
파이썬
- 파이썬은 객체지향 입니까? 왜 그렇습니까?
네. 절차지향이나 함수형도 구현이 가능하긴 하지만 객체지향형 프로그래밍에 최적화된 언어입니다.
객체 지향 프로그래밍: OOP
-
각각의 객체들이 독립적이기 때문에 코드의 변경을 최소화하고 유지보수를 하는 데 유리
-
코드의 재사용을 통해 반복적인 코드를 최소화하고, 코드를 최대한 간결하게 표현
요구사항은 시시때때로 변경될 수 있으므로 변경하기 쉬운 코드를 작성하는 것이 중요하다 -
객체를 추상화시켜 속성(state)과 기능(behavior)으로 분류한 후에 이것을 다시 각각 변수(variable)와 함수(function)로 만듬
-
추상화, 상속, 그리고 다형성의 특성을 활용하여 역할과 구현을 구분하여 객체들 간의 직접적인 결합을 피하고, 느슨한 관계 설정을 통해 보다 유연하고 변경(수정 및 확장)이 용이한 프로그램 설계를 가능
-
캡슐화
코드의 의존성을 줄이고(자율성이 높아지고) 결합도를 낮추는 것 == 캡슐화⭕
서로 연관있는 속성과 기능들을 하나의 캡슐(capsule)로 만들어 데이터를 외부로부터 보호하는 것
캡슐화의 목적: 데이터(속성과 기능) 보호(접근 제한) 및 은닉(내부의 동작을 감추고 필요한 부분만 노출)
- ex. 접근 제어자 in Java
public> default> protected> private
- ex. getter & setter in Java
객체간의 결합도(의존도)를 낮춰준다
캡슐화로 내부의 노출을 줄이면 객체의 자율성이 높아지고 이것은 하나의 객체가 해당 객체의 속성과 기능에 대한 독점적인 책임을 담당하도록 만들고, 이를 통해 객체 간의 결합도를 낮게 유지할 수 있다. -
추상화
의인화 == 모든 객체들이 능동적이고 자율적인 존재
객체의 공통적인 속성(변수)과 기능(함수)을 추출하여 정의하는것
- ex. interface & abstract class in Java
인터페이스: 추상 메서드나 상수를 통해서 어떤 객체가 수행해야 하는 핵심적인 역할만을 규정해두고, 실제적인 구현은 해당 인터페이스를 구현하는 각각의 객체들에서 하도록 프로그램을 설계하는 것 == 유연하고 변경이 용이한 프로그램 설계가능public interface Vehicle { public abstract void start() void moveForward(); //public abstract 생략가능 void moveBackward(); } //인터페이스에서 정의한 역할을 각 클래스의 맥락에 맞게 구현 public class Car implements Vehicle { //Car 고유 속성 boolean isConvertible @Override public void moveForward() { System.out.printLn("자동차가 전진합니다."); } @Override public void moveBackward() { System.out.println("자동차가 후진합니다."); } //Car만의 고유한 기능 void openWindow() { System.out.println("창문을 연다"); } } public class MotorBike implements Vehicle{ @Override public void moveForward() { System.out.printLn("오토바이가 전진합니다."); } @Override public void moveBackward() { System.out.printLn("오토바이가 후진합니다."); } } -
다형성
객체의 속성이나 기능이 상황에 따라 여러가지 형태를 가질 수 있음
코드의 양을 줄여 유지보수를 용이하게 해줌
- ex. 오버라이딩과 오버로딩
- 오버라이딩: 여러 클래스에 걸쳐서 같은 이름의 메서드(공통)를 만드는 것. → 클래스별로 같은 이름의 메서드를 구현
- 오버로딩: 하나의 클래스 내에서 같은 이름의 메서드를 여러 개 중복하여 정의하는 것. 동일한 이름의 메서드에 입력되는 인자의 자료형이나 갯수를 다르게 해서 받음. C++이나 Java에서는 지원하지만 파이썬에서는 지원하지 않아 프로그래머가 알아서 처리해야한다.
