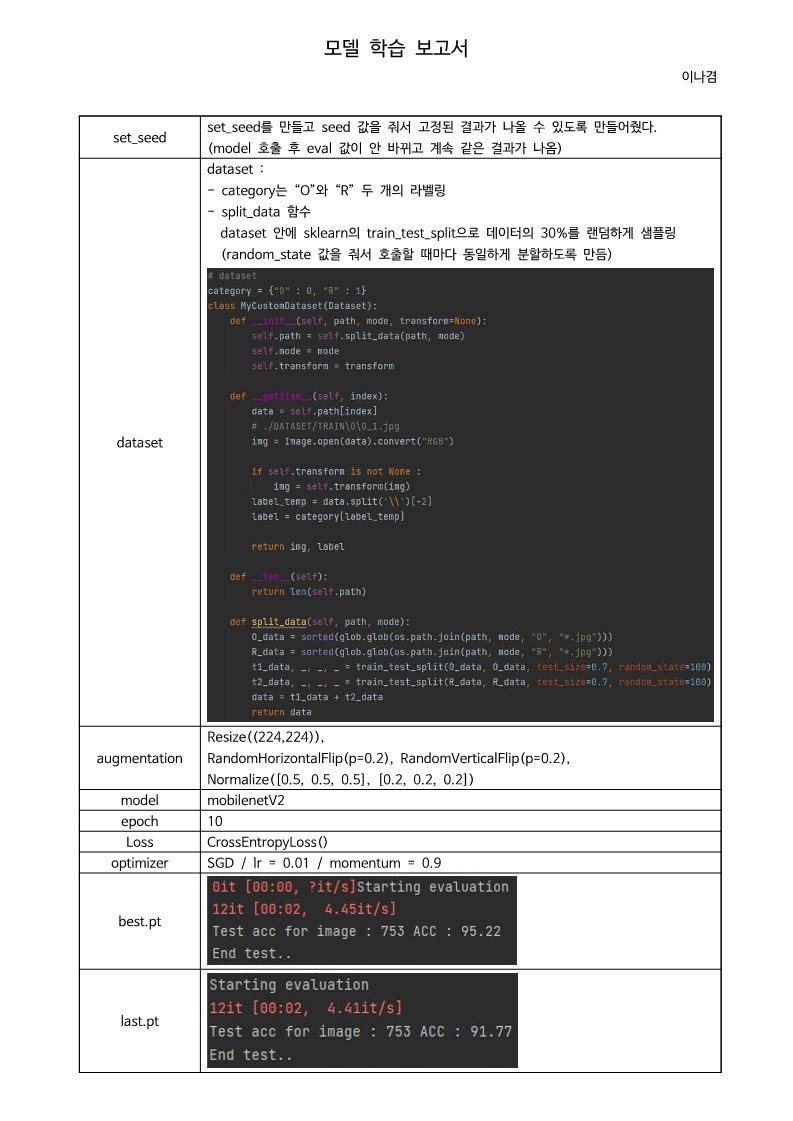
1. 학습내용
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader
import torchvision.models as models
import torchvision.transforms as transforms
import glob
import os
from PIL import Image
from tqdm import tqdm
import numpy as np
import random
from sklearn.model_selection import train_test_split
device = "cuda" if torch.cuda.is_available() else "cpu"
# seed
def set_seed(seed = 7777):
# Sets the seed of the entire notebook so results are the same every time we run # This is for REPRODUCIBILITY
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
np.random.seed(seed)
random.seed(seed)
os.environ['PYTHONHASHSEED'] = str(seed)
# dataset
category = {"O" : 0, "R" : 1}
class MyCustomDataset(Dataset):
def __init__(self, path, mode, transform=None):
self.path = self.split_data(path, mode)
self.mode = mode
self.transform = transform
def __getitem__(self, index):
data = self.path[index]
# ./DATASET/TRAIN\O\O_1.jpg
img = Image.open(data).convert("RGB")
if self.transform is not None :
img = self.transform(img)
label_temp = data.split('\\')[-2]
label = category[label_temp]
return img, label
def __len__(self):
return len(self.path)
def split_data(self, path, mode):
O_data = sorted(glob.glob(os.path.join(path, mode, "O", "*.jpg")))
R_data = sorted(glob.glob(os.path.join(path, mode, "R", "*.jpg")))
t1_data, _, _, _ = train_test_split(O_data, O_data, test_size=0.9, random_state=100)
t2_data, _, _, _ = train_test_split(R_data, R_data, test_size=0.9, random_state=100)
data = t1_data + t2_data
return data
# transform - train, valid
train_transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.RandomHorizontalFlip(p=0.2),
transforms.RandomVerticalFlip(p=0.2),
transforms.RandomAutocontrast(),
transforms.ToTensor(),
transforms.Normalize([0.5, 0.5, 0.5], [0.2, 0.2, 0.2])
])
test_transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize([0.5, 0.5, 0.5], [0.2, 0.2, 0.2])
])
data_path = "./DATASET/"
train_data = MyCustomDataset(data_path, "TRAIN", train_transform)
test_data = MyCustomDataset(data_path, "TEST", test_transform)
# dataloader
train_loader = DataLoader(train_data, batch_size=64, shuffle=True)
test_loader = DataLoader(test_data, batch_size=64, shuffle=False)
# model prepare
def mobilenetV2(num_classes):
model = models.mobilenet_v2(pretrained=True)
num_features = model.last_channel
model.classifier[1] = nn.Linear(num_features, num_classes)
return model
model = mobilenetV2(2)
model = model.to(device)
# hyper parameters
criterion = nn.CrossEntropyLoss().to(device)
optimizer = optim.SGD(model.parameters(), lr=0.0025, momentum=0.9)
lr_scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=4, gamma=0.1)
num_epochs = 10
val_every = 1
