req.body is undefined
문서를 새로 생성하는 로직은 다음과 같다.
async function createDocumentController(req, res) {
const { parent: parentId, title } = req.body;
const newDocument = await createDocument({ parentId, title });
res.writeHead(201, CORS_HEADER);
return res.end(JSON.stringify(newDocument));
}요청의 body에서 제목과 부모 문서의 id를 추출 후, service계층으로 넘긴다.
Post Man을 이용해서 테스트를 해보자.
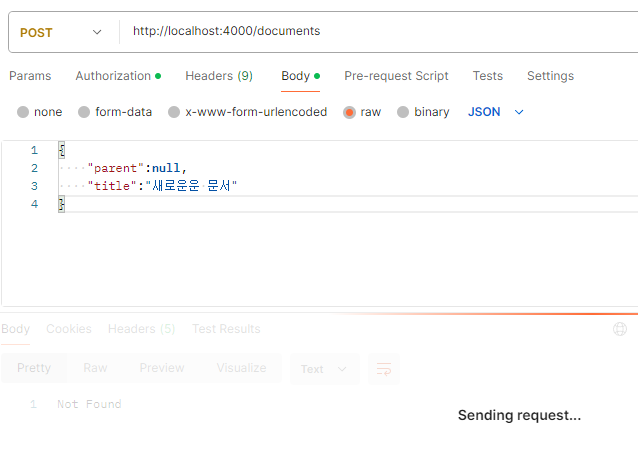
요청을 보냈더니 응답이 없다.
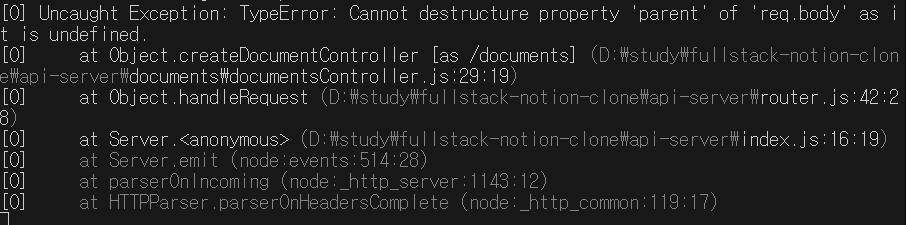
서버측 로그를 보니 req.body를 읽어올 수 없는 문제같다.
왜 이런일이 발생한걸까?
req의 타입?
req는 http.createServer의 콜백에서 첫 번째 인자로 전달되는 요청 객체다.
이 req의 타입을 확인해보면 IncomingMessage라는 것을 알 수 있다.
function createServer<
Request extends typeof IncomingMessage = typeof IncomingMessage,
Response extends typeof ServerResponse<InstanceType<Request>> = typeof ServerResponse,
>(requestListener?: RequestListener<Request, Response>): Server<Request, Response>;해당 클래스를 타고가보면...
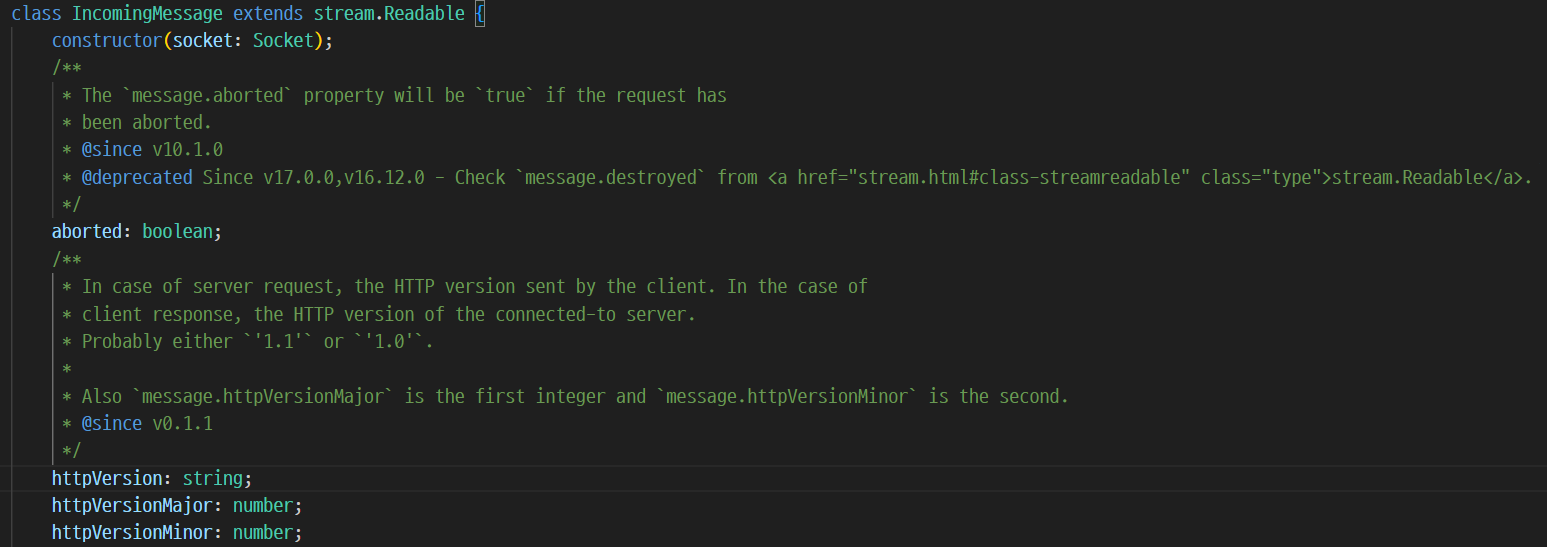
200줄쯤 되는 클래스와 마주하게된다. 해당 IncomingMessage는 stream.Readable클래스를 상속받는다.
