Abstract
본 논문에서는 최첨단 문장 임베딩을 크게 향상시키는 간단한 contrastive learning framework를 제안한다. 우리는 먼저 input sentence를 취하고, dropout을 noise로 사용해 constrastive objective에서 스스로를 예측하는 비지도 방식을 설명한다. 이 방식은 간단하면서도 이전 지도 학습을 사용하는 다른 방식과 동등한 성능을 보이며 잘 작동한다. 우리는 dropout이 최소한의 data augmentation으로 하고, 이를 제거하는 것은 representation collapse로 이어진다는 것을 발견했다. 그리고, 우리는 NLI 데이터셋에서 annotated된 pair(entailment를 positive, contradiction을 negative로)를 우리의 constrative learning framework로 통합하는 방식을 제안한다. 우리는 standard semantic textual similarity(STS) task에 대해 SimCSE를 평가했고, BERT-base를 사용한 우리의 비지도와 지도 모델이 76.3%, 81.6%를 달성하였고, 이는 이전 SOTA에 비해 각각 4.2%, 2.2% 증가한 수치이다. 우린 또한 이론적, 실험적 모두에서 contrastive learning objective가 사전 학습된 임베딩의 이방성 공간(anisotropic space)를 보다 균일하게 정규화하고 지도 신호(supervised signal)을 사용할 수 있을 때 postivie pair를 더 잘 align한다는 것을 보여준다.
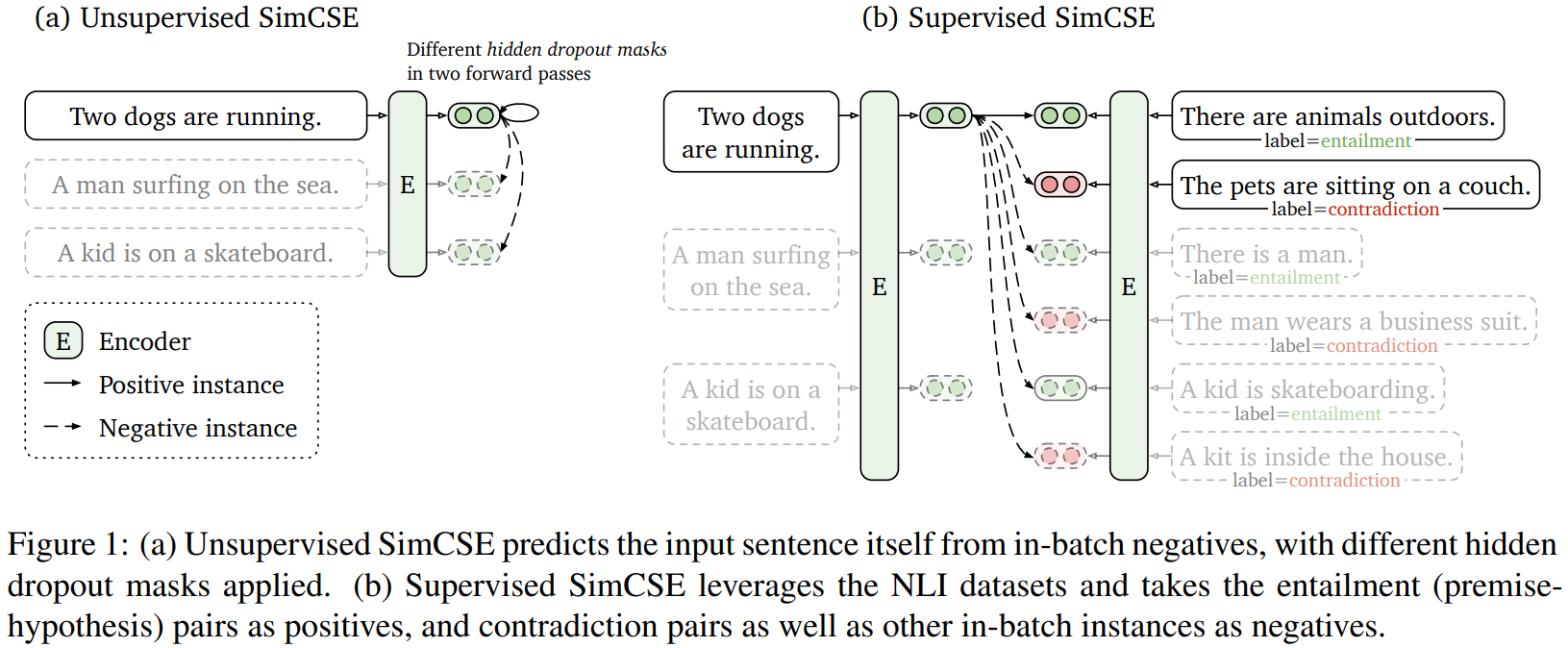
1 Introduction
범용적인 sentence embedding을 학습하는 것은 NLP에서 중요한 문제이고, 광범위하게 연구되어 왔다. 본 논문에서, 우리는 SOTA embedding에서 한 발짝 더 나아갔고, constrative objective가 BERT 또는 RoBERTa와 같은 사전학습 언어 모델과 함께 사용될 때 매우 효과적임을 증명한다. 우리는 SimSCE, a simple contrastive sentence embedding framework, 라벨이 있든 없든 상위의 sentence embeddig을 만들어낼 수 있는 방법을 제안한다.
우리의 비지도 SimCSE는 dropout만을 노이즈로 서용해 스스로 input sentence를 예측하는 방식이다. 다시 말하면, 우리는 pre-trained encode에 같은 문장을 2번 통과시킨다 : standard dropout을 2번 적용해, 우리는 2개의 다른 문장을 positive pair로 본다. 그리고 우리는 같은 mini-batch에서 다른 문장을 가져와서 "negative"로 취하고 모델은 여러 negatives사이에서 positive하나를 예측한다. 매우 간단해 보일 수 있지만, 이 접근 방식은 다음 문장을 예측하는 것 혹은 이산적 data augmentation(단어 삭제 및 대체)와 같은 학습 목표를 큰 차이로 능가하며 심지어 이전 지도 방식과 일치한다. 우리는 dropout이 hidden representation의 최소한의 "data augmentation"역할을 하는 반면, dropout을 제거하며 표현이 무너진다는 것을 알 수 있었다.