- ex. 여러 종류의 상속관계에 있는 클래스로 만든 객체를 하나의 배열에 담을 수 있음public class Main { public static void main(String[] args) { Vehicle car2 = new Car() //상위클래스 타입의 참조변수 car2 에 할당 ← 하위클래스의 객체를 생성 //== 상위클래스 타입의 참조변수로 하위클래스 객체를 참조함 Vehicle vehicles[] = new Vehicle[2]; //Vehicle과 상속관계에 있는 하위 클래스를 담을 수 있는 배열 vehicles[0] = new Car(); // class는 Car vehicles[1] = new MotorBike(); // class는 MotorBike } -
상속
다형성(오버라이딩)에 포함된다고 볼 수 있음
상위 클래스의 속성과 기능들을 간편하게 사용
공통되는 부분의 수정이 필요하면 상위클래스에서 한번만 변경하면 됨public class Vehicle { // 추상화를 통한 상위 클래스 정의 String model; String color; int wheels; void moveForward(){ System.out.printLn("전진합니다."); } void moveBackward(){ System.out.println("후진합니다."); } } //Vehicle에 이미 있는 부분들은 쓰지 않고 각 클래스의 고유속성과 기능만 정의 public class Car extends Vehicle { //Car 고유 속성 boolean isConvertible //Car 고유 기능 void openWindow() { System.out.println("창문을 연다"); } } public class MotorBike extends Vehicle{ @Override //메서드 오버라이드 -> 선택적 재정의 void moveForward() { System.out.printLn("오토바이가 전진합니다."); } public void stunt() { System.out.printLn("오토바이로 묘기를 부립니다."); } } //실행 public class Main { public static void main(String[] args) { Car car = new Car(); //객체 생성 //하위클래스 타입의 참조변수 car 에 할당 ← 하위클래스의 객체를 생성 car.model="테슬라"; //객체 속성 정의 car.moveForward(); //객체 기능 실행 Vehicle car2 = new Car() //다형성 예제 //상위클래스 타입의 참조변수 car2 에 할당 ← 하위클래스의 객체를 생성 //== 상위클래스 타입의 참조변수로 하위클래스 객체를 참조함 }
-
🫣 객체지향 설계 원칙 SOLID
- SRP(Single Responsibility Principle): 단일 책임 원칙
하나의 클래스는 하나의 책임만 가진다.
변경에 의한 연쇄작용을 피할 수 있다. == 유지보수가 쉬워진다.
가독성이 좋아진다.- OCP (Open-Closed Principle): 개발-폐쇄 원칙
요구사항의 변경이나 추가사항이 발생해도, 기존 구성요소에는 수정이 일어나지 않고, 기존 구성요소를 쉽게 확장하여 재사용가능하도록 만들어야 한다.
이 원칙을 지키기 위해서는 객체지향의 추상화와 다형성을 활용해야한다.- LSP(Liskov Substitution Principle): 리스코프 치환 원칙
클래스 상속, 인터페이스 상속을 이용해 확장성을 획득한다.
다형성과 확장성을 극대화 하기위해 인터페이스를 사용하는 방법도 있고, Composition을 이용할 수도 있다.- ISP(Interface Sergregation Principle): 인터페이스 분리 원칙
자신이 사용하지 않는 인터페이스는 구현하지 말아야 한다
인터페이스 분리 원칙을 적용하기 위해서는 가능한 최소한의 인터페이스만을 구현해야한다.
인터페이스의 단일 책임 원칙- DIP(Dependency Inversion Principle): 의존성 역전 원칙
상위 모델은 하위 모델에 의존하면 안된다. 둘다 추상화에 의존하여야 한다.
추상화는 세부 사항에 의존해서는 안된다. 세부 사항은 추상화에 따라 달라진다.
메모리 관리
- 파이썬에서 메모리 관리는 어떻게 이루어지는가?
파이썬은 메모리를 자동으로 관리해주는 메모리 매니저가 있습니다. 이 메모리 매니저는 메모리를 동적할당함으로써 메모리를 효율적으로 사용할 수 있게 하는데, 변수와 메소드는 호출시 스택 구조의 메모리 공간에 저장되고 오브젝트와 인스턴스 변수는 힙 영역을 할당받습니다. 이후 함수가 리턴되어 사용이 끝나면 해당 스택 프레임이 하나씩 제거되며 그에 따라 레퍼런스 카운팅이 0이 되면 사용되지 않는 죽은 메모리를 가비지 컬렉터가 삭제하고 메모리를 재사용할 수 있게 됩니다.
💥 핵심 개념
메모리를 관리한다는 것은 결국 할당과 제거의 싸이클을 돈다는 것
파이썬은 동적메모리 할당을 한다 -> 메모리 매니저가!
프라이빗 힙은 몰까 -> 진짜로 우리한테 비공개라서??
