
도커
도커는 컨테이너 런타임 (실행 및 관리도구)이다.
- 어플리케이션 컨테이너 런타임
- 컨테이너는 (호스트 입장에서)프로세스다.
- 컨테이너는 (주로) 리눅스 커널(컨테이너가 공유하는 것)에 포함된 프로세스 격리 기술들을 사용해서 생성된 특별한 프로세스
- 컨테이너가 서로 다른 파일 시스템을 가질 수 있는 이유는 이미지(파일의 집합)를 루트 파일 시스템으로 강제로 인식시켜 프로세스를 실행하기 때문
*busybox는 컨테이너 실행 환경이다.
- 컨테이너는 (호스트 입장에서)프로세스다.
도커 컨테이너와 가상머신의 차이
- 가상머신
- 호스트 운영체제 위에 하드웨어를 에뮬레이션하고
- 그 위에 운영체제를 올리고
- 프로세스를 실행
- 도커 컨테이너
하드웨어 에뮬레이션 없이
- 리눅스 커널을 공유해서 바로
- 프로세스를 실행한다
파이썬
메모리 관리
Cpython: 파이썬 설치 시 기본적으로 제공하는 인터프리터
- Cpython에서는
레퍼런스를메모리 주소 값을 이용하여 구현하고 있습니다. - 변수의 레퍼런스와 오브잭트를 생성하여 스택과 힙에 올려놓습니다.
- namespace: name 집합에서 object집합으로 가는 함수
- name: 변수, 레퍼런스
object:메모리에 올려진 데이터/코드 - 딕셔너리로 구현
- key: object의 reference이고 name이라 말하기도 합니다.
- value: 메모리상 object의 위치
- namespace lifetime
global:
빌트인(내장 함수 및 상수)은 인터프리터 실행 ~ 프로그램 종료
모듈(함수)은 정의되는 순간 ~ 프로그램 종료
local: 함수 실행시 생성 ~ 함수 종료 - local → global 순으로 찾음
- name: 변수, 레퍼런스
소스코드 → 컴파일링→ 기계어(바이트 코드) →프린팅/런타임
- 런타임 때 파이썬은 바이트코드를 python virtual machine라는 가상 컴퓨터에서 실행
- ex.
'python' is 'py'+'thon'
왼쪽과 오른쪽은 오브젝트의 위치가 동일
a='thon'
'python' is 'py'+a
스트링 연산으로 왼쪽과 오른쪽의 오브젝트들은 위치가 다름- 스트링 연산
변수에 저장된 문자열을 연산하는 것
→ BINARY_ADD를 런타임에서 실행하게됨 == 최적화된 코드가 아님
- 스트링 연산
컴파일타임에 작동을하는 코드인지 런타임에 작동하는 코드인지 잘 생각하며 코드를 짜자
https://yomangstartup.tistory.com/105
제너레이터 (feat. iterator)
Generator Functions and Generator Expressions are better than Iterators.
- They allow programmers to make an iterator in a fast, easy, and clean way.
Generator Expressions
- primes = (i for i in range(2, 100000000000) if check_prime(i))
- 리스트 축약식에 쓰는 그거 맞음 저번에 했던.. 괄호만 다름
- 복잡하고 길어지는 경우 가독성이 떨어져서 그냥 iterator 쓰는 게 좋음
https://velog.io/@loooggi/0213-TIL
Iterators and generators can only be iterated over once.
Iterators allow lazy evaluation, only generating the next element of an iterable object when requested. This is useful for very large data sets.
- By using an iterator, we’re not creating a list of results in our memory. Instead, we’re generating the next result every time we request for it.
def check_prime(number):
for divisor in range(2, int(number ** 0.5) + 1):
if number % divisor == 0:
return False
return True
#iterator
class Primes:
def __init__(self, max):
self.max = max
self.number = 1
def __iter__(self):
return self
def __next__(self):
self.number += 1
if self.number >= self.max:
raise StopIteration
elif check_prime(self.number):
return self.number
else:
return self.__next__()
primes = Primes(100000000000)
print(primes) #<__main__.Primes object at 0x1021834a8>235711...