본 논문의 지도 SimCSE는 sentence embedding을 위해 NLI dataset을 사용하고, contrastive learning에서 annotated sentence pair를 통합한다. 3가지 방법의 분류 태스크(entailment, neutral, contradiction)로 본 지난 논문들과 달리, 우리는 entailment pair를 positive instance로 사용될 수 있다는 사실을 최대한 활용했다. 또한, 상응하는 contradiction pair을 추가하는 것이 성능 향상에 도움이 된다는 것을 알았다. NLI datset의 간단한 활용은 같은 데이터셋을 사용한 이전 방법들과 비교해 지속적인 성능을 성취했다. 우리는 또한 다른 labeled sentence-pair dataset과 비교하고, NLI이 데이터셋이 sentence embedding학습에 특히 더 효과적이라는 것을 알 수 있었다.
SimCSE의 강력한 성능을 더 잘 이해하기 위ㅣ해, 우리는 Wang and Isola[2020]으로부터 분석 툴을 가져왔고, 이는 학습된 임베딩의 질을 측정하기 위해 전체 표현 공간의 uniformity와 semantically-related positive pair를 alignment한다. 경험적인 분석을 통해, 우리는 우리의 비지도 SimCSE가 기본적으로 균일성을 향상시키는 동시에, dropout noise를 통한 degenerated alignment을 방시하여, representation의 expressivness를 향상시킨다는 것을 알았다. 같은 분석은 NLI 학습 신호가 positive pairs사이의 alignment를 향상싴닐 수 있고, 더 나은 sentence embedding을 만들 수 있다는 것을 보여준다. 우리는 또한 사전 학습된 word embedding이 anisotropy에 고통 받는다는 발견에서 연결점을 끌어내 (spectrum관점에서) contrasticve leanring objective가 sentence embedding space의 sigular value distribution을 flattents해 uniformity를 향상시킨다는 것을 증명했다.
우리는 SimCSE를 7가지 semantic textaul similarity tasks(STS), 7가지 transfer tasks에 대해 포괄적으로 평가를 진행했다. STS task에서, 우리의 비지도와 지도 모델은 BERT-base를 사용해 평균적으로 76.3%와 81.6% Spearman's correlation을 달성했다(이전에 비해 4.2%, 2,2% 증가됨). 우리는 또한 transfor task에 대해 경쟁적인 성능을 성취했다. 마지마긍로, 우리는 일관되지 않은 평가 문제를 식별했고, sentence embedding 평가에서 향후 작업을 위해 다양한 설정의 결과를 통합했다.
2 Background: Contrastive Learning
Contrastive learning은 이웃은 가깝게, 이웃이 아닌 애들은 멀게 밀어내 효과적으로 representation을 학습하는 것을 목표로 한다. 이란 pair examples를 가정하고, 이는 와 이 의미적으로 관련이 있음을 나타낸다. 우리는 Chen at al.[2020]에서의 contrastive framework를 따르고, in-batch negatives를 가지고 cross-entropy objecticve를 취한다 : 와 는 와 의 representation을 나타낸다. 그리고 mini-batch N에서 에 대한 학습 목적 함수느 다음과 같다.
여기서 는 temperature hyperparameter이고, 는 코사인 유사도 이다. 이번 논문에서, 우리는 BERT 또는 RoBERTa와 같은 사전 학습 모델을 사용해 input sentence를 encode한다. 그리고 contrastive learning objective를 사용해 모든 파라미터를 파인튜닝한다.
Positive instances
contrastive learning에서 중요한 질문은 어떻게 pair를 구축할지이다. 비전 표현에서, 효과적인 해결책은 같은 이미지에 과 으로 2개의 무작위 변형(cropping, flipping, distortion and rotation)을 가하는 것이다. 단어를 삭제하거나, 재정렬하거나, 대체하는 방식을 사용해서 유사한 방법이 언어 표현에서도 응용되어 왔다. 그러나, NLP에서 data augmentation은 내재적으로 이산적인 특성때문에 어렵다. 3에서처럼, 중간 단계의 representation에 단순히 dropout을 사용하는 것은 이러한 discrete operator보다 훨씬 뛰어나다.
NLP에서, 유사한 constrative learning objective는 다양한 맥락(contexts)에서 연구되었다. 이러한 경우, 은 question-passage pair와 같은 지도 데이터셋으로부터 수집된다. 과 의 구별되는 특성때문에, 이러한 방식은 항상 각각 x에 대한 dual-encoder framework를 사용한다. sentence embedding에서, Logeswaran and Lee(2018)은 또한 dual-encoder를 가지고 현재 문장과 다음 문장을 으로 형성해 contrastive learning을 사용한다.
Alignment and uniformity
최근에, Wang and Isola(2020)는 contrastive learning과 관련한 2가지 핵심 특성을 구별한다. - alignment and uniformity - 그리고, 표현의 질을 측정하기 위해 그들을 사용하는 것을 제안한다. positive pairs 의 분포가 주어질 때, alignment는 두 paired instances의 embedding사이의 기대거리를 계산한다(assuming represenations are already normalized). Uniformity는 임베딩 자체가 얼마나 균등하게 분포되어 있나를 의미한다.
** : "equal to by definition".
여기서 는 데이터 분포를 나타낸다. 이러한 2개의 지표는 contrastive learning의 목적함수와 함께 잘 aligned 된다 : postivie instance는 가까이 있어야 하고, random instance에 대한 embedding은 hypersphere에 대해 흩어져 있어야 한다. 다음 세션에서, 우리는 또한 우리의 방법의 inner working을 정당화하기 위해 두 개의 지표를 사용할 것이다.
*DBSA SimCSE 발표자료에서 발췌
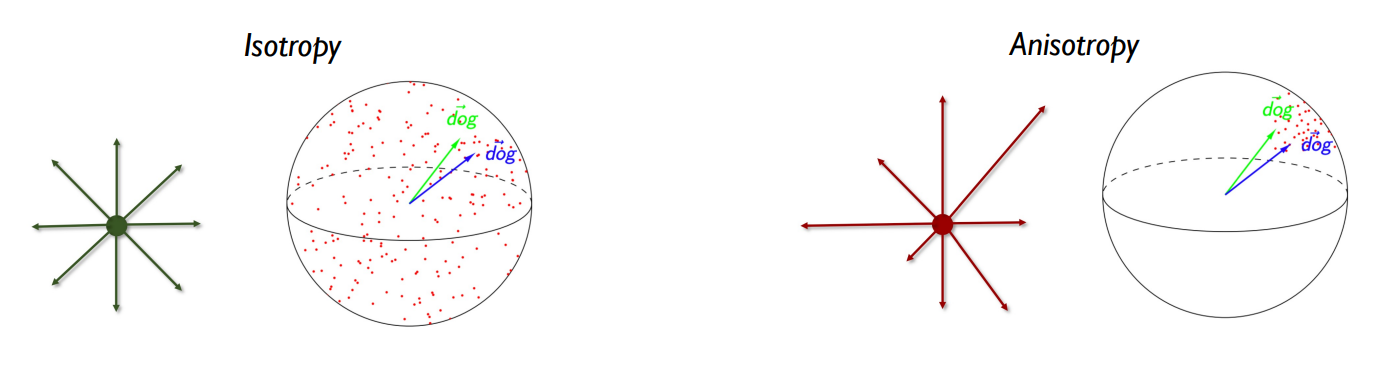
왜 uniformity가 representation에서 중요한가?
