AST(Abstract Syntax Tree, 추상구문트리)

추상구문트리란 아주 축약해서 말하자면, 사용자가 작성한 소스코드를 트리로 표현한 것이다.
참고로 이번 파트에서는 깊게 배우지 않고 블랙박스 공부법을 활용하여 아~ 이런 기능이구나 하고 짚고 넘어갈 것이다!
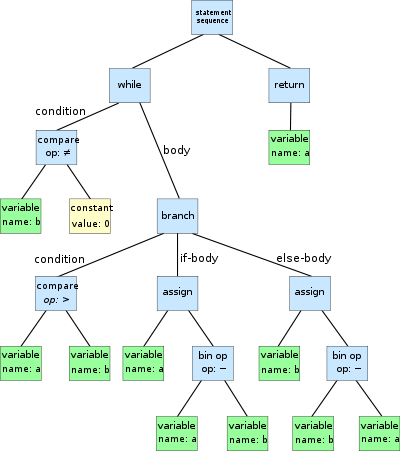
위 예시는 유클리드 호제법을 트리로 표현한 것이다. 감히 추측컨대 아마 프로그래밍 언어에서 의미 있는 단어의 최소기준으로 나눈 게 아닐까?
예시로 한번 확인해보자.
JS의 추상구문
이 사이트에서 JS를 AST로 실시간 변환하는 모습을 볼 수 있다. 아주 간단한 예시를 보자.
단순히 a와 b를받아 더한 값을 반환하는 함수다.
const add = (a,b) => a+b;이를 추상구문트리로 바꾸면 다음과 같다.

주목할 점은 body부분이다.

계단형식으로 이루어져있는 추상구문트리를 계속 열어젖히면 생각보다 훨씬 많은 정보를 갖고있는 걸 알수있다.
아무튼, 선언한 함수의 정보와 환경 정보등을 갖고있다는 건 알겟다. 이걸 갑자기 알아야하는 이유는 뭘까?🤔
세부적인 컴파일 단계(어셈블리어로 변환 전 까지)
왜냐면 컴파일단계중 AST를 이용하는 과정이 존재하기 때문이다.
컴파일은 결국 소스코드를 기계어로 번역하는 과정이기에, 먼저 소스코드의 어휘를 분석해야한다.
출처:https://www.toptensoftware.com/blog/how-to-write-a-compiler-2-tokenization/