#generator
def Primes(max):
number = 1
while number < max:
number += 1
if check_prime(number):
yield number
primes = Primes(100000000000)
print(primes) #<generator object Primes at 0x10214de08>235711...
#generator using Generator Expressions
primes = (i for i in range(2, 100000000000) if check_prime(i))프로그래머스 문제풀기
➡️시저암호
입력값 〉 "z", 1
기댓값 〉 "a"
실행 결과 〉 실행한 결괏값 "\u0001"이 기댓값 "a"과 다릅니다.
출력 〉 letter: z idx: 123
letter2: z idx2: 1왜 유니코드가 나올까 니가 잘못했으니까...
문자열.replace()는 해당하는 문자가 있으면 다 바꿔버려서 반복문에 넣으면 이미 바뀌어서 저장된 결과값에도 영향을 미친다.
ex. 'ab'를 한칸씩 민다고 했을 때
1회차에 a->b로 바꿔서 bb로 바꾸고
2회차에 b->c로 바꾸면 cc가 된다
replace뒤에 하나만 바꾼다고 쓰면 맨 앞에있는 것만 바뀌어서 여기선 효과가 없었다.
def solution(s, n):
ans=[]
for letter in s:
if not letter.isalpha():
ans.append(letter)
else:
idx=ord(letter.upper())+n
if idx>90:
idx-=26
if letter.islower():
ans.append(chr(idx).lower())
else:
ans.append(chr(idx))
return ''.join(ans)공백은 그대로 append하고
알파벳을 무조건 대문자로 바꿔서 고려해야하는 아스키코드 범위를 줄이고 원래 소문자였다면 소문자로 바꿔준 값을 append
➡️시저암호 다른 풀이
range(len())
def caesar(s, n):
s = list(s)
for i in range(len(s)):
if s[i].isupper():
s[i]=chr((ord(s[i])-ord('A')+ n)%26+ord('A'))
elif s[i].islower():
s[i]=chr((ord(s[i])-ord('a')+ n)%26+ord('a'))
return "".join(s)- 문자열에 공백이 포함되어있을 때 리스트로 바꾸면 공백도 하나의 요소가 됨
- 원래 s를 그대로 리스트로 만들어서 사용해서
리스트의 요소가 영문 대문자/소문자일때만 그 값을 변경하고
공백은 if/elif에 해당사항이 없으므로 변경없이 원래 요소값 그대로 유지됨 - n이 26이상이라면 %26이 맞음
그리고 %26을 하게되면 90보다 큰지 작은지를 생각할 필요가 없음 ⭐
💡 주어진 리스트 요소 값만 변경하는 작업을 할 경우 내가 그렇게 싫어하는 index out of range 에러가 날 일이 없으니까 새 리스트 만들어서 append하거나 문자열을 써서 문자열 연산을 하는 것보다는 리스트 요소로 접근해서 필요한 부분만 변경하는 게 가장 좋은 것 같다.