- PLM은 학습할수록 상위 레이어에서 Anisotropic하다(contextaulized될 수록 anisotropic함. input 자체가 anisotropic하다는 것이 아니라.)
- 하지만 Isotropy, Anisotrpy한 것을 그림으로 보면,
동일한 단어가 다른 문맥에 등장한 경우, Context에 따라 거리가 가깝지만 다른 의미를 좋음.
하지만, random word를 넣어도 contextuality를 고려하느라 의미가 비슷해져버리는 것은 문제가 된다.
=> Embedding space가 hypersphere에서 넓고, 고르게 분포하여 각 단어가 고유한 의미를 보존하는 것도 중요 ==> Uniformity의 중요성
따라서, contrastive learning을 통해 학습을 진행하다보면, Negative pair를 positive pair와 멀게하는 과정에서 embedding space를 균일하게 분포하도록 만들 수 있다!
**근데 어차피 중간단계에서 dropout을 하는데, 상위레이어로 가면 다시 anisotropy하게 변하지 않을까? 덜해지는 것인가??
uniformity에 대한 loss로 저 식을 사용하는 이유
The average pairwise Gaussian potential is nicely tied with the uniform distribution on the unit hypersphere.
(논문 Understanding Contrastive Representation Learning through Alignment and Uniformity on the Hypersphere에서 발췌)
3 Unsupervised SimCSE
비지도 SimCSE의 아디이어는 매우 간단하다 : 우리는 sentence의 집합인 를 가져오고, 를 사용한다. identical positive pairs으로 작동하도록 하는 핵심 요소는 독립적으로 샘플링된 dropout mask를 사용하는 것이다. Transformers의 학습에서, attention probabilities(default p = 0.1)뿐만 아니라 fully-connected layers에도 dropout mask가 있다. 우리는 라고 표기한다. 여기서 는 dropout을 위한 랜덤 마스크를 의미한다. 우리는 간단하게, 같은 input을 encoder에 2번 넣고 다른 dropout mask를 가진 2개의 임베딩 을 얻는다. 그러면, mini-batch N개의 문장에 대한 SimCSE의 training objective는 다음과 같이 된다. z는 transformets에서의 standard dropout mask이고, 다른 dropout은 추가하지 않았다.
** DBSA 이유경 석사과정님의 SimCSE발표자료에서 발췌
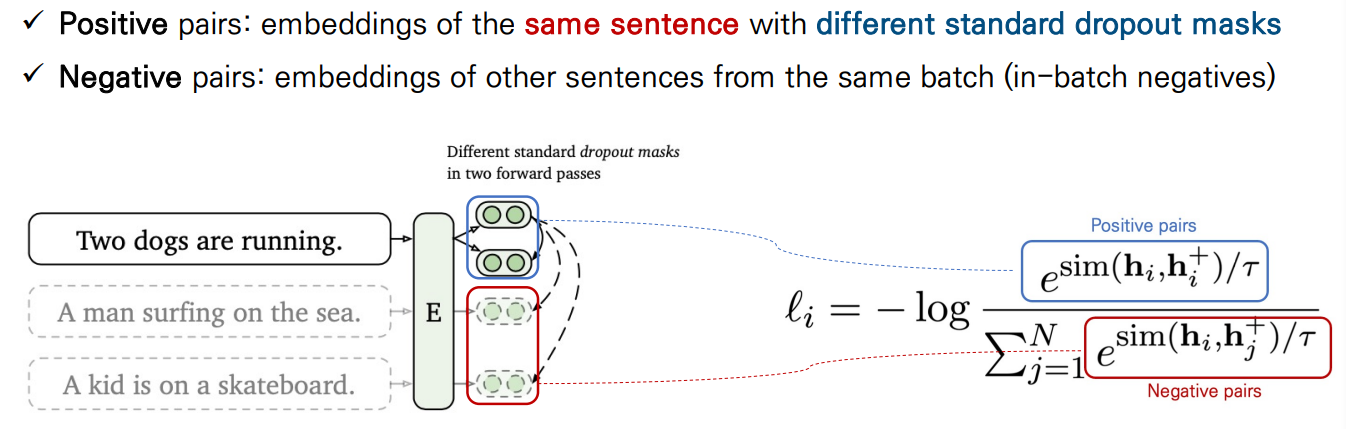
(분자는 같은 문장을 다르게 표현한 것들의 유사도, 분모는 다른 문장을 다르게 표현한 것들의 유사도의 합. 즉, 분자는 커지고, 분모는 작아질수록, 같은 것들의 유사도는 높아지고, 다른 애들 사이의 유사도는 낮아질수록 loss가 작아짐)
Dropout noise as augmentation
우리는 droputout을 data augmentation의 최소한의 방식으로 본다. : positive pair는 정확히 같은 문장을 가지고, 그들의 임베딩은 오직 droput out에서 다르게 된다. 우리는 STS-B에 development set에 대해 다른 학습 목적 함수와 이 방식을 비교했다. Table 1은 우리의 접근과 흔한 crop, word deletion, replacement와 같은 data augmentation기법을 비교한다. 그리고 각각은 그리고 는 x에 대한 (random) discrete operator이다. 우리는 1단어를 삭제하는 것도 성능에 큰 악영향을 미칠 수 있고, discrete augmentation의 어떤 방법도 dropout noise보다 뛰어나지 않다는 것을 알 수 있었다.
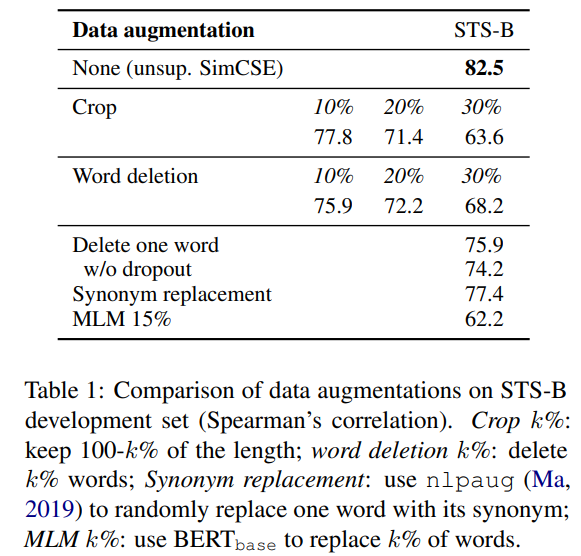
우리는 또한 Logeswaran and Lee(2018)에서 사용된 next-sentence objective에 대한 training objective(1개의 encoder또는 2개의 독립적인 encoder사용)과도 비교해보았다. Table 2에서 볼 수 있듯이, 우리는 SimCSE가 next-sentence objectives보다 훨씬 좋은 성과를 낸다는 것, 2개보다 1개의 encoder를 사용하는 것이 우리의 방법에서 상당한 차이를 낸다는 것을 알 수 있었다.