save_weights_dir = "./weight"
os.makedirs(save_weights_dir, exist_ok=True)
# train
def train(num_epoch, model, train_loader, test_loader, criterion, optimizer,
save_dir, val_every, device):
print("String... train !!! ")
best_loss = 9999
for epoch in range(num_epoch):
for i, (imgs, labels) in enumerate(train_loader):
imgs, labels = imgs.to(device), labels.to(device)
output = model(imgs)
loss = criterion(output, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
_, argmax = torch.max(output, 1)
acc = (labels == argmax).float().mean()
print("Epoch [{}/{}], Step [{}/{}], Loss : {:.4f}, Acc : {:.2f}%".format(
epoch + 1, num_epoch, i +
1, len(train_loader), loss.item(), acc.item() * 100
))
if (epoch + 1) % val_every == 0:
avg_loss = validation(
epoch + 1, model, test_loader, criterion, device)
if avg_loss < best_loss:
print("Best prediction at epoch : {} ".format(epoch + 1))
print("Save model in", save_dir)
best_loss = avg_loss
save_model(model, save_dir)
save_model(model, save_dir, file_name="last.pt")
def validation(epoch, model, test_loader, criterion, device):
print("Start validation # {}".format(epoch))
model.eval()
with torch.no_grad():
total = 0
correct = 0
total_loss = 0
cnt = 0
for i, (imgs, labels) in enumerate(test_loader):
imgs, labels = imgs.to(device), labels.to(device)
outputs = model(imgs)
loss = criterion(outputs, labels)
total += imgs.size(0)
_, argmax = torch.max(outputs, 1)
correct += (labels == argmax).sum().item()
total_loss += loss
cnt += 1
avg_loss = total_loss / cnt
print("Validation # {} Acc : {:.2f}% Average Loss : {:.4f}%".format(
epoch, correct / total * 100, avg_loss
))
model.train()
return avg_loss
def save_model(model, save_dir, file_name="best.pt"):
output_path = os.path.join(save_dir, file_name)
torch.save(model.state_dict(), output_path)
def eval(model, test_loader, device):
print("Starting evaluation")
model.eval()
total = 0
correct = 0
with torch.no_grad():
for i, (imgs, labels) in tqdm(enumerate(test_loader)):
imgs, labels = imgs.to(device), labels.to(device)
outputs = model(imgs)
# 점수가 가장 높은 클래스 선택
_, argmax = torch.max(outputs, 1)
total += imgs.size(0)
correct += (labels == argmax).sum().item()
print("Test acc for image : {} ACC : {:.2f}".format(
total, correct / total * 100))
print("End test.. ")
"""model load => model test"""
model.load_state_dict(torch.load("./weight/best.pt"))
if __name__ == "__main__":
# train(num_epochs, model, train_loader, test_loader, criterion, optimizer, save_weights_dir, val_every, device)
eval(model, test_loader, device)2. 학습소감
O라벨과 R라벨 둘로 나뉘어질때 다른 Loss 값을 썼었는데, 코드를 수정하면서 오류가 났었다. 이진분류가 될때 Loss를 다른 것으로 바꿀 수 있도록 해야할 것 같다.
test data를 30% 데이터를 split 갯수만큼을 가지고 10%의 train 학습을 한 결과에도 30% test 데이터를 사용해서 돌려야한다.
(이 부분 다시 실행해야한다!)