containment
def caesar(plain, no):
result = ""
for k in plain:
if k.isalpha():
if k.islower():
result += chr((ord(k) - ord("a") + no) % 26 + ord("a"))
else:
result += chr((ord(k) - ord("A") + no) % 26 + ord("A"))
else:
result += k
return result- 아스키 코드를 사용해서 풀 때 대문자인지 소문자인지를 먼저 나누고
- 다시 문자로 변환할 땐 할 때 chr(현재 문자를 아스키로 바꾼 값에서 기준값을 빼준 후 n을 더한 값을 %26 ==
기준부터 몇 칸 밀렸는지 계산⭐ 후 다시 +기준값==그래야 아스키코드 값으로 바꿀 값(65~90 범위)이 나옴 )
lambda
def solution(s, n):
def inner(word):
c = (lambda a: a+26 if 97>a else a-26 if a>122 else a)(ord(word.lower()) + (n%26))
return chr(c).upper() if word.isupper() else chr(c)
return "".join([inner(w) if w.isalpha() else w for w in list(s)])- n%26 애초에 n>26이면 먼저 나눠버리는 것도 방법!⭐⭐⭐
a+26 if 97>a else이 부분은 지워버려도 된다. 애초에 인자로 들어가는 값이 소문자의 아스키코드 값을 구하는 거라서 97보다 작은 경우가 있을 수가 없고
97보다 작은 값중엔 문자 부호도 있어서 lower을 해주지 않은 값을 인자로 넣었을 경우 오류가 발생할 수 있다.- 이 풀이도 %26이 아니라 -26을하니까 범위를 생각해야함
약간의 수정을 해봄
def solution(s, n):
s=list(s)
for i,letter in enumerate(s):
if letter.isalpha():
idx=(ord(letter.upper())-ord('A')+n)%26+ord('A')
if letter.islower():
s[i]=(chr(idx).lower())
else:
s[i]=(chr(idx))
return ''.join(s)- 어쨌든 idx를 구하는 건 알파벳일때만 해야하기때문에 알파벳인지 확인하는 작업이 필요하다
- 그리고 대문자일 때와 소문자일 때 값을 다르게 넣어야하므로
애초에 그냥 대문자인지 소문자인지를 판별하는 첫번째 풀이가 가장 효율적이다. - enumerate를 해서 i,letter를 쓰는 것과
range(len)를 써서 s[i]로 조회하는 것과 시간은 거의 똑같이 걸리고 - 리스트의 값을 바꿔줄 때는
letter=을 쓰면 letter값은 변경되지만 list에 반영이 안된다는 걸 잊지말자 ⭐⭐⭐
자료구조
해시
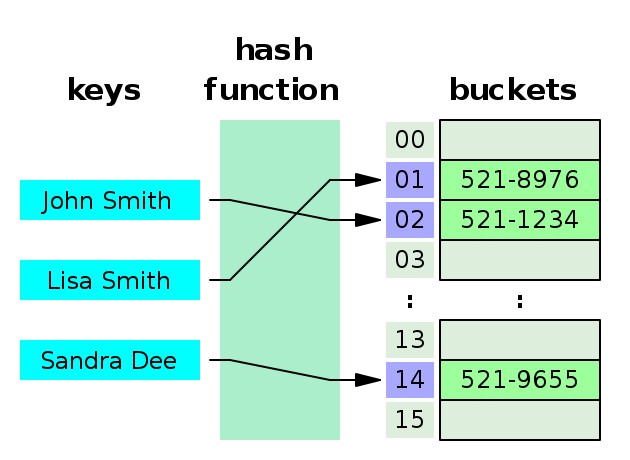
→ 파이썬의 딕셔너리
🛸hash function
key에 해당하는 데이터를 고정된 길이의 hash로 바꿔줌(해싱)
해시값을 고르게 생성할수록 좋은 해시함수
🛸hash table
key-value가 1:1로 매핑되어 있기 때문에 삽입, 삭제, 검색의 과정에서 모두 평균적으로O(1)의 시간복잡도를 가지고 있다.
-
문제점
-
메모리 낭비
데이터가 저장되기 전에 미리 저장공간을 잡아놓기 때문 -
해시값 충돌
보통 실제 키의 갯수보다 테이블의 크기를 작게 잡아놓기 때문에 해시충돌이 발생하는 경우가 많다.if 키 갯수 == 테이블의 크기 : direct address table 충돌이 발생하지 않는다.
-
-
해결방법
- 개방주소법close hashing: 충돌이 일어나면 비어있는 hash(선형/제곱탐색으로 찾음)에 데이터를 저장하는 방법
- 체이닝open hashing: 기존 값과 새로운 값을 링크드리스트로 연결
충돌이 난 후에 해당 키에 공간을 만들어서 연결해주므로 충돌에 대비한 메모리 확보를 미리할 필요가 없다(메모리 낭비x)
*하나의 키에 여러 value값이 저장됨