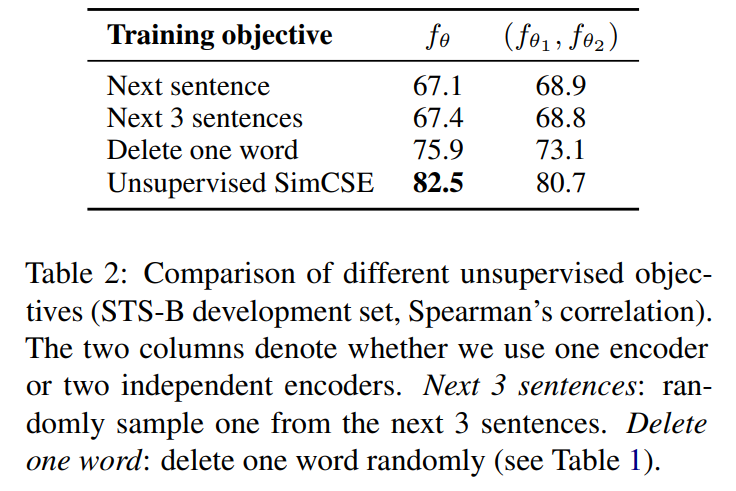
** DBSA 이유경 석사과정님의 SimCSE발표자료에서 발췌
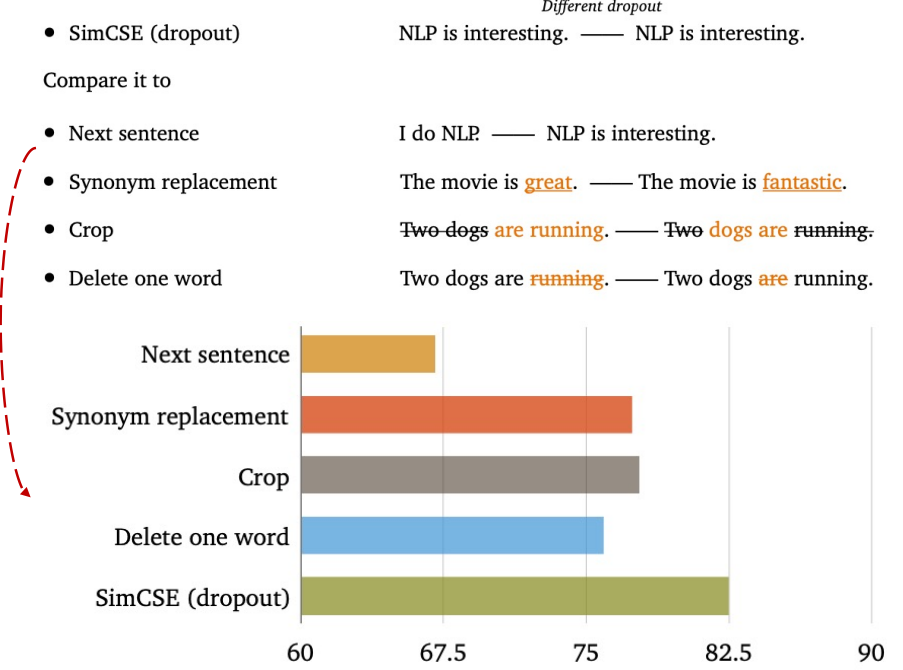
Why does it work?
비지도 SimCSE에서 dropout noise의 역할을 더 잘 이해하기 위해, 우리는 Table 3에서 다양한 dropout rates를 시도해봤고, Transformers의 기본 dropout 확률인 p = 0.1이 오는 다양한 모든 시도가 default에 비해 underperform하다는 것을 관찰했다.
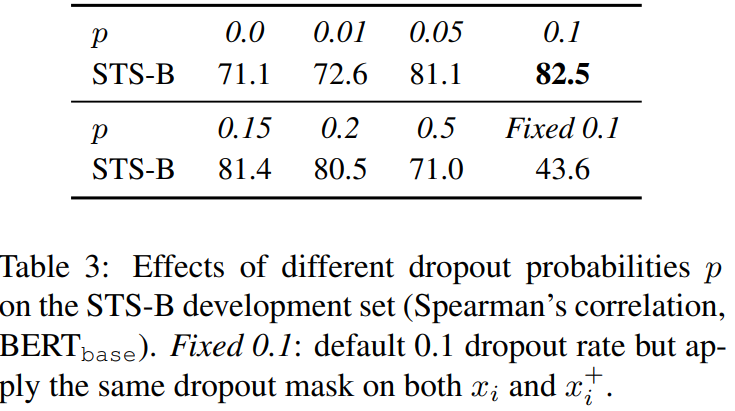
우리는 특히 2개의 흥미로운 극단적인 경우 찾았다 : no dropout(p=0)과 fixed 0.1(using default dropout p=0.1 but the same dropout masks for the pair / 두 문장이 representation까지 동일한 경우). 두 경우에서, pair에 대한 임베딩의 결과는 정확히 같았고, 이는 극적인 성능 저하로 이끌었다. 우리는 학습 동안 매 10 step마다 모델의 checkpoint를 찍었고, Figure 2처럼 alignment와 uniformity를 시각화 한다. 사전학습 체크포인트에서 시작해서, 모든 모델이 uniformity가 크게 향상되었다. 하지만, 2가지 특별한 변형의 alignment는 또한 크게 드라마틱하게 떨어졌지만, 우리의 비지도 SimCSE모델은 dropout noise를 사용해 안정적인 alignment를 유지했다. 또한 초기에 좋은 alignment를 제공하기 때문에, 사전 학습된 체크포인트에서 시작하는 것이 중요하다는 것을 증명했다. 마지막으로 "1단어 삭제"는 alignment를 향상시키지만, uniformity지표에 대해선 적은 향상을 달성했고, 결국 비지도 SimCSE보다 낮은 성과를 기록했다.
