Node.js에서 백준 입력
두가지 방법이 있다. 파일을 온전히 읽어오는 readFile방식과 한 줄씩 읽어오는 readline방식.
하나씩 알아보자.
readFile
//example.txt
12ab112ab2ab
12ab
//index.js
const fs = require("fs");
const input = fs.readFileSync("example.txt", "utf-8");
console.log(input);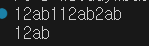
readFile은 비동기 방식이라 readFileSync를 활용했다. 파일 하나를 통째로 읽어온다.
참고로 인코딩을 지정해주지 않으면 버퍼객체가 나온다.

readline
readline은 말 그대로 한 줄씩읽어들여온다.
fs모듈을 이용한 건 파일을 먼저 읽어와야하기 때문이다.
const readline = require("readline");
const fs = require("fs");
const rl = readline.createInterface({
input: fs.createReadStream("example.txt"),
output: process.stdout,
terminal: false, //터미널에 한 줄씩 자동으로 콘솔을 찍어준다. 기본값은 true다.
});
rl.on("line", function (line) {
console.log(`한 줄씩 나옵니다${line}`);
});
rl.on("close", function () {
process.exit(); //노드 실행 종료
});
두 방식 다 백준에서 사용할땐 경로를 달리해주어야한다.
//readFile
const input = fs.readFileSync("/dev/stdin", "utf-8");
//readline
const rl = readline.createInterface({
input: process.stdin,
output: process.stdout,
});
//조건문을 활용하면 조금 더 편하다. 참고로 백준 코드실행 환경은 linux다.
const path = process.platform === 'linux' ? '백준경로' : '내 파일 경로'포스팅하게 된 이유(메모리 초과)
예제가 대충 1천만줄 정도 된다고 가정해보자.
잘보면 readfile은 한 파일을 전부 읽어오기때문에 split('\n')메서드로 분리시, 1천만길이의 배열이 생성된다.
이 문제의 메모리 제한은 256MB다.
이때 만약 문자열 당 길이가 대충 10문자라고 가정하면
문자열당 메모리 소모량: 10글자 x 2 바이트 = 20 바이트
배열 길이: 10,000,000
전체 배열의 메모리 소모량: 20 바이트 * 10,000,000 = 200,000,000 바이트 = 대략 200 MB
만큼 소모하게된다.
당연히 배열 뿐 아니라 각종 변수, 함수 등을 선언해야하기에...주어진 256MB는 그냥 넘기게된다.
이때 필요한게 readline모듈을 이용하여 한 줄씩처리하는 방법이다.
잘 숙지해서 메모리초과를 띄우는 일이 없도록 하자
JS의 메모리 관리
메모리 얘기를 하니까 JS가 어떻게 메모리 관리를 하는지 궁금해졌다. GC(가비지 컬렉션)라는 기능을 사용하여 일정시간마다 청소하는 건 알고있는데, 어떤 원리로 돌아가는걸까?
한번 메모리 관리에 대해 자세히 알아보자
memory lifecycle
메모리의 생명주기는 대부분의 프로그래밍 언어에서 비슷하다!
- 필요할때 할당한다
- 할당된 메모리를 사용(읽기, 쓰기)한다
- 필요없어지면 해제!
직관적이고 명시적이다. 하지만 JS에서 첫 번째와 마지막생명주기는 저수준언어에서만 명시적으로 작동한다.
따라서 JS에서는 사용자가 임의로 할당,해제를 할 수 없다.
그래서 언제 해제하는가?
사실 메모리 관리의 대부분은 해제타이밍을 맞추지 못해 문제가 발생한다.
왜냐하면 할당된 메모리가 더 이상 필요 없을 때를 알아내기가 가장~~어렵기 때문이다. => 비결정적 알고리즘이라고도 한다.
저수준 언어라면 3번의 필요 없어지면 해제를 명시적으로 사용할 수 있겠지만, JS는 그조차 불가능하다.
따라서 언어차원에서 메모리 할당의 해제를 지원해주는데, 이를 GC(가비지 컬렉션)이라 부른다.
