
네트워크
- 라우터와 스위치의 차이에 대해 설명하시오
스위치는 맥주소를 이용해서 장비를 로컬 네트워크로 연결해주고 라우터는 IP주소를 통해 다른 네트워크에 연결해줍니다.
기기 > 허브 > 스위치 > 라우터 > 인터넷
스위치
스위칭: 목적지로 출발한 데이터를 중간에 적합한 경로로 바꾸는 것
보통 OSI 7계층 중 2계층에서 동작하는 장비
- MAC 주소를 이용하여 스위칭
- 네트워크 상에서 사용자와 장비를 연결해서 리소스를 공유할 수 있도록 해줌
- 소규모 비즈니스 네트워크 안에서 컴퓨터, 프린터, 서버 등 모든 디바이스를 서로 연결함으로써 리소스를 쉽게 공유할 수 있도록 합니다.
- 신호를 필요로 하지 않는 포트로는 데이터를 전달하지 않기 때문에 충돌 도메인(Collision Domain)을 나누는 데 사용할 수 있다.
- 불명확한 목적지를 가진 데이터를 처리할 때 모든 포트로 데이터를 퍼뜨리는 브로드캐스트를 하고 라우터는 해당 데이터를 버린다.
계층별 스위치
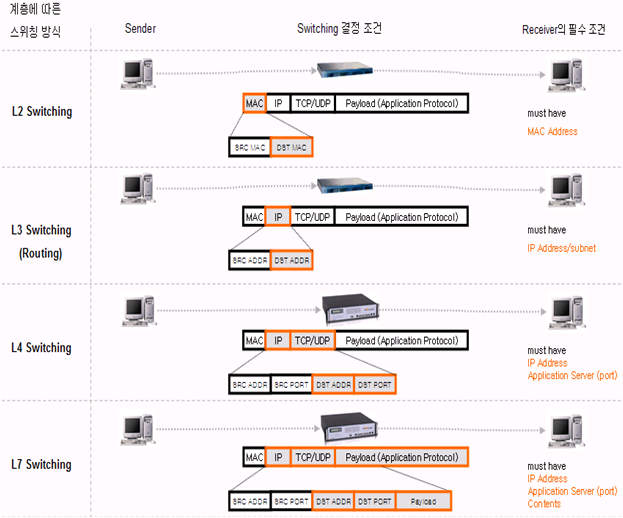
🕹️ L1 스위치
1계층(물리 계층)에서 작동
허브는 자신에게 꽂혀있는 모든 장비에게 데이터를 전부 전달한다.
ex. 허브, 더미 허브
🕹️ L2 스위치
2계층(데이터 링크 계층)에서 작동
ex. 스위칭 허브
- 각 장비의 MAC 주소를 내부적으로 저장하고 있어서 들어온 패킷의 MAC 주소를 읽고 해당 장비를 찾아 데이터를 전달
다른 방식에 비해 가성비가 좋고 구조가 간단하며 신뢰성이 높다
❓패킷에 의해 성능 저하가 발생하는(즉, 라우팅이 불가능한) 단점이 있다.
🕹️ L3 스위치
라우팅
네트워크 대역폭을 확장
L2 스위치+라우팅 기능 = MAC, IP주소를 알고있음
ex. 라우터, 공유기
🕹️ L4 스위치
외부의 요청을 서버들에 분산시킴(로드 밸런싱)
- 서버를 증설해서 IP가 추가된 경우 추가된 IP로도 요청을 보내줌
프로토콜을 기반으로 어플리케이션 별로 우선순위를 부여해서 스위칭
IP주소 + TCP/UDP 포트정보를 가지고 있음
- TCP/UDP헤더로 프로토콜을 구분(HTTP/SMTP등)하여 어플리케이션별로 우선순위를 부여해서 스위칭 (트래픽 분산)
🕹️ L7 스위치
보안 스위치
IP주소+TCP/UDP 포트정보+패킷내용으로 로드 밸런싱
- (7계층이니까)HTTP의 url, FTP 쿠키 정보 및 바이러스 패턴을 분석
라우터
IP 주소를 이용하여 라우팅을 하는 3계층(네트워크 계층)의 장비 (≈ L3 스위치)
- 목적지로 가는 적합한 경로를 찾는 것
여러 스위치 그리고 각각의 네트워크들을 연결하여 더 큰 네트워크를 형성
외부 네트워크를 식별할 수 있다
라우터는 외부 네트워크의 신호를 구분할 수 있다
스위치는 브로드캐스트 도메인을 구분할 수 없지만 라우터는 브로드캐스트 도메인을 구분하여 서로 다른 네트워크 대역을 구분한다.