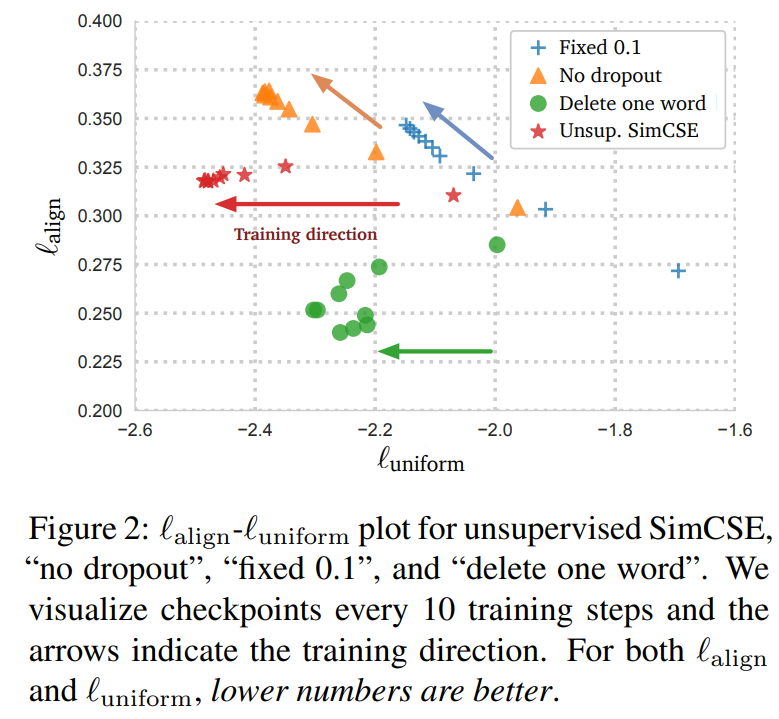
4 Supervised SimCSE
우리는 dropout noise를 추가하는 것이 positive pair 에 대한 좋은 alignment를 유지하게 한다는 것을 증명했다. 이번 세션에서는, 우리는 우리의 방법으로 alignment를 개선해 training signal을 더 좋게 만들어 지도 데이터셋을 더 효율적(?) 좋게 사용할 수 있을지를 연구한다. 이전 논문은 지도 NLI 데이터셋이 두 문장 사이의 관계가 entailment, neutral 또는 contradiction인지 예측함으로써 sentence embedding을 학습하는 것에 효과적임을 보였다. 우리의 contrastive learning framework에서, 우리는 지도 데이터셋에서 바로 를 선택하는거 대신에 Eq.1.를 최적화해 사용한다.
Choices of labeled data
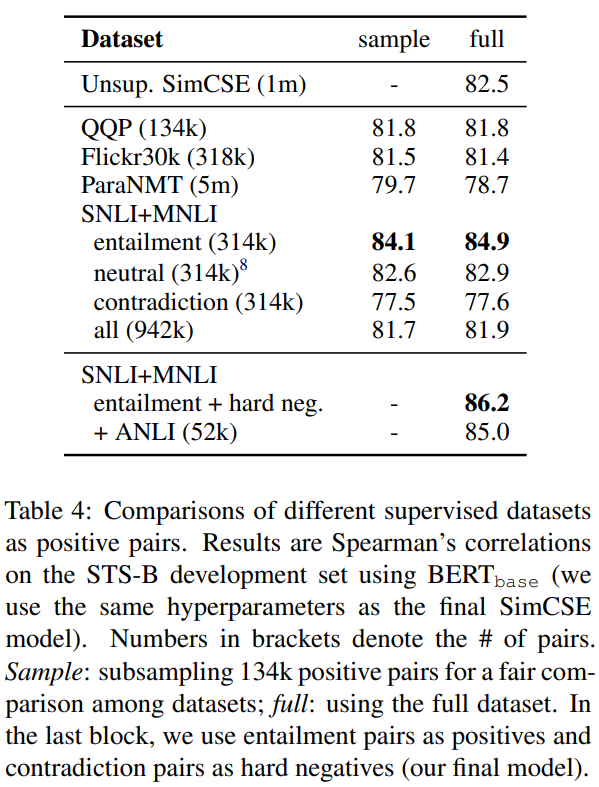
우리는 먼저 지도 데이터셋이 positive pairs 을 구축하는 것에 적합하다는 것을 연구했다. 우리는 4개의 데이터셋을 가지고 실험을 진행했다.
1) QQP : Quora question pairs
2) Flickr30k : each image is annotated with 5 human-written captions. 같은 이미지의 2개의 캡션을 positive pair로 사용
3) paraNMT : 큰 규모의 book-translation paraphrase dataset
4) NLI datasets : SNLI와 MNLI
우리는 다양한 데이터셋을 가지고 contrastive learning model를 학습하고, 결과를 비교한다. Table 4를 보면, 우리는 또한 같은 수의 training pair를 가지고 실험을 진행했다. 모든 옵션 중에서, NLI로부터 entailment pair를 사용하는 것이 가장 베스트였다. 우리는 NLI dataset는 높은 퀄리티, 그리고 crowd-sourced된 데이터로 구성되어 있기 때문에 이것이 합리적이라고 생각한다. 또한, human annotators는 premise에 기반해 hypotheses를 작성할 것이고, 두 문장은 적은 lexical overlap을 가지는 경향이 있다. 예를 들어, NLI의 entailment pair에 대한 lexical overlap(두 개의 BOW 사이의 F1)은 39%였지만, QQP, ParaNMT에 대한 F1은 60%, 55%였다.
Contradiction as hard negatives
자미작으로, 우리는 contradiction pair를 hard negatives로 사용함으로써 NLI datset의 이점을 취했다. NLI 데이터셋에서, 하나의 premise가 주어질 때, annotator는 하나는 절대적으로 true(entailment), 다른 하나는 아마도 true(neutral), 마지막 하나는 절대적으로 false(contradiction)인 한 문장을 직접 작성하는 것이 요구된다. 그러므로, 각 premise와 entailment hypothesis에 대해, 동반하는 contradictino hypothesis가 있다.
형식적으로, 우리는 을 로 확장하고, 이때 는 premise, 와 는 entailment와 contradiction hypothesis를 나타낸다. 학습 목적함수 는 다음과 같이 정의된다(N는 mini-batch size):
Table 4를 보면, hard negative를 더하는 것은 성능을 향상시키고(84.0 86.2), 이것이 우리의 최종 지도 SimCSE이다. 우리는 또한 ANLI dataset에 비지도 SimCSE를 추가하거나 결합하려고 노력했다. 또한, 지도 SimCSE에서 dual encoder framwork를 사용하는 것은 성능을 악화시켰다(86.2 84.2).
5 Connection to Anisotrpy
최근 논문들은 language representations에서 anisotropy 문제를 식별한다.