또한 공식문서에 따르면:
Instances of http.IncomingMessage are created by http.Server or http.ClientRequest and passed as the first argument to the 'request' and 'response' event handlers.
It implements the Readable Stream interface.
즉, http요청은 node에서 읽기 가능한 스트림이다.
스트림이란 뭘까?
Stream이란?
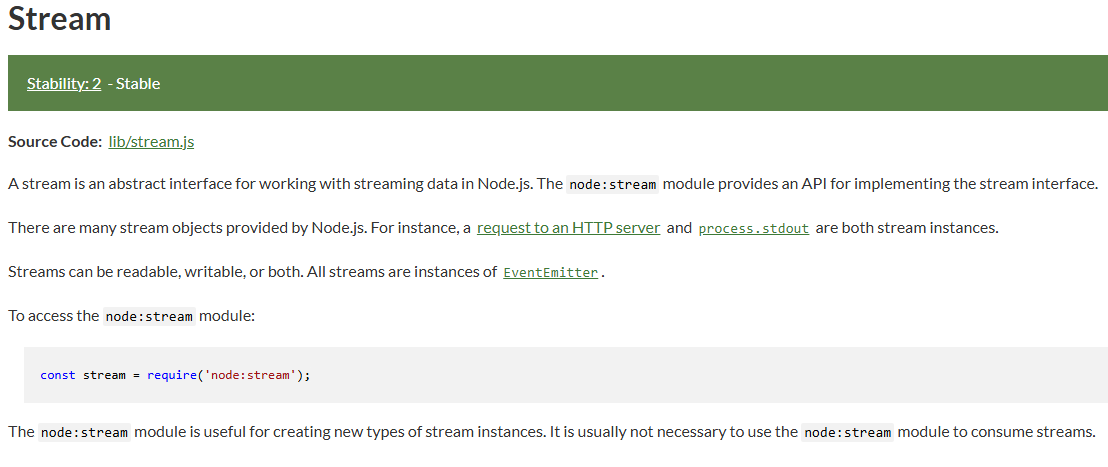
Stream은 Node.js에서 스트리밍 데이터로 작업하기 위한 추상 인터페이스라고한다.
또한 HTTP서버에 대한 요청, process.stdout모두 스트림 인스턴스라고 한다.
이제 Node내 클래스 정의 말고 단어의 정의를 살펴보자.
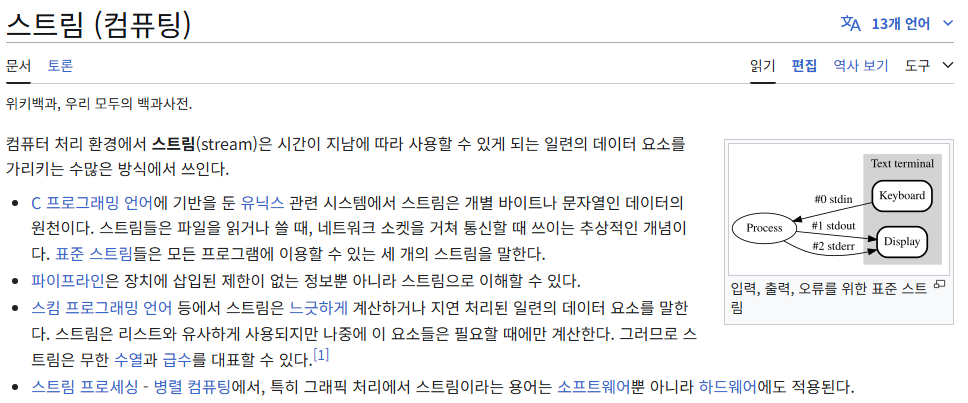
즉 스트림이란 데이터터가 작은 청크로 나뉘어 전송되는 방식이다. 한 번에 모든 데이터를 보내지 않고 조각을 나눠 순차적으로 보내고 받는 것을 의미한다.
