 페이지가 나온다
기초 문법
a_list=['사과',
'배',
'감',
'고구마']
print(a_list[0])각각 문자 사이에 쉼표가 없다면 하나로 생각해서
사과배감고구마 로 출력된다.
쉼표를 넣어야 사과 만 출력된다
실행 단축키: ctrl+shift+r
옆에 위에 실행 버튼은 다른 파일이 실행될 수 있다
IndentationError: unindent does not match any outer indentation level
위 에러는 들여쓰기가 맞지 않아서 발생하는 오류 입니다. 파이썬은 들여쓰기를 정확히 지키지 않으면 문법 오류 입니다. 탭이던 공백이던 한가지로 통일하고 정확하게 일치하는 만큼 들여쓰기를 맞춰주셔야 합니다.
def is_adult(age):
if age>20:
print('성인입니다')
else:
print('청소년입니다')
is_adult(14)
여기서 오류가 나서 한참을 헤맸는데 와 진짜 is_adult(14) 앞에 띄어쓰기 딱하나... 나는 혹시 줄바꿈때문에 틀렸나, 그 뒤에 뭐가 잘못됐나 봤는데 와 정말 개충격.. 빨간줄은 )뒤에 있어서 더 헷갈렸음 오류는 7번째 줄 is_adult(14)에 있다는데.. 와 그게 띄어쓰기 때문일줄이야.. 환장..
fruits = ['사과','배','배','감','수박','귤','딸기','사과','배','수박']
count=0
for fruit in fruits:
if fruit == '사과':
count += 1
print(count)여기서도 마찬가지로 기호랑/변수/문자열 사이에 간격, 띄어쓰기가 없으면 오류난다.
people = [{'name': 'bob', 'age': 20},
{'name': 'carry', 'age': 38},
{'name': 'john', 'age': 7},
{'name': 'smith', 'age': 17},
{'name': 'ben', 'age': 27}]
for person in people:
if person['age']>20:
print(person['name'])크롤링을 하려면 남들이 만들어놓은 라이브러리를 사용해야함(패키지)
패키지 설치(외부 라이브러리 설치)
virtual environment
맥북 파이참 환경설정은 preferences다.. 아 개고생..ㅜㅜ
requests 패키지는 ajax같은..
import requests # requests 라이브러리 설치 필요
r = requests.get('http://spartacodingclub.shop/sparta_api/seoulair')
rjson = r.json()
rows = rjson['RealtimeCityAir']['row']
print(rows)request라는 패키지를 사용한다
request가 어떤 식으로 사용되는지..
r의 json이라는 함수를 rjson 변수에 넣어준다
rjson의 리얼타임시티에어의 로우 값들을 rows 변수에 넣어준다
rows를 프린트한다
import requests # requests 라이브러리 설치 필요
r = requests.get('http://spartacodingclub.shop/sparta_api/seoulair')
rjson = r.json()
rows = rjson['RealtimeCityAir']['row']
for row in rows:
print(row)
gu_name = row['MSRSTE_NM']
gu_mise = row['IDEX_MVL']
print(gu_name,gu_mise)
요렇게 한줄씩! 읽는다!
크롤링(웹스크래핑)
- url 창에 정보를 요청해서 html 페이지를 가져오는 것
ex)request.get()
import requests//리퀘스트 쓸거야
from bs4 import BeautifulSoup//beautifulsoup도 쓸거야
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
//콜을 날리는 건 코드에서이지만, 사람이 날리는 것처럼 브라우저에서 콜을 날리는 것처럼 보여준다 다음줄 맨 마지막 headers=headers 부분에서 사용됨
data = requests.get('https://movie.naver.com/movie/sdb/rank/rmovie.naver?sel=pnt&date=20210829',headers=headers)
//사용자는 url 부분만 바꿔가면서 쓰면 된다
soup = BeautifulSoup(data.text, 'html.parser')
# 코딩 시작beautifulsoup 사용법(파이썬 문법x)
1.웹페이지에서 제목부분 오른쪽 버튼 클릭-검사-element탭에서 title 부분 오른쪽 클릭-copy-copy selector
2.
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://movie.naver.com/movie/sdb/rank/rmovie.naver?sel=pnt&date=20210829',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
title = soup.select_one('#old_content > table > tbody > tr:nth-child(2) > td.title > div > a')
print(title)결과 창에 이렇게 출력됨
<a href="/movie/bi/mi/basic.naver?code=186114" title="밥정">밥정</a> ❗print(title.text) ➡ 밥정 만 출력
❗print(title['href'])하면 ➡ /movie/bi/mi/basic.naver?code=186114 만 출력
3.