(학습된 임베딩이 벡터 공간에서 좁은 꼬깔을 차지하고, 이는 표현을 심각하게 제한한다)
- Gao et al.[2019]는 input/output embeddings으로 묶여서 학습된 언어 모델이 anisotropic word embedding으로 이끌고, 이는 pre-trained contextual representaion에서도 관찰되었다.
- Wang et al.[2020]은 언어 모델에서 워드 임베딩 행렬의 특이값이 급격하게 감소한다는 것을 발견했다. : 몇 개의 지배적인 특이값을 제외하면 나머지는 거의 다 0.
이러한 문제를 완화하는 간단한 방법은
- post-processing
- dominant principal components를 제거하는 것
- isotropic 분포로 임베딩을 맵핑시키는 것
- 학습 동안에 regularization을 추가하는 것
본 논문에서, 이론적으로 경험적으로 모두, contrastive objective가 이런 anisotropy 문제를 경감시킬 수 있음을 보였다.
anisotropy문제는 uniformity와 연결되어 있고, 동시에 embedding이 결국 공간에 분포되어야 한다는 것을 강조한다. 직관적으로, contrastive learning objective를 최적화하는 것은 negative instance를 멀리 밀어내기 때문에 uniformity를 향상시킬 수 있다. 우리는 singular spectrum perspective을 취한다. - 이는 워드 임베딩을 분석할 때, 흔히 사용하는 방법이다. 그리고, contrastive objective는 문장 임베딩의 특이값 분포를 펼칠 수 있고, 표현을 더 isotropic하게 만든다는 것을 볼 수 있었다.
Wang and Isola[2020]에 따르면, contrastive learning objective의 asymptotics는 negative instances의 수가 무한에 다가감에 따라, 다음과 같은 식으로 표현될 수 있다(는 normalized라고 가정).
첫번째 항은 positive instances들이 유사하게 유지되도록 하고, 두번째 항은 negative pairs가 떨어지게 밀어낸다. 가 유한한 샘플 , 에 대해 uniform하다면, 우리는 다음과 같은 식을 Jensen's inequality를 통해 이끌어낼 수 있다.
jensen's inequality
if 가 에 대해 convex function이고, 와 이 유한하다면,
를 에 대응되는 문장 임베딩 행렬이라고 하자. 즉, 의 i번째 행은 이다. 두번째 항을 최적화하는 것은 의 모든 요소들의 합의 upper bound를 최소화 하는 것이다. ()
를 normalize하기 때문에, 에 있는 모든 주대각원소가 1이고, (eigenvalues의 합)이 상수이다. 의 모든 원소가 양수이면, 은 의 가장 큰 eigenvalue에 대한 upper bound이다. 두번째 항을 최소화할 때, 의 top eigenvalue를 줄이고, 내재적으로 임베딩 공간의 singular spectrum을 flatten한다. 그러므로, contrastive learning은 representation degeneration problem을 경감시키고 문장 임베딩의 uniformity를 향상시킬거라고 에상된다
isotropic representation만을 목표로 하는 post-processing 방법과 비교하면, contrastive learning은 첫번째 항에 의해 positive paris를 align역시 최적화 한다.
6 Experiment
6.1 Evaluation Setup
7가지 semantic textaul similarity(STS) task에 대해 실험을 수행한다. 본 논문에서의 STS 실험은 완전히 비지도이고, STS 학습 데이터셋은 사용되지 않았다. 지도 SimCSE에 대해서도, 우리는 단순히 이전 논문에 따라 학습을 위해 라벨링된 큰 데이터셋을 가져오는 것을 의미한다. 또한 7개의 transfer learning task에 대해 평가하고, 자세한 결과는 Appendix E에 기술해 놓았다. 문장 임베딩의 주된 목표는 의미적으로 유사한 문장들을 클러스터링하는 것이므로 STS를 메인 결과로 가져갔다.
Semantic textual similarity tasks
- 우리는 7개의 STS task에 대해 평가했다 : STS 2012-2016과 STS Benchmark, SICK Relatednedss
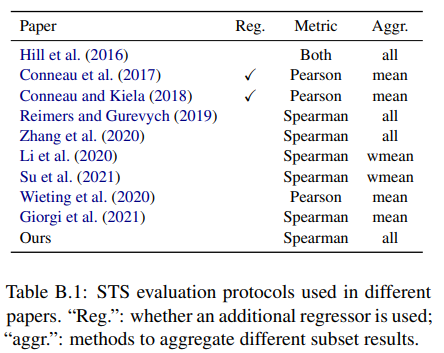
- 이전 논문들과 비교하면서, 우리는 invalid comparison pattern을 평가 상황에서 식별했다.
- 추가적인 regressor를 사용하는지
- Spearman's vs Pearson's corrleation
- 어떻게 결과가 합쳐지는지(Table B.1)
- 또한 이전 논문의 중복된 연구를 보고할 뿐만 아니라 우리의 결과를 다양한 환경에서 평가했다.
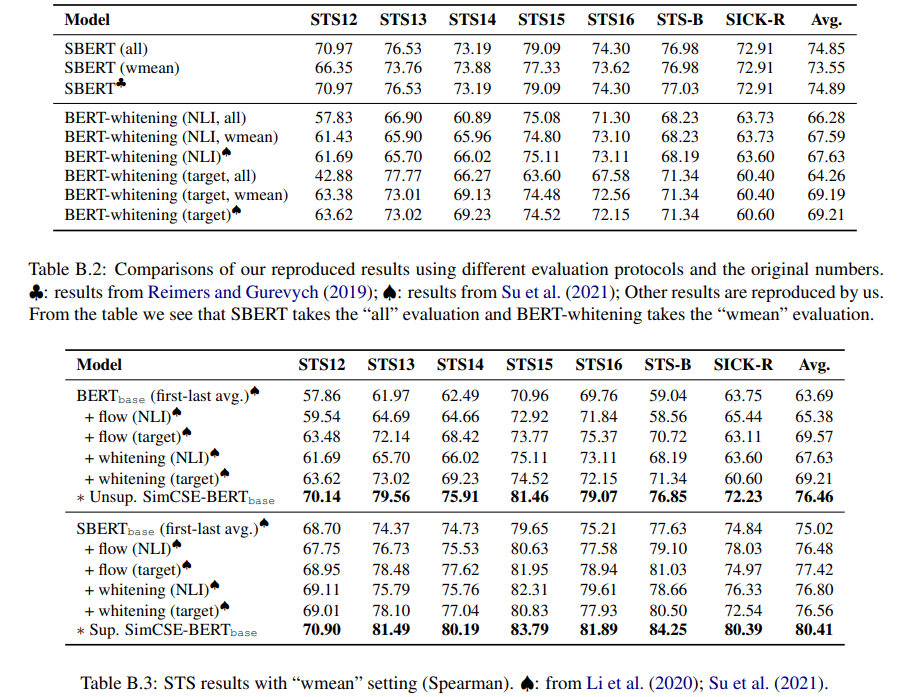
Training details
- BERT 또는 RoBERTa의 사전학습된 체크포인스에서 시작(6.3에 풀링 방법이랑 비교)
- [CLS] 표현을 문장 임베딩으로 사용
- 영어 위키피디아에서 무작위로 선택된 문장에 대해 비지도 SimCSE 학습, MNLI와 SNLI 데이터셋의 조합에 대해 지도 SimCSE 학습
- 더 detail한건 Appendix A에!