네트워크를 구분지어 브로드캐스트가 다른 네트워크에 송신되지 않도록 함
- 브로드캐스트 도메인: 같은 네트워크에 속해서 패킷을 전송할 수 있는 범위
https://www.itworld.co.kr/news/167585#csidx1738bf3fcf2ce9389f51ce3515d0e6d
https://m.blog.naver.com/qbxlvnf11/221382123105
https://ojava.tistory.com/200
https://velog.io/@ragnarok_code/%EB%B8%8C%EB%A1%9C%EB%93%9C%EC%BA%90%EC%8A%A4%ED%8A%B8Broadcast%EB%9E%80
https://m.blog.naver.com/qbxlvnf11/221382123105
OS
메모리 단편화
- 메모리 단편화란 무엇인가?
컴퓨터에서 프로그램을 실행하거나 작업을 할 때 컴퓨터는 메모리에 해당 프로그램을 올리고 실행을 하게 됩니다.
이때 주기억장치에서 빈번하게 기억 장소가 할당되고 반납됨에 따라 메모리의 할당과 제거가 빈번하게 일어나서 메모리 공간이 작은 조각으로 나뉘게 되어 사용 가능한 메모리가 충분함에도 메모리 할당이 불가능한 상태가 발생하는 것입니다
메모리 단편화에는 외부 단편화와 내부 단편화가 있는데 외부단편화는 단편화된 메모리가 여러 주소공간에 분산되어 프로세스에 할당할 수 없는 상태를 말합니다
내부 단편화는 프로세스가 필요이상의 메모리를 할당받아서 프로세스의 메모리 공간 내부에 빈 공간이 생기는 것을 말합니다.
메모리 단편화는 페이징, 세그먼트, 메모리 풀로 해결할 수 있는데 페이징은 프로세스를 일정 크기의 페이지 단위로 쪼개서 순서와 상관없이 적재해서 외부 단편화 문제를 해결할 수 있습니다. 세그먼트는 서로 다른 크기의 세그먼트로 메모리를 나눠서 적재하는 방법으로 내부 단편화를 해결할 수 있지만 외부단편화 문제가 발생합니다.
