
1. 학습내용
CNN 전체적인 네트워크 구조
CNN은 convolutional layer와 pooling layer들을 활성화 함수 앞뒤에 배치하여 만들어진다.
- Convolution layer
처음에 2828 크기의 이미지이다.
feature mapping을 얻는다.
(이 이미지를 대상으로 여러개의 필터를 사용하여 결과값을 얻는 것)
이미지를 55 필터로 24*24 매트릭스를 convolution 결과값을 만들어낸다.
결과값에 activation function (활성함수)를 적용한다.
convolution layer = convolution + activation : 활성함수와 짝이 이루어져야 한다.
- activation function은 왜 쓰나?
선형함수인 것을 비선형성을 추가하기 위해 사용한다.
convolution이 비선형이라서 비선형으로 바꾸기 위해 사용한다고 생각하면 된다.
activation function
sigmoid
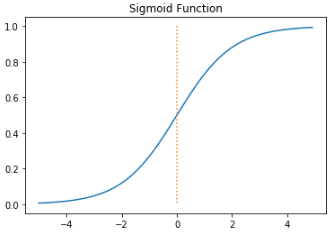
output 값을 0에서 1 사이로 만들어준다. 데이터의 평균은 0.5를 가진다.
vanishing gradient 문제점이 생긴다 : 기울기가 0에 가깝게 되면 gradient가 완전히 사라짐
시그모이드는 처음이나 마지막에 넣는데, 맨 마지막에 하나 넣는것을 지향한다.
시그모이드를 사용하는 경우?
binary classification 경우 출력층 노드가 1개이므로 이 노드에서 0~1 사이의 값을 가져야 마지막에 cast를 통해 1 혹은 0 값으로 output을 받을 수 있다.
이 때 sigmoid를 사용한다.
Thah (Hyperbolic Tangent)
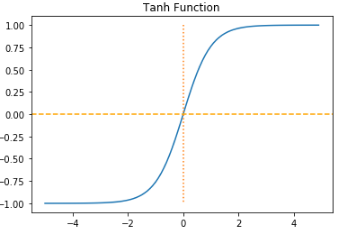
시그모이드 함수와 거의 유사한데, 차이는 -1~1의 값을 가지고 데이터 평균이 0이라는 점.
대부분의 경우 시그모이드보다 Tanh가 성능이 더 좋다.
시그모이드와 마찬가지로 vanishing gradient 현상이 일어난다.
ReLU
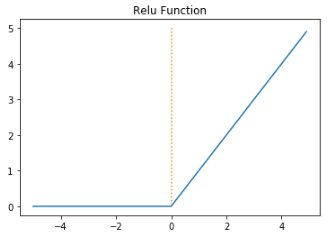
일반적으로 ReLU의 성능이 가장 좋아서 ReLU를 사용한다.
"Hidden Layer에서 어떤 활성화 함수를 사용할 지 모르겠으면 ReLU를 사용하면 된다" 앤드류 응
출력단에서 사용하는 것이 아니다.
학습을 느리게하는 원인이 gradient가 0이 되는 것인데 이를 막아주기 때문에 학습이 빠르다.
(sigmoid, Tanh에 비해)
Leaky ReLU
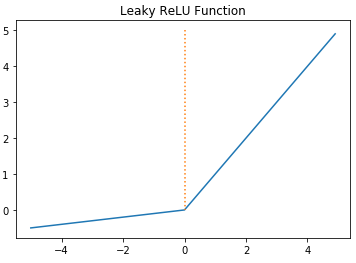
ReLU와 유일한 차이점으로는 max(0, z)가 아니라 max(0.01z, z)라는 점이다.
relu는 z가 음수일 경우 0으로 갔는데, leaky relu는 기울기가 0이 아닌 0.01 값을 가진다.
leaky relu를 일반적으로 많이 쓰는데 relu보다 학습이 더 잘 되긴 한다.
논문에서 leaky relu를 쓴 케이스도 많다.
relu와 별 차이가 없으면 relu를 쓰기도 하는데, 모델에 따라 값이 leaky relu가 잘 나온 것을 볼 수도 있다.
2. 중요내용
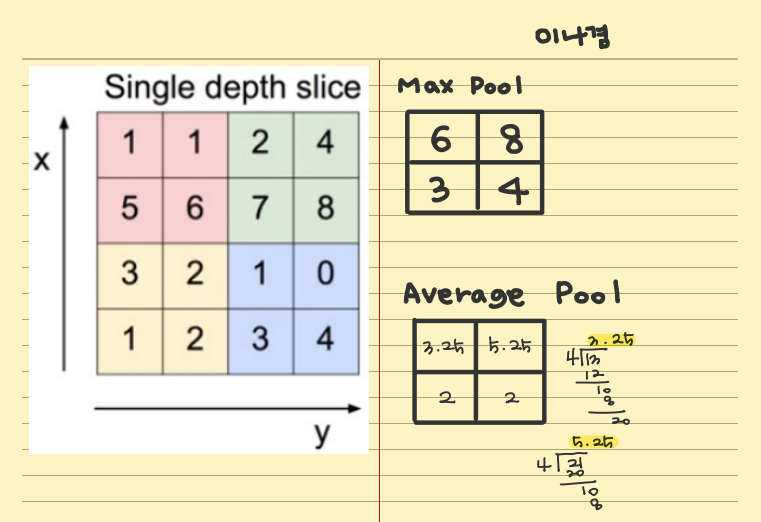
3. 학습소감
optimizer에 대해서는 좀 더 공부를 해서 이해가 필요하다는 생각이 들었다.