6.2 Main Results
-
STS tasks에 대해 이전 SOTA 문장 임베딩과 본 논문의 비지도, 지도 SimCSE와 비교
-
비지도 baseline은 GloVe embedding 평균, BERT or RoBERTa embedding 평균, post-processing method로는 BERT-flos, BERT-whitening포함
-
contrastive objective를 사용한 다른 최근 연구와도 비교
- IS-BERT : global과 local 특징 사이의 agreement를 최대화
- DeCLUTR : positive pair로 같은 문서에서의 다른 spans 선택
- CT : 두 개의 encoder로부터 같은 문장의 임베딩을 aligns
-
다른 지도 방법은 InferSent, Universal Sentence Encoder, SBERT/SRoBERTa, 그리고 post-processing 방법과 비교
-
Table 5엔 7가지 STS task에 대한 평가 결과가 나와있다.
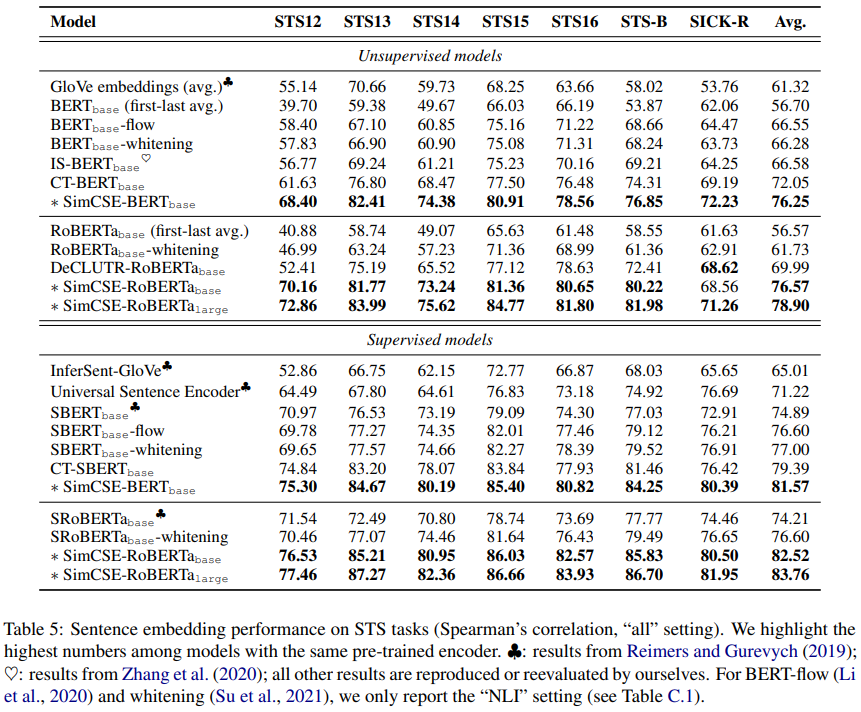
- SimCSE는 모든 dataset에 대해 결과를 크게 향상시킴.
- 특히, 비지도 SimCSE-BERT-base는 72.05%dptj 76.25%까지 성능을 향상시켰다.
- 아무튼 최고!
-
Appendix E에서, SimCSE는 또한 그동안 성취한 transfer task percormance와 동일하거나 더 나은 결과를 보여줬고, auxiliary MLM objective는 성능을 더 끌어올릴 수 있게 해줬다.
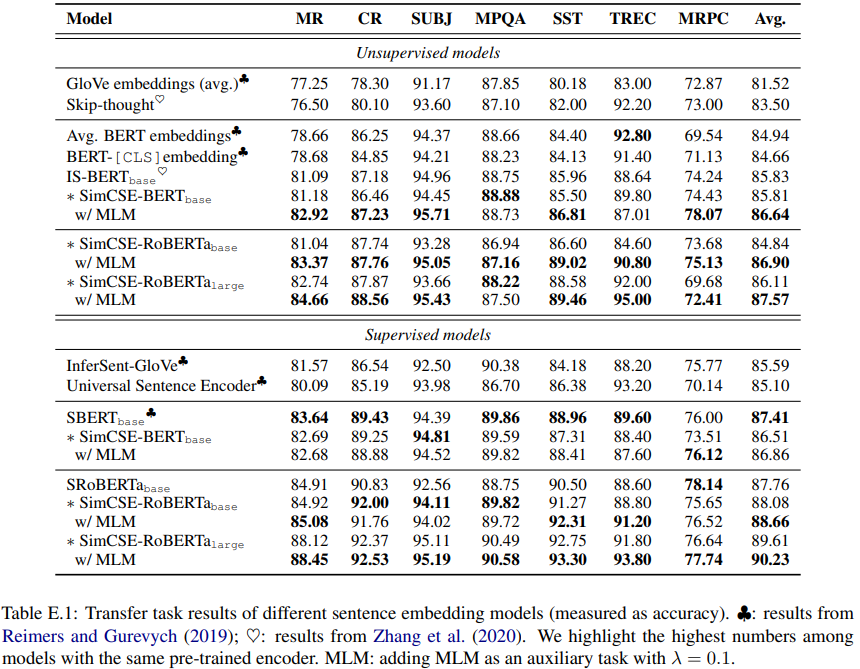
6.3 Ablation Studies
- 다양한 pooling 방법과 hard negative의 영향을 조사함
- 여기 나온 모든 보고된 결과는 STS-B development set를 기반
- 더 자세한 ablation study는 Appendix D참고
Pooling methods
- 사전 학습 모델의 평균 임베딩(첫번째 레이버랑 마지막 레이어 둘다) 사용하는 것이 [CLS]토큰 보다 더 나은 성능을 이끔
- Table 6에서 보면 지도 SimCSE와 비지도 SimCSE에 대해 다양한 pooling method를 비교
- [CLS]에 대해 원래 BERT 구현은 위에 추가적으로 MLP layer를 사용한다. 그래서 다양한 환경을 고려해 다음과 같이 설정
- MLP layer유지
- no MLP layer
- keeping MLP during training but removing it at testing time
==> 실험 결과, 비지도는 3이 베스트, 지도는 다양한 방법이 맞지 않았음
- 결론적으로, default로 [CLS] with MLP(train) for unsupervised SimCSE와 [CLS] with MLP for supervised SimCSE 사용
Hard negatives
- 직관적으로, 배치의 다른 negatives로부터 hard negatives를 미분하는 것은 유용!