다른 영화들도 1번을 실행해보면
#old_content > table > tbody > tr:nth-child(2) > td.title > div > a 진한 글씨 부분이 공통임
앞부분만 떼어내서
여러개니까 select함수에 넣어서 출력해보면
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://movie.naver.com/movie/sdb/rank/rmovie.naver?sel=pnt&date=20210829',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
movies = soup.select('#old_content > table > tbody > tr')
print(movies)
아래 세트가 반복(영화마다) 출력됨
<td class="ac"><img alt="na" class="arrow" height="10" src="https://ssl.pstatic.net/imgmovie/2007/img/common/icon_na_1.gif" width="7"/></td>
<td class="range ac">0</td>
</tr>, <tr>
<td class="ac"><img alt="50" height="13" src="https://ssl.pstatic.net/imgmovie/2007/img/common/bullet_r_g50.gif" width="14"/></td>
<td class="title">
<div class="tit5">
<a href="/movie/bi/mi/basic.naver?code=37886" title="클레멘타인">클레멘타인</a>
</div>
</td>
<!-- 평점순일 때 평점 추가하기 -->
<td><div class="point_type_2"><div class="mask" style="width:93.69999885559082%"><img alt="" height="14" src="https://ssl.pstatic.net/imgmovie/2007/img/common/point_type_2_bg_on.gif" width="79"/></div></div></td>
<td class="point">9.37</td>
<td class="ac"><a class="txt_link" href="/movie/point/af/list.naver?st=mcode&sword=37886">평점주기</a></td>- 공통된 부분의 뒷부분을 반복문에 넣어서 출력시켜보면
❓(근데 공통인데 왜 앞부분은 반복문을 안하고 뒷부분은 반복문에 넣지??)❓
for movie in movies:
a = movie.select_one('td.title > div > a')
print(a)추가해서 입력후 실행하면 (print(movie) 지우고 )
<a href="/movie/bi/mi/basic.naver?code=189027" title="아이즈 온 미 : 더 무비">아이즈 온 미 : 더 무비</a>
<a href="/movie/bi/mi/basic.naver?code=31796" title="반지의 제왕: 왕의 귀환">반지의 제왕: 왕의 귀환</a>
None
<a href="/movie/bi/mi/basic.naver?code=10048" title="죽은 시인의 사회">죽은 시인의 사회</a>
<a href="/movie/bi/mi/basic.naver?code=147092" title="히든 피겨스">히든 피겨스</a>
<a href="/movie/bi/mi/basic.naver?code=163788" title="알라딘">알라딘</a>
<a href="/movie/bi/mi/basic.naver?code=136900" title="어벤져스: 엔드게임">어벤져스: 엔드게임</a>
<a href="/movie/bi/mi/basic.naver?code=17170" title="레옹">레옹</a>
<a href="/movie/bi/mi/basic.naver?code=14450" title="쉰들러 리스트">쉰들러 리스트</a>
<a href="/movie/bi/mi/basic.naver?code=161850" title="아이 캔 스피크">아이 캔 스피크</a>
<a href="/movie/bi/mi/basic.naver?code=134899" title="동주">동주</a>
<a href="/movie/bi/mi/basic.naver?code=181700" title="안녕 베일리">안녕 베일리</a>
<a href="/movie/bi/mi/basic.naver?code=37886" title="클레멘타인">클레멘타인</a>
None요런 식으로 나옴
5.
결과값에 none이 출력되는 경우를 제외하고 보자면
if a is not None: 를 print(a) 윗줄에 추가
❗is not은 !=와 혼용가능
print(a.text)하면 다음처럼 제목만 나옴
어벤져스: 엔드게임
레옹
쉰들러 리스트
아이 캔 스피크
동주
안녕 베일리
클레멘타인QUIZ🔥
순위와 평점 크롤링하기
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://movie.naver.com/movie/sdb/rank/rmovie.naver?sel=pnt&date=20210829',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
movies = soup.select('#old_content > table > tbody > tr')
for movie in movies:
a = movie.select_one('td.title > div > a')
if a is not None:
aa = a.text
b = movie.select_one('td:nth-child(1) > img')['alt']
# print(b['alt']) 이게 안돼서 개빡쳤는데 되는거였음 진짜 다시한번 빡침
c = movie.select_one('td.point').text
#print(c.text)
print(b,aa,c)🤬분노 포인트.. 저장을 안해서 그런가??? 계속 b['alt'] 프린트가 안되고 subscript가 안된다느니 오만 소리를 해대더니 갑자기 됨... 진짜 내 20분?? c도 마찬가지임... ['']속성 부분은 프린트할 때 써도 되고, 아예 변수에 넣어줘버려도 상관 없음 .text도 마찬가지
데이터베이스..!