스트림의 주요 특징은 다음과 같다.
- Readable : 데이터를 읽어오기
- Writable : 데이터를 쓰기!
- 데이터가 순차적으로 흐름
그런데 굳이 스트림을 사용해서 데이터를 바로 읽을 수 없게 만든 이유는 뭘까?
스트림을 사용하는 이유
서버에서 데이터를 처리할때 한 번에 모든 데이터를 받는 방식은 사실 비효율적이다.
예를들어 1GB의 파일을 업로드한다고 가정했을때. 파일 업로드라는 행위는 사실 메모리에 데이터를 적재하는 행위다.
데이터를 처리하기 위해선 메모리에 데이터가 있어야 하기 때문이다.
따라서 1GB 데이터를 한 번에 메모리에 올리게 되면 자원낭비, 메모리 초과 등이 발생하게 된다!
그러니까 스트림을 사용하여 데이터를 작은 단위인 chunk로 나누어 순서대로 받게하는 것이다.
buffer
스트림 방식으로 데이터를 가져오려면, 아주 작은 데이터인 Chunk를 하나씩 받아와야한다.
이러한 청크는 일정한 크기의 데이터 모임이 되어 전송되게 되는데, 청크들의 정모를 담당하는 공간을 Buffer라고 부른다.
흔히 말하는 버퍼링(buffering)이 사실 Chunk가 들어오길 기다리는 작업이다.
=> 그러면 스트림으로 들어오는 청크를 버퍼에 담으면 되겠구나?
이번에야말로 req.body를
Node의 공식문서에서도 청크를 모으는 방법을 알려준다.
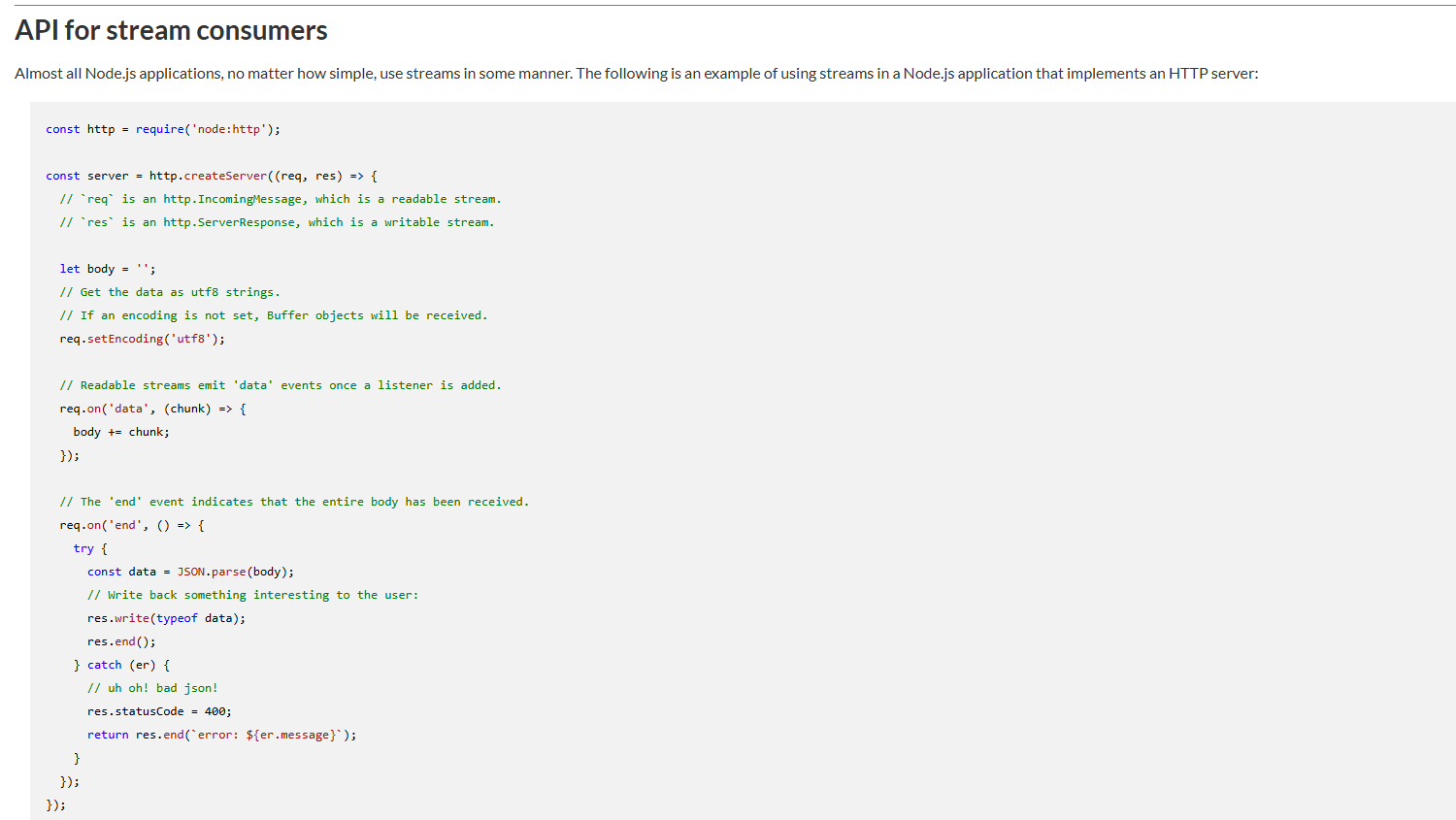
스트림으로 줄줄이 들어오는 청크를 더하고 요청이 끝날때 해당 요청 body부분에 더한 청크를 삽입해준다.
handlerequest:()=>{
//...
//이부분!!
if (method === "POST") {
let body = "";
req.on("data", (chunk) => {
body += chunk.toString();
});