Garbage Collection
비결정적 알고리즘을 어느정도 해소해주는 것이 바로 가비지 컬렉터들이다.
가비지 컬렉터들은 보통 특정한 알고리즘을 이용하여 작동하는데, 핵심 개념은 참조에서 비롯된다.
가령 A라는 메모리를 통해 B라는 메모리에 접근할 수 있다면, 'B는 A에 참조된다'라고 할 수 있다.
이를 차용하여 아주 간단하게 구현 된 것이 초창기 알고리즘이 Reference-counting이다.
GC 알고리즘 1) Reference-counting
직역해도 알 수 있듯 참조를 카운팅하는 기법이다.
let x = {
a: {
b: 2,
},
};
//x가 참조, x.a가 참조. x, x.a(2개)
let y = x;
// x객체를 y변수에 얕은복사. x, x.a, y(3개)
x = 1;
// x를 1로 재할당. y, y.a(2개)
let z = y.a;
// y, y.a, z(y.a) (3개)
y = "mozilla";
// y를 재할당. 하지만 z(y.a)의 참조가 남아있다.
z = null;
// 남아있던 z의 참조마저 지웠다. 이제 가비지컬렉터가 메모리 할당을 해제한다.언뜻보면 그럴싸한데, 순환 참조를 다루는 순간 어그러진다.
function f() {
const x = {};
const y = {};
x.a = y; //x.a에 y를 참조 (y참조개수 2개)
y.a = x; //y.a에 x를참조 (x참조개수 2개)
return "azerty";
}
f();
//함수가 콜스택에 오르고, 실행되고, 함수의 스코프가 사라져 메모리 할당을 해제해야한다. 하지만 x객체의 참조와 y객체의 참조는 아직도 2개이므로 Reference-counting알고리즘은 이를 해제하지 않는다고 판단, 메모리 누수의 원인이 된다.
GC 알고리즘 2) Mark-and-sweep
이전 알고리즘이 참조 카운팅을 기반으로 했다면, Mark-and-sweep알고리즘은 reachability(도달 가능성)을 기반으로 한다.
무엇이 어디에 도달한다는 걸까?
- 현재 함수의 지역 변수, 매개변수
- 중첩 함수의 체이닝에 있는 함수에서 사용되는 변수, 매개변수(클로저)
- 전역 변수
- 기타...
이런 값들을 root라고 부른다. 무엇에 해당하는게 root다.
즉, root에서 참조 가능한 값이 결국 도달 가능한 값이 된다.
현재 모든 최신엔진은 이 Mark-and-sweep알고리즘을 통해 메모리를 해제한다.
순환참조의 예시를 다시 보자.
function f() {
const x = {};
const y = {};
x.a = y;
y.a = x;
return "azerty";
}
f();
//함수의 스코프가 사라졌다. 클로저도 없다. 즉 x,y는 도달 불가능해진 상태다.참조 카운팅이었다면 메모리가 계속 남아있었겠지만, 다행히도 Mark-and-sweep알고리즘 덕분에 메모리 누수를 피할 수 있었다.
기타 GC 최적화 기법들
Mark-and-sweep알고리즘을 기반으로 가비지 컬렉팅을 하되, 조금 더 빠르게 컬렉팅 하는 기법들이 JS엔진에 존재한다.
- Generational collection(세대 별 수집): 새로운, 오래된객체로 분류한다. 객체의 상당수는 생성이후 제 역할을 빠르게 수행하여 금방 쓸모가 없어진다. 이런 객체는 새로운 객체라고 판별하여 공격적으로 메모리에서 할당을 해제한다. 살아남은 객체들을 오래된 객체라 여기며 가비지 컬렉터의 감시 비중을 낮춘다.
- Incremental collection(점진적, 증분적 수집): 앱의 크기가 클수록 방문해야하는 객체의 갯수도 늘어난다. 따라서 가비지 컬렉션을 부분부분 적용하여 여러개로 분산시킨다.
- Idle-time collection(유휴시간 수집): CPU가 idle(유휴)상태일때만 수집한다.
번외) WeakMap과 WeakSet
길어져서 다음편으로 쪼갰습니다...!
