
SQL 성능 향상
인덱스
- 인덱스 구조
B-Tree: root(부모)→ branch(자식)→ leaf(자식)→ 디스크 저장소- 디스크를 읽는 건 메모리보다 훨씬 성능이 떨어짐
디스크 저장소 엑세스를 줄이고 root-leaf 왕복 횟수를 줄이는 것이 핵심
- 디스크를 읽는 건 메모리보다 훨씬 성능이 떨어짐
- 인덱스가 많아지면 명령어 수행시 중복하여 수정이 필요하여 성능 저하를 유발할 수 있음
- 인덱스도 공간을 차지함
- 옵티마이저가 잘못된 인덱스를 탈 수 있음
인덱스를 만드는 기준
-
많은 양의 데이터에 엑세스하는 경우 인덱스를 이용해서 엑세스하면 이후에 랜덤 엑세스가 발생하여 성능이 저하됨 → 인덱스 없이 전체 엑세스하는 경우가 더 빠름
ex) 1만개의 단어. 5000개의 단어를 찾는다. 한 페이지에 단어는 20개.
→ 총 페이지수는 500이고 한 페이지에 평균 10개의 단어가 있을거라고 추정 가능
→ 인덱스를 타게되면 한 페이지를 10번씩 엑세스하게 됨
→ 인덱스를 타지 않으면 한페이지를 한번만 엑세스해서 10개의 단어를 모두 찾을 수 있음즉, 찾고자하는 데이터의 수가 적다면 인덱스를 타는 게 더 효율적일 수 있지만 많다면 전체 테이블을 엑세스하는 게 더 SQL의 성능을 보장하는 방법
- 많은 양의 데이터? 해당 테이블의 3-5%가 기준
테이블이 커진다면 당연히 비율은 더 낮아짐
- 많은 양의 데이터? 해당 테이블의 3-5%가 기준
-
복합 인덱스(결합 인덱스)
칼럼의 분포도가 좋은 칼럼을 첫번째로 설정하는 게 원칙= 분포도가 좋다는 건 유니크하다는 것. 카디널리티(중복된 수치)가 크다는 것
ctex) 만약 카드번호가 모두 1로 시작하는 경우 카드 번호 인덱스를 만들어서 1로 시작하는 카드번호 값에 엑세스한다면 분포도가 안좋은 것. 카드 번호를 풀로 써서 그 값에 엑세스한다면 그건 분포도가 좋음.그럼 어떤 걸로 순서를 결정해야하나?
연산자 → 점조건 칼럼이 선행칼럼이 되도록- 점조건: =, in
- 선분조건: 나머지
이
-
복합인덱스의 첫번째 컬럼은 쿼리에 사용되어야 해당 인덱스를 탄다
인덱스 칼럼 값은 이름 그대로 사용되어야 한다. 칼럼 타입이 달라지면 조회가 안됨.
페이지: MySQL에서 데이터가 디스크에 저장되는 기본 단위. 인덱스도 페이지 단위. 페이지는 16KB
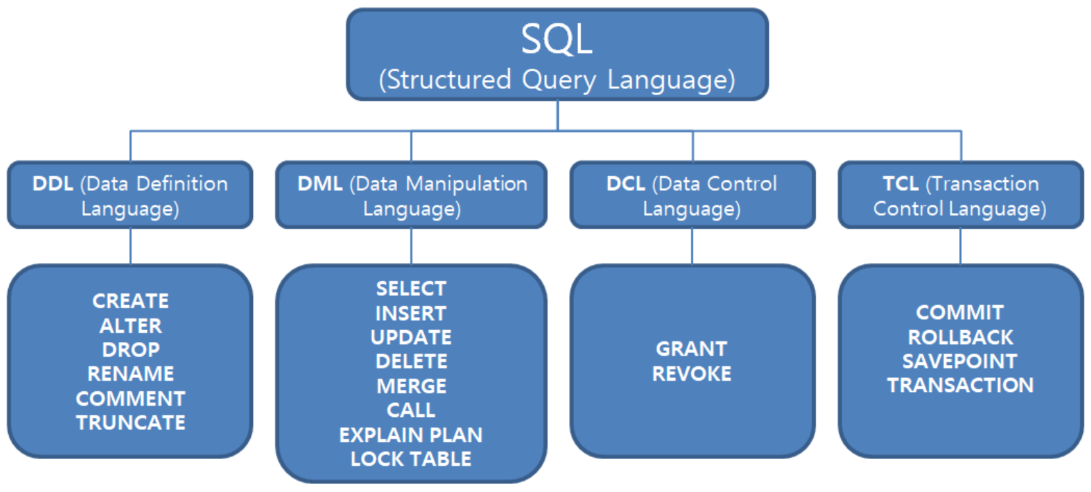
- DML 명령어는 자동으로 COMMIT되지 않는다. 조작하는 테이블이 메모리 버퍼에 있기때문에 명령어를 반영되려면 커밋하여 트랜잭션을 종료해야한다. SQL서버의 경우 AUTO COMMIT된다
- DML은 SELECT, INSERT, UPDATE, COMMAND
이중 SELECT는 따로 빼서 DQL(Query)이라고도 함- DDL은 DB의 구조를 정의하는 데 사용되며 AUTO COMMIT 된다
- TRUNCATE: 테이블 레코드 및 테이블의 저장공간까지 모두 삭제
- DCL: 데이터 권한 부여 AUTO COMMIT
- TCL: 트랜잭션 제어 언어
옵티마이저
SQL쿼리를 효율적으로 처리할 수 있도록 해주는 DBMS 엔진
- 규칙 기반 옵티마이저
- 사전에 정의된 규칙을 기반으로 예상이 가능하고 인덱스를 가장 우선하여 사용함