메모리풀은 고정된 크기의 블록을 미리 할당해 놓고 프로세스가 사용할 때 할당받고 사용후에 반납하는 방식으로 메모리가 미리 할당되어있어 메모리의 누수가 있긴 하지만 외부단편화와 내부단편화를 모두 해결할 수 있습니다
Memory Fragmentation
🧩 외부 단편화
필요한 메모리보다 할당할 수 있는 메모리가 적어서 할당하지 못하는 상태? 이건 그냥 메모리단편화 정의같은데
단편화된 메모리가 분산되어있어서 프로세스에 할당할 수 없는 상태
- 압축:
프로세스 사용 공간을 한쪽으로 몰아 자유 공간을 확보하는 것
작업 효율이 좋지 않음
🧩 내부 단편화
프로세스가 필요 이상의 메모리를 할당받음
프로세스가 사용하는 메모리 공간 내부에 남는 부분이 생기는 것
메모리 단편화 해결방법
🧩 페이징
프로세스를 일정 크기로 잘게 쪼개서(페이지) 순서와 상관없이 적재하는 것
순서를 고려하지 않으므로 외부 단편화 문제를 해결할 수 있음
- 압축의 비효율을 보완하기 위해 생긴 방법
내부 단편화 문제가 발생한다
🧩 세그멘테이션
프로세스를 서로 다른 크기로 쪼개서 적재하는 것
- 세그먼트 번호, 시작 주소(base), 세그먼트 크기(limit)를 가진다
- 서로 다른 크기의 세그먼트들이 적재되고 제거되는 일이 반복되면 작은 메모리 조각이 많아져 외부단편화 문제가 발생한다
🧩 메모리 풀
고정된 크기의 블록을 미리 할당해놓고 프로세스가 사용하고 반납한다
- 메모리의 할당 및 해제가 빈번할 때 효과적이다
- 외부단편화와 내부단편화가 발생하지 않지만
- 미리 할당되어있어 메모리 누수.. 가 있다
https://cocoon1787.tistory.com/859
https://daco2020.tistory.com/174
프로세스
-
프로세스의 정의와 특징
컴퓨터에서 실행되는 프로그램을 말합니다. 프로그램을 실행하기 위해 메모리를 할당해서 메모리에 올라가면 프로세스가 되며 프로세스는 내부에 최소 하나의 스레드를 가지고 독립된 주소공간과 메모리 영역을 가집니다. -
CPU Scheduling이란?
한정된 CPU로 여러 프로세스를 실행하기 위해서 특정 기준에따라 메모리를 할당하는 것
스케쥴링 알고리즘을 통해서 할당 순서 및 방법을 결정합니다.
스케쥴링 방법은 선점형 비선점형이 있으며 스케쥴링 알고리즘은 FCFS, SJF, PRIORITY, ROUND-ROBIN(시분할) 등이 있습니다
CPU Scheduling 방법
FCFS: 선점형
먼저 들어온 프로세스가 먼저 실행됨
SJF: 가장 짧은 프로세스를 먼저 실행 -> 비현실적
ROUND-ROBIN(시분할): 비선점형
처리가 다 끝나지 않아도 할당된 시간이 끝나면 넘어감
PRIORITY: 선점형/비선점형
새로운 프로세스가 우선순위가 높으면 먼저 작업함 -> starvation-> 해결: aging(오래 기다린 프로세스의 우선순위를 증가시킴)
https://zzsza.github.io/development/2018/07/29/cpu-scheduling-and-process/
PCB
프로세스 컨트롤 블록
프로세스간 스위칭(다른 프로세스의 스레드 사이의 스위칭)에는 PCB, TCB를 모두 저장해야하고 주소공간을 변경해야한다
TCB
스레드 컨트롤 블록
스레드에 대한 정보를 저장
PCB를 가리키는 포인터가 있음
커널 레벨의 컨텍스트 스위칭의 기본 단위
스레드간 컨텍스트 스위칭은 이 정보만 저장하면 됨
같은 프로세스 내의 스위칭은 주소공간을 바꿀 필요가 없다
멀티스레딩
- 멀티 스레딩(Multi-threading) 의 장점과 단점은?
멀티 스레드는 하나의 프로세스 안에 스레드가 여러 개 있는 것으로 힙을 제외한 프로세스의 메모리 영역을 공유하여 컨텍스트 스위칭으로 발생하는 오버헤드가 적다는 장점이 있지만 자원을 공유하기 때문에 동기화 문제가 발생할 수 있고 이를 고려해 설계(스케쥴링)해야합니다.
https://blockdmask.tistory.com/22
뮤텍스와 세마포어
- 뮤텍스와 세마포어가 무엇입니까?
멀티 프로세스나 멀티 스레드를 사용하게 되면 공유자원의 문제가 발생하게 되는데 뮤텍스와 세마포어는 이렇게 여러개의 프로세스나 스레드가 공유자원에 동시에 접근하지 못하도록 하기 위한 동기화 매커니즘입니다. 둘은 동기화 대상이 되는 공유자원의 수에 따라 국분됩니다.