에 넣어보자~
나중에 정보를 잘 찾기 위해서 데이터베이스를~ 만든다~
-
index: 정렬되어있는 순서
-
db의 종류: SQL(생김새가 정해져있음)/N(ot)o(nly)SQL(기업의 초기단계에서 유연하게 대처하기 좋음)➡mongoDB Atlas(cloud)
-
데이터 집어넣기
from pymongo import MongoClient
import certifi
#보안관련 추가된 부분1
ca = certifi.where()
#보안관련 추가된 부분2
client = MongoClient('mongodb+srv://uummmm:hivved4@cluster0.tbjlpt4.mongodb.net/?retryWrites=true&w=majority',tlsCAFile=ca)
#보안관련 추가된 부분3(쉼표 뒷부분)
db = client.dbsparta
doc = {
'name': 'bob',
'age': 27
}
db.users.insert_one(doc)
#users라는 이름의 db(collection)에 doc(딕셔너리)을 집어넣겠다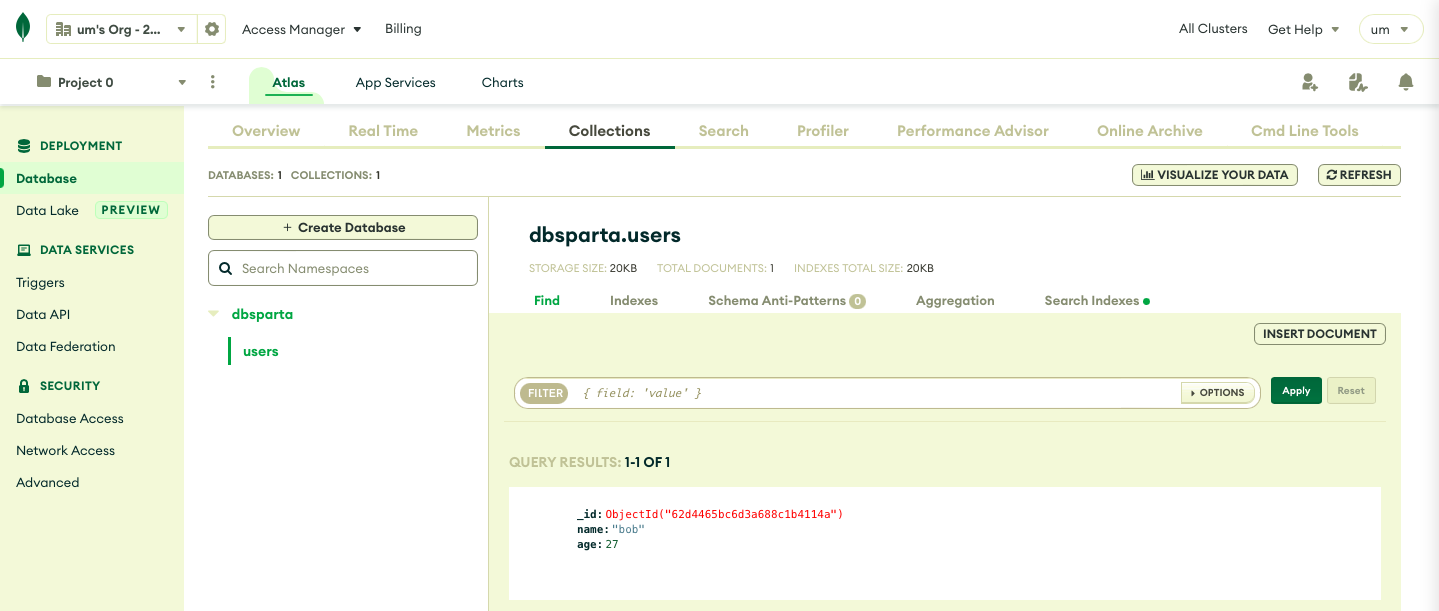
- 데이터 꺼내기
all_users = list(db.users.find({}))
for user in all_users:
print(user)for 뒤의 user는 새로 만든 변수다
/Users/HyoZzang/Desktop/sparta/pythonprac/venv/bin/python /Users/HyoZzang/Desktop/sparta/pythonprac/dbprac.py
{'_id': ObjectId('62d4465bc6d3a688c1b4114a'), 'name': 'bob', 'age': 27}
{'_id': ObjectId('62d44823b0ec088df0f25047'), 'name': 'bobby', 'age': 27}
{'_id': ObjectId('62d44824b0ec088df0f25048'), 'name': 'john ', 'age': 20}
{'_id': ObjectId('62d44824b0ec088df0f25049'), 'name': 'ann', 'age': 20}
종료 코드 0(으)로 완료된 프로세스요렇게 출력됨'_ id'부분은 신경쓰지말것
all_users = list(db.users.find({},{'_id':False}))요렇게 바꾸면 출력 안됨
조건 없이 모두 찾기때문에 find{}안은 비어있음
- 하나만 꺼내기
user = db.users.find_one({'name':'bobby'})
print(user){}안이 조건
- 특정 속성만 꺼내기
user = db.users.find_one({'name':'bobby'})
print(user['age'])- 데이터 수정하기
db.users.update_one({'name':'bobby'},{'$set':{'age':19}})
# users에 가서 업데이트를 하나 하는데 조건을 찾아서, 이렇게 바꿔라- 데이터 삭제하기
코드를 입력하세요pymongo 코드 요약
# 저장 - 예시
doc = {'name':'bobby','age':21}
db.users.insert_one(doc)
# 한 개 찾기 - 예시
user = db.users.find_one({'name':'bobby'})
# 여러개 찾기 - 예시 ( _id 값은 제외하고 출력)
all_users = list(db.users.find({},{'_id':False}))
# 바꾸기 - 예시
db.users.update_one({'name':'bobby'},{'$set':{'age':19}})
# 지우기 - 예시
db.users.delete_one({'name':'bobby'})예제>
순위 평점 크롤링한거 DB에 업로드하기
import requests
from bs4 import BeautifulSoup
# 여기서부터
from pymongo import MongoClient
import certifi
ca = certifi.where()
client = MongoClient('mongodb+srv://uummmm:hivved4@cluster0.tbjlpt4.mongodb.net/?retryWrites=true&w=majority',tlsCAFile=ca)
db = client.dbsparta