가비지 컬렉션 - 레퍼런스 카운터
💽 메모리 구조
| 메모리 영역 | |
|---|---|
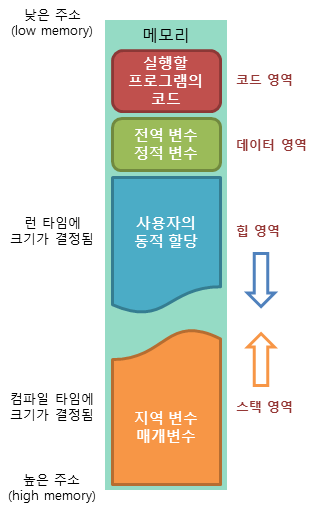 | - text 영역(code): 실행할 프로그램의 코드가 저장됨 cpu가 여기에 저장된 명령어를 하나씩 가져가서 처리함 - data 영역: 전역, 정적 변수를 저장. 프로그램 시작과 함께 할당되고 종료되면 소멸됨 - stack 영역: 지역변수 및 매개변수를 저장. 함수의 호출과 함께 할당되며 함수의 호출이 완료되면 소멸 → data와 stack은 컴파일 타임에 메모리 크기가 결정됨 - heap 영역: 동적 할당으로 생성되는 공간. 공간의 크기는 런타임 때 결정됨 ex. 게임에서 유저가 접속시에 동적할당으로 메모리를 사용해야 효율적으로 메모리를 관리할 수 있음 계속 유저 메모리를 잡아두면 메모리가 낭비됨 |
🫣 프로세스의 메모리 공간에는 힙, 스택, 코드, 데이터가 있는데..
❓동적 메모리 할당을 위해 프로세스에 힙이 존재한다고 보면 되나요??
❓정적 메모리 할당을 위해 프로세스에 스택이 존재한다고 보면 되나요??
❓파이썬의 객체지향적인 특성이 레퍼런스를 이용한 메모리 관리를 유도하는 게 맞는지?
💽 메모리 할당
- C에서의 동적할당 API를 호환하여 사용함 - free(), malloc(), calloc(), realloc()
- 동적할당 & 메모리 매니저
- 파이썬은 모든 것이 객체이므로 동적 할당이 파이썬 메모리 관리의 기초가 됨.
사용자가 스스로할 수 없고 메모리 매니저가 메모리 관리를 자동으로 해줌 - 메모리 매니저가 포인터를 움직여 힙 영역의 메모리 할당 범위와 내부 버퍼를 조절한다.
- 메모리 관리자는 사용된 메모리를 인터프리터로 리턴하고 os로 리턴하지 않아서 os가 메모리 관리에 신경을 쓰지 않아도 돼서 os의 과부하를 줄여준다고 표현하는 듯❓
- 파이썬은 모든 것이 객체이므로 동적 할당이 파이썬 메모리 관리의 기초가 됨.
- private heap❓
모든 객체와 데이터 구조를 가짐
정적 할당은 컴파일 타임에 일어나고 동적 할당은 런타임 실행시 일어나는데 파이썬은 한줄씩 읽고 실행되는 인터프리터 언어라서 컴파일 타임은 따로 없지만 컴파일을 하면서 정적 할당을 수행하고 런타임때? 명령어를 실행하면서? 동적할당을 합니다.
파이썬 코드를 실행하면 한줄씩 컴파일과 런타임이 인터프리트가 진행되는데 이 컴파일 때 정적메모리가 할당되고 런타임때 동적메모리가 할당됩니다.
x = 10
print(type(x)) #<class 'int'>
y = x
if (id(x)==id(y)): #True
print("x 와 y 는 같은 객체를 가리킨다")💽 메모리 제거
스택이니까 가장 나중에 저장된 함수/변수가 가장 먼저 삭제됨
레퍼런스 카운팅을 이용해 메모리 관리(비우기)를 한다
가비지 컬렉터: reference count == 0 일 때 죽은 메모리가 되어 가비지 컬렉터가 메모리에서 해당 객체를 삭제함
💽 순환 사이클 → 답..
인터프리터가 자동으로 메모리를 할당하지 않고 메모리 매니저가 포인터를 사용해 힙의 영역의 크리를 조정함으로써 해당 코드(변수나 함수) 호출시 메모리를 사용하고 리턴/중지시 메모리 삭제 == OS의 과부하를 줄여줌
-> 다른 언어는 누가 메모리를 자동으로 할당해?
메소드와 변수는 스택 메모리에 작성 --> 파이썬도 정적할당이 발생한다는 거지????