세마포어는 동기화대상(공유자원)이 하나이상일 때 사용하고 카운터라는 변수로 공유자원에 접근하는 프로세스의 갯수를 조절합니다. 뮤텍스는 이진 세마포어라고도 하는데 동기화 대상이 오직 하나뿐일 때 사용합니다
멀티스레딩
⚒️ 멀티 프로세싱
크롬에서 하나의 탭이 문제가 생겼을 때 그 탭만 끄면 됨
프로세스의 컨텍스트 스위칭에는 IPC가 필요하다
- IPC: Inter-Process Communication
ex. shared memory, PIPE , 세마포어!!...
여러개의 CPU가 1개의 메모리에 연결
두개의 코어가 프로세스를 두개씩 병렬로 분담(동시)해서 프로세스를 병행처리하는 것
⚒️ 싱글코어 멀티스레딩/멀티코어 멀티스레딩
IE에서 하나의 탭이 문제가 생겼을 때 전체 창을 종료해야함
- 스레드는 자원을 공유하기때문에 하나의 스레드의 문제가 다른 스레드에 영향을 미친다
멀티스레딩은 여러 코어에서 한 번에 여러 개의 스레드를 처리하는 CPU 성능을 활용하는 프로그래밍의 한 유형입니다. 동시에 여러 개의 작업 또는 명령을 실행합니다.
프로그램 안에서 병렬 처리
스레드 수준뿐 아니라 명령어 수준의 병렬 처리에까지 신경을 쓰면서 하나의 코어에 대한 이용성을 증가 == 단일 CPU 자원을 효율적으로 쓴다
메인 스레드는 프로그램이 시작할 때 실행
- 작업을 처리하기 위해 새로운 스레드를 생성
- 새 스레드는 다른 스레드와
병렬로 실행되며, 대개 실행이 완료되면 메인 스레드와 결과를 동기화
- 새 스레드는 다른 스레드와
여러 개의 작업이 오랫동안 실행되는 경우에 적합
-
한 번에 실행해야 할 작은 명령이 많이 있는 경우, 각 명령에 대해 스레드를 만들면 그 수가 너무 많아지고 각각의 수명도 짧아져서 CPU 및 운영체제의 프로세싱 능력을 초과할 수 있습니다.
스레드 풀을 사용해서 수명주기 문제를 완화할 수 있다
ex. CPU 코어 < 스레드: CPU 리소스를 놓고 스레드 간에 경쟁 →
컨텍스트 스위칭횟수 증가- 실행중이던 스레드 상태를 저장하고 다른 스레드에 대한 작업을 진행한 후 첫 번째 스레드를 재구성하여 나중에 계속 처리
→ 리소스를 매우 많이 소모
⚒️ 장점
- 응답성 - 스레드가 여러개니까 하나의 스레드가 사용중이더라도 다른 스레드가 사용자의 필요에따라 응답할 수 있다
- 자원공유 - 같은 프로세스를 공유하므로 같은 주소공간(메모리 영역을 가리킴) 내에 여러개의 활동성 스레드를 가질 수 있다
- 경제성 - 프로세스를 생성하는 것은
메모리와 자원을 할당하는 것이고비용이 많이 든다
스레드는 자원공유를 하기때문에 프로세스보다 스레드를 생성 및 스레드 컨텍스트 스위칭이 경제적이다 - 멀티 프로세서 활용 - 멀티 프로세서 구조에서 각각의 스레드가 다른 프로세서에서 병렬로 수행될 수 있다
⚒️ 단점
- 다중 스레드는 캐시나 변환 색인 버퍼(TLB)와 같은
하드웨어 리소스를 공유할 때 서로를 간섭할 수 있다. - 하나의 스레드만 실행 중인 경우 싱글 스레드의 실행 시간이 개선되지 않고 오히려 지연될 수 있다.
- 멀티스레딩의 하드웨어 지원을 위해 응용 프로그램과 운영 체제 둘 다 충분한 변화가 필요하다.
- 스레드 스케줄링은 멀티스레딩의 주요 문제이기도 하다.