==> training objective를 hard negative까지로 확장은 i=j일때만 1과 동일하다. - SimCSE를 다양한 값을 가지고 학습, 평가
- 일때 가장 성능이 좋았음
Analysis
Uniformity and alignment
-Figure 3에 다양한 문장 임베딩 모델의 uniformity와 alignment가 나타나 있음
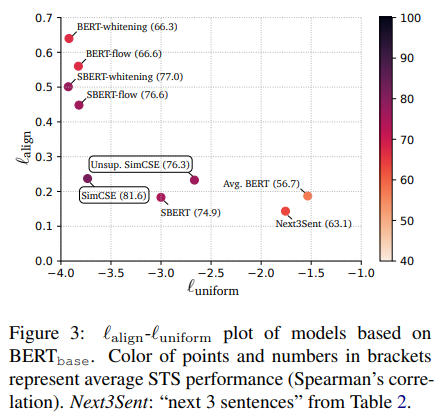
- 일반적으로 좋은 alignment와 uniformity를 가진 모델들은 좋은 성과를 냄
- 사전 학습 임베딩은 좋은 alignment를 갖지만, uniformity는 나쁨(즉, embeddings이 highly anisotorpic함)
- post-processing방법(BERT-floaw, BERT-whitening)은 uniformity를 크게 향상시키지만 alignment에서 degeration으로 고통받음.
- 비지도 SimCSE는 사전 학습 임베딩의 uniformity를 효과적으로 향상시키면서 좋은 alignment를 유지
- 지도 데이터를 SimCSE를 통합하는 것은 alignment를 더욱 수정시킴.
Appendix F에서 SimCSE가 사전 학습 임베딩의 특이값 분포를 효과적으로 펼칠 수 있다는 것을 보임
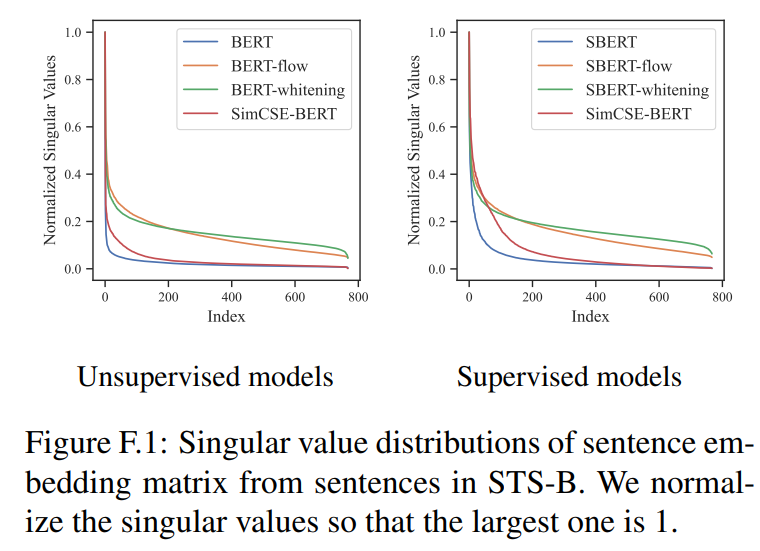
(BERT-flow 또는 BERT-whitening과 같은 post-processing 방법은 isotropic distribution에 임베딩을 매핑하는 것을 직접 목표로 하기 때문에 곡선을 더욱 flatten)
Appendix G에서 SimCSE가 다른 문장 pairs사이에 더 특징적인, 구별되는 코사인 유사도를 제공한다는 것을 증명함.
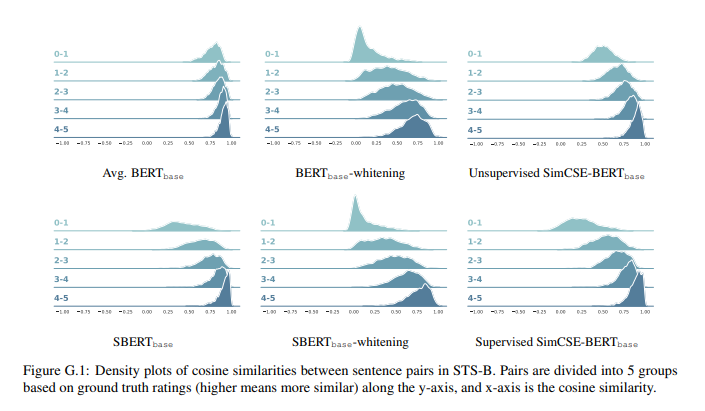
Qualitative comparison
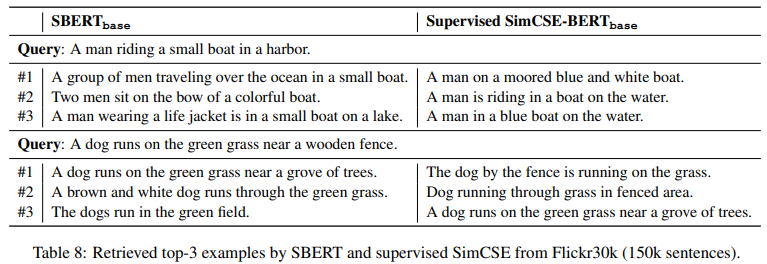
SBERT-base와 SimCSE-BERT-base를 가지고 실험을 진행. Flickr30k dataset에서 150k의 캡션을 사용했고, 유사한 문장을 검색하기 위해 쿼리로써 무작위로 문장을 선택. Table 8에서의 데이터처럼, SimCSE에 의해 검색된 문장들이 SBERT와 비교해 더 높은 퀄리티를 가짐
9 Conclusion
SimCSE는 semantic textual similarity task에서 SOTA sentence embeddings를 크게 개선시킴. input sentnece에 droput onise를 얹어 스스로 예측하게 하는 비지도 방식과, NLI dataset를 활용하는 지도 방식 모두를 제안. 다른 base-line model들과 SimCSE의 alignment와 uniformity를 분석함으로써 내부적으로도 증명. 특히 비지도방식은 NLP의 다양한 응용에 활용될 수 있을거라 생각. text input인 data augmentation에 새로운 관점을 제안했고, 이는 다른 conitunous representation으로 확장되고 언어모델로 통합될 수 있을 것.