어휘를 분석하여 의미있는 최소단위로 먼저 나눈다. 이를 Tokenization(토큰화)라고 한다.
그다음 토큰화를 이용하여 만들어진 토큰들을 갖고 Parse Tree(구문 분석 트리)를 제작한다. (이때 문법적 오류를 검출한다.)
//이런느낌...
ForStatement
├── 'for'
├── '('
├── VariableDeclaration
│ ├── 'let'
│ ├── VariableDeclarator
│ │ ├── Identifier('i')
│ │ └── Literal(0)
├── ';'
├── BinaryExpression
│ ├── Identifier('i')
│ ├── '<'
│ └── Literal(3)
├── ';'
├── UpdateExpression
│ ├── Identifier('i')
│ └── '++'
├── ')'
└── Statement
└── ...참고로 parse tree를 만들어주는 과정을 Parser가 진행해준다!
이후 문법 오류 검출이 끝났으면 위의 구문 분석트리를 가지고 Abstract Syntax Tree(추상 구문 트리)를 생성한다.
ForStatement
├── init: VariableDeclaration
│ ├── kind: 'let'
│ └── declarations: [
│ └── VariableDeclarator
│ ├── id: Identifier('i')
│ └── init: Literal(0)
│ ]
├── test: BinaryExpression
│ ├── left: Identifier('i')
│ ├── operator: '<'
│ └── right: Literal(3)
├── update: UpdateExpression
│ ├── operator: '++'
│ └── argument: Identifier('i')
└── body: BlockStatement
└── body: [
└── ... (loop body statements)
]둘의 차이점은 Parse tree는 굉장히 구체적이다. 괄호, 중간노드등을 모두 갖고있다.(토큰)
그에비해 Abstract Syntax Tree는 조금 더 추상적이다. 괄호도 없으며 불필요한 중간노드도 없다.
이후 최적화, 중간표현, 어셈블리등의 과정을 거쳐 종국에 기계어로 번역되고 CPU에 도달한다.
멋지지 않은가?😮
V8엔진이 JS코드를 CPU에게 전달하기까지
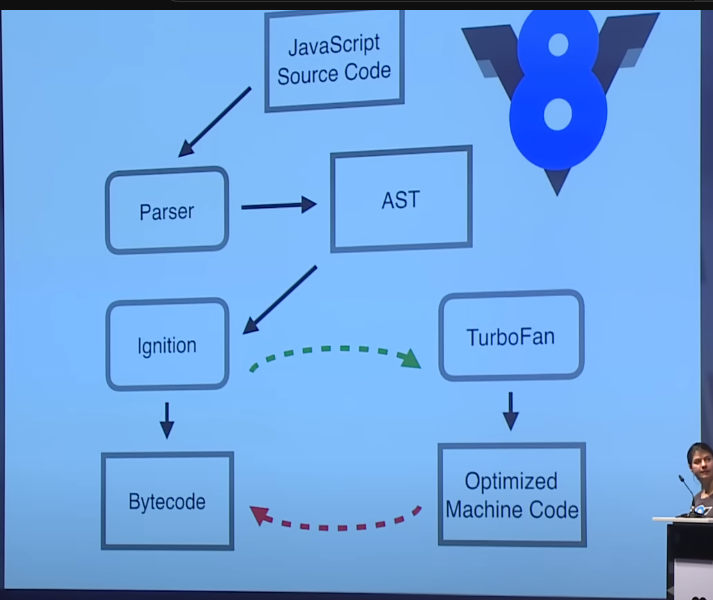
출처 : https://www.youtube.com/watch?v=p-iiEDtpy6I (JS Conf 2017)
요약하자면 다음과 같다.
- 소스코드를 받아와서 Parser에 넘긴다. 첫 목차에서 설명했듯 이는 Parse tree를 만들기 위함이다.
- AST로 변환한다. (이때 Parse tree를 거치는지 설명되어있진 않음)
- Ignition(인터프리터)에게 넘겨 AST를 바이트코드(중간표현)으로 만든뒤 실행!
3-1. 이 중 자주 사용되는 코드는 TurboFan이라는 곳에 보내진다.
3-2. Turbofan에서 기계어 최적화를 한다.
3-3. 재컴파일한 코드를 바이트코드로 변환
결국 스크립트 언어인 JS도 인터프리터만 사용하는 게 아닌 컴파일과 최적화과정을 거쳐 CPU에 명령을 전달하게 된다.
이는 당연한 수순이다. 순수한 인터프리터(pure interpreter)와 컴파일러의 속도차이는 천지차이일테니...
여기서 더 깊게 들어가 알고싶다면 V8 공식 홈페이지에서 볼 수 있다.
아직 깊은 지식 기반이 빈약하기에 작동 과정을 어느정도 이해했다는 데 만족하겠음.😓
나중에 취뽀해서 일하다가...궁금해지는 시점이 또 오지 않을까?!
번외) 이전편에서 언급된 JIT

V8엔진 컴파일 과정을 보니 JIT의 기능과 똑 닮아있다. 인터프리터+컴파일 방식 혼합에 자주쓰이는 코드 캐싱까지.
참고로 Java도 바이트코드 => 기계어 번역시 JIT 컴파일러를 사용한다고 한다.
최근에는 웹 어셈블리라고해서 아예 인터프리터를 거치지 않고 컴파일되는 속도를 가진 언어가 등장했다는데...
뿐만아니라 CSR에서 SSR(기존에 하던 MPA방식의 렌더링과 좀 다르지만...)로 가거나 프론트에서 쿼리를 짜는 등 과거의 유산을 재해석해 프레임워크, 라이브러리를 업데이트하는 모습이 종종 보인다.
역시 레거시라도 배울점은 충분히 많다!
느낀점
본 포스팅을위해 컴파일러, 인터프리터, 중간표현, JIT, AST를 알아보았다. 덕분에 몰랐던 CS지식이 차곡차곡 쌓여서 좋았다.
여담이지만 최근에 전문가와 비전문가의 차이에 대해 관한 영상을 봤다. 전문가들은 패턴을 학습하여서 하나의 청크화 하여 지식을 저장한다는데, 예전 포스팅에서 언급했던 지식끼리의 연결과 비슷한 느낌 아닐까?
아무튼 궁금증 해결!