⚒️ 멀티스레드 모델
CPU 스케쥴링의 단위가 스레드니까 유저 스레드 기준으로 모델을 구상한건가?
- 다대일
- 유저모드의 스레드(多) - 커널스레드(프로세스)(一)
- 유저모드 스레드(多)는 인식되지 않고 하나의 프로세스로 묶여서 인식됨
- 단점: 한 번에 하나의 스레드만이 커널에 접근할 수 있다
- 하나의 스레드가 커널에 시스템 호출을 하면 나머지 스레드들은 대기해야 하기 때문에 진정한 의미의 동시성을 지원하지 못한다.
- 일대일
- 유저모드의 스레드(一) - 커널모드 스레드(一)
- 사용자 스레드가 생성되면 그에 따른 커널 스레드가 생성되는 것
- 커널 스레드도 한정된 자원을 사용하므로 무한정 생성할 수는 없기 때문에, 스레드를 생성할 때 그 개수를 염두에 두어야 한다.
- 다대다
- 여러 개의 유저 스레드(多) - 여러 개의 커널 스레드(多)
다-대-일 방식과 일-대-일 방식의 문제점을 해결하기 위해 고안
커널 스레드는 생성된 사용자 스레드와 같은 수 또는 그 이하로 생성
⚒️ 멀티코어 프로세서
하나의 CPU에 코어가 여러 개일 수도 있고
CPU가 두 개 이상일 수도 있다
- 코어: CPU안에서 일하는 부품 중 하나로 프로세서가 하는 일을 분담
*CPU = 코어 + 컨트롤러 + 캐시메모리 + ...
코어의 면적(트랜지스터의 수) 증가로 성능을 향상시키는 것이 기술의 한계에 부딪혀서 코어 갯수를 늘려서 CPU전체의 성능을 향상시키려고 하다 나온 것이 멀티 코어
멀티 프로세서 = 멀티 CPU
https://docs.unity3d.com/kr/2020.3/Manual/JobSystemMultithreading.html
https://ko.wikipedia.org/wiki/%EB%A9%80%ED%8B%B0%EC%8A%A4%EB%A0%88%EB%94%A9
동시동시동시 ⭐⭐⭐
concurrent: 싱글 코어에서 여러 스레드가 스위칭에 의해 동시(처럼 보이게)에 수행되는 것 - 싱글 코어, 멀티 코어에서 모두 가능 멀티도 싱글로 이루어져있으니깐..
simultatneous: 여러 CPU환경(멀티코어인듯)에서 여러 스레드가 실제로 동시에 수행되는 것
parallelism: 병렬성. 실제로 동시에 수행되는 것으로 멀티코어에서만 가능 - 물리적으로 코어가 여러 개니까
프로그래머스 문제풀기
➡️ 숫자 짝꿍
아니 이거를 왜 그렇게 풀었던거지..? 과거의 나 뭘 한걸까..
def solution(X, Y):
X,Y=str(X),str(Y)
xandy=list(set(X)&set(Y))
if not xandy:
return '-1'
elif xandy == ['0']:
return '0'
xandy.sort(reverse=True)
answer=[xy*min(X.count(xy),Y.count(xy)) for xy in xandy]
return ''.join(answer)X, Y가 정수이므로 반복문에 쓰기 위해서 스트링으로 바꿔준다
X, Y에 공통되는 부분을 찾아서 탐색 범위를 줄이기 위해 교집합을 구한다
set은 sort()를 사용할 수 없다
-
사용하려면 리스트로 변환 후 사용하고 다시 집합으로 바꿔줘야한다
-
또는 리스트에 세트를 담아도 정렬이 가능하다 이건 좀 신기하다
s = [{5,2,7,1,8}] s.sort() # [{1, 2, 5, 7, 8}] -
sorted(set)은 가능하고 sorted를 사용하면 리스트로 바뀐다⭐
정렬하는 부분을 축약식 안으로 넣어버리면 한 줄 더 짧게 가능하지만.. 굳이 그럴 필요가 있을까 싶다