메소드와 변수가 작성 될 때마다 스택 프레임이 셍성됨 → 메소드가 리턴 될 때마다 자동으로 제거됨
오브젝트 및 인스턴스 변수는 힙 메모리에 작성됩니다.
변수와 함수가 리턴되면 가비지 컬렉터에 의해 제거됩니다.
+ 추가되면 좋을 내용...
레퍼런스를 사용함으로써 메모리 사용을 최적화한다.
메모리 할당에 있어 OS의 과부하를 줄여준다.
integer obj 10 is created in memory
its reference is assigned to variable 'x'
'x' and 'y' are refering to the same obj
python optimizes memory utiliztion by locating the same obj reference to a new variable if obj with the same value already exists.
by underlying os, every process is allocated with some memory
https://www.youtube.com/watch?v=arxWaw-E8QQ
🫣 일반적인 메모리 할당 개념
- 정적 메모리 할당 :
정적 메모리를 구현하기 위해서 stack 자료구조를 사용
프로그램에 사용할 데이터를 stack에 저장해 두었다가 하나씩 꺼내어 사용 -> stack frame이 쌓이고 제거되는 형식으로 사용됨
프로그램이 끝날 때까지 없어지지 않음
높은 주소 → 낮은 주소 순으로 할당
- 동적 메모리 할당 (dynamic allocation)
메모리를 효율적으로 사용할 수 있게 함
동적 메모리를 구현하기 위해서 heap 자료구조를 사용
정적과 달리 데이터가 나중에 필요하지 않으면 메모리에서 제거를 할 수 있습니다.
낮은 주소 → 높은 주소 순으로 할당
https://woochan-autobiography.tistory.com/867
https://pro-jy.tistory.com/38
특수 메서드
- __init__( ), __str__( ), __repr__( ) 이란?
__init__( )는 객체를 생성할 때 가장 먼저 실행되는 초기화/생성자 메서드
__repr__은 해당 객체를 인간이 이해할 수 있는 표현으로 나타내기 위해 객체의 문자열 형을 반환한다. 개발자를 위한 상세한 표현
__str__는 print문 등에서 자료형간의 호환을 위해(인터페이스처럼) 객체의 문자열 형을 반환한다.
특수 메서드: 메서드 이름 앞뒤에 두개의 밑줄이 붙어있는 메서드로 특수한 용도로 사용한다. == 매직/스페셜 메서드
str( ),repr( )함수는 해당 인스턴스의 __repr__,__str__메서드를 실행한다.
클래스 안에 __repr__( )나 __str__( )가 없으면 객체의 클래스 이름과 메모리의 주소를 <> 안에 써서 반환한다
ex. 셸에서 변수의 이름을 입력하고 엔터를 치면 변수의 값이 호출됨 == 해당 변수의 repr 메서드가 호출된 것
str()과 repr() 함수는 특수메서드를 사용해 클래스로부터 문자열을 생성하고
repr( )는 때때로 개발자를 위한 상세한 내용이 추가되어 표현된다.
https://wikidocs.net/84418
https://shoark7.github.io/programming/python/difference-between-__repr__-vs-__str__
https://datascienceschool.net/01%20python/02.12%20%ED%8C%8C%EC%9D%B4%EC%8D%AC%20%EA%B0%9D%EC%B2%B4%EC%A7%80%ED%96%A5%20%ED%94%84%EB%A1%9C%EA%B7%B8%EB%9E%98%EB%B0%8D.html#id8
🫣 파이썬에서 언더스코어(_)란?
언더스코어 == 언더바 == 아스키 95번
네이밍 컨벤션에서 내장함수와의 중복을 피하기 위해/ for문에서 할당하고자하는 변수가 없을 때 등등 사용한다
두개의 언더바는 특수메서드에서 사용하므로 사용하지 않는다
프로그래머스 문제풀기
➡️2016년
def solution(a, b):
days=[31,29,31,30,31,30,31,31,30,31,30,31]
week=['THU','FRI','SAT','SUN','MON','TUE','WED',]
idx=(sum(days[:a-1])+b)%7
return week[idx]문자열/리스트 슬라이싱은 [n:m]일 때 index(m-1)까지만 나온다 ⭐
import datetime
def solution(a, b):
days=['MON','TUE','WED','THU','FRI','SAT','SUN']
return days[datetime.date(2016,a,b).weekday()]datetime의 weekday()를 쓸 때는 days를 정렬할 때 꼭 월요일부터 해줘야한다