# 여기까지 다섯줄 추가(dbprac.py 에서)
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://movie.naver.com/movie/sdb/rank/rmovie.naver?sel=pnt&date=20210829',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
movies = soup.select('#old_content > table > tbody > tr')
for movie in movies:
a = movie.select_one('td.title > div > a')
if a is not None:
aa = a.text
b = movie.select_one('td:nth-child(1) > img')['alt']
c = movie.select_one('td.point').text
doc = {
'title': aa,
'rank': b,
'star': c
}
db.movies.insert_one(doc)Quiz
- 가버나움 평점 가져오기
from pymongo import MongoClient
import certifi
ca = certifi.where()
client = MongoClient('mongodb+srv://uummmm:hivved4@cluster0.tbjlpt4.mongodb.net/?retryWrites=true&w=majority',tlsCAFile=ca)
db = client.dbsparta
movie = db.movies.find_one({'title':'가버나움'})
print(movie['star'])👏👏👏
근데 정말 마우스 오른쪽-실행 아니면 잘 안된다... 왜그래..?
from pymongo import MongoClient
import certifi
ca = certifi.where()
client = MongoClient('mongodb+srv://uummmm:hivved4@cluster0.tbjlpt4.mongodb.net/?retryWrites=true&w=majority',tlsCAFile=ca)
db = client.dbsparta
amovie = db.movies.find_one({'title':'가버나움'})
star = amovie['star']
all_movies = list(db.movies.find({'star':star},{'_id':False}))
for movie in all_movies:
# if movie['star'] == amovie['star']:
# print(movie['title'])
print(movie['title'])위에서 업로드가 잘 안되는 듯해서 여러번 실행했더니 다섯번 올라간듯.. 프린트가 5번 됨... 끄악..................
3.가버나움 평점 0점으로 만들기
db.movies.update_one({'title':'가버나움'},{'$set':{'star':'0'}})3주차 숙제 📚
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://www.genie.co.kr/chart/top200?ditc=M&rtm=N&ymd=20210701',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
songs = soup.select('#body-content > div.newest-list > div > table > tbody > tr')
for song in songs:
title=song.select_one('td.info > a.title.ellipsis').text.lstrip()
atitle=title.strip('19금').strip()
rank=song.select_one('td.number').text[0:2]
#순위 오르내리는거 뺌 앞에서부터 2글자
singer = song.select_one('td.info > a.artist.ellipsis').text
print(rank,atitle,singer)19금 뒤에 공백때문에 정말 빡쳤으나.. 성공했으나.. 왜 그 전껀 안되고 지금은 되는지.. 알 수가 없다.. 진짜 한 50번 넘게 실행한듯..
❓그리고 왜 강사님은.. 19금이 안생길까.. 왜 나는... 뭘잘못한건가??