- 예측 통계정보를 무시함
- 비용 기반 옵티마이저
- 최소 비용을 계산해서 실행계획을 수립함 통계 정보를 사용하여 예측 제어가 어렵지만 현실 요소를 적용함
- ALL_ROWS : ORACLE의 SQL기본 모드로 전체 SQL문 실행 결과를 빠르게 처리하는데 최적화 된 실행계획을 세우는 모드로 통계정보가 없더라도 동작함
프로그래머스 문제풀기
➡️문자열 다루기 기본
def solution(s):
if len(s)==4 or len(s)==6:
for i in s:
try:
int(i)
except:
return False
return True
else:
return False -
try: 실행할 구문
except (특정 에러): (특정)에러 발생시 실행할 구문 -
if 조건문에서 논리 연산자를 사용할 때
len(s)==4 or 6:이렇게 쓰면 오류가 나는 건 아니고- 비교연산자의 우선순위가 논리 연산자의 우선순위보다 높기때문에
len(s)== 4인 경우 True가 나오고
len(s)== 4가 아닌 경우 or 뒤의 숫자가 나온다 (0이더라도 0이 나옴)
- 비교연산자의 우선순위가 논리 연산자의 우선순위보다 높기때문에
-
or은 bool type연산자이기때문에 len(s)가 숫자고 4도 숫자고 6도 숫자라는 관점에서 저 문장을 해석해서 len(s)가 true 또는 true냐가 됨 0 이 아니면 true기때문에이때는 왜 이렇게 나왔지??
len(s)==4 or len(s)==6:이렇게 써야 내가 의도한대로 앞뒤 둘중에 true가 있냐가 된다
➡️소수 만들기
from itertools import combinations
def solution(nums):
count = 0
for a, b, c in combinations(nums, 3):
if len([(i, (a+b+c)//i) for i in range(1, int((a+b+c)**0.5)+1) if (a+b+c) % i == 0]) == 1:
count += 1
return countitertools의 combinations로 간단하게 풀 수 있다
combinations(범위, 범위 안에서 조합할 요소의 갯수)
def solution(nums):
count = 0
nums=list(set(nums))
print(nums)
for idx, i in enumerate(nums[:-2]):
for j in nums[idx+1:-1]:
for k in nums[nums.index(j)+1:]:
total = i+j+k
if len([(x, total//x) for x in range(1, int(total**0.5)+1) if (total) % x == 0]) == 1:
print(i,j,k)
count += 1
return count조합을 실제로 해봤는데 range를 사용할 건지 containment를 사용할건지를 확실하게 정리하지 않고 들어가서 범위 부분에서 많이 헷갈렸던 것 같다
- i,j,k를 인덱스로 쓸거면 범위를 range(len())로 해줘야하고
- i,j,k를 요소로 쓸 거면 범위를 리스트 자체로 해야하는데 리스트를 슬라이스 하다보니까 인덱스를 썼다