//request의 데이터 스트림이 끝날때 발생하는 이벤트는 비동기다.
//따라서 데이터를 모두 처리 후 라우팅하기위하여 await을 이용해 동기적 코드를 작성함.
await new Promise((resolve, reject) => {
req.on("end", () => {
try {
const buffer = Buffer.concat(body);
req.body = JSON.parse(buffer.toString());
resolve();
} catch (error) {
reject(error);
}
});
});
}
if (routes[method] && routes[method][url]) {
routes[method][url](req, res);
} else {
res.writeHead(404, { "Content-Type": "text/plain" });
res.end("Not Found");
}
}Post Man으로 다시 테스트 해보자!
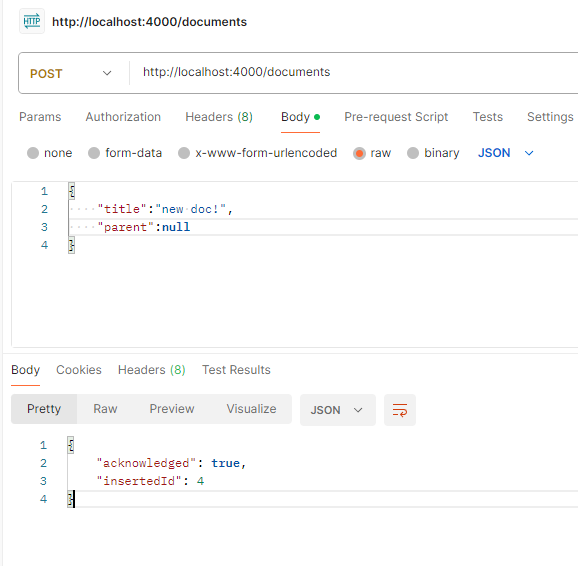
요청이 성공한 것을 볼 수 있다!

서버측 콘솔에도 잘 찍힌다.
Node.js mongodb driver의 타입
const parentDoc = await db
.collection(COLLECTION_NAME)
.findOne({ _id: parentId });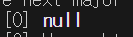
Mongodb Driver를 이용해서 위처럼 문서를 찾으니까 문서가 null로 나옴.
그런데 mongosh로 찾으니까 잘나옴
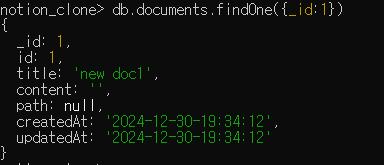
혹시나 싶어서 코드 parentId의 타입을 숫자로 바꿨더니, 잘 작동함.
결론: node.js에서 mongodb driver로 mongodb에 접근할 때, 타입이 중요하다.
