[논문 리뷰] Faithful or Extractive? On mitigating the Faithfulness-Abstractiveness Trade-off in Abstractive Summarization
Paper review
본 논문은 2021년 ACL에서 발표된 논문입니다.
생성 요약에서 발생하는 incosistency를 줄이기 위해 많은 연구자들이 다양한 모델을 내놓고 있는데, 이러한 모델들의 성과가 faithfulness와 abstractiveness사이에 trade-off관계를 이용한 faithfulness 성능 향상은 아니었을까?에 대한 의문을 조금이나마 해소해주는 논문입니다.
consistency == faithfulness == factuality
inconsistency == nonfaculity == hallucination
이러한 표현들은 생성요약에서 섞여서 사용되니 알아두시면 논문을 읽기 편합니다!
Abstract
현재 생성요약에서의 고질적인 문제인 faithfulness error를 개선하기 위해 다양한 연구들이 진행되고 있습니다. 이전에faithfulness를 향상하기 위해 제안된 모델들이 정말 faithfulness를 높였는지는 명확하지 않습니다. 즉, 이들의 향상된 faithfulness가 요약 모델을 더 extractive하게 만들어서 달성한 결과인지 아닌지에 대한 지표 혹은 연구가 부족합니다.
따라서 본 논문에서는 faithfulness-abstractiveness trade-off curve를 만들며 요약 시스템에서 "effective faithfulness"를 평가하는 프레임워크를 제안합니다.
- 이를 통해, baseline뿐만 아니라 faithfulness를 위해 최근에 제안된 방법론들이 같은 수준의 abstractiveness에서 control에 대해 지속적인 향상에 실패했다는 것을 보입니다.
- 마지막으로, 주어진 문서에 대해 가장 faithful하고 abstractive한 summary를 식별하는 selector를 학습시켜, 이러한 시스템이 abstractive도 baseline보다 높으면서 human evaluation에서도 높은 faithfulness score를 얻을 수 있다는 것을 보입니다.
Introduction
직관적으로, 생성된 요약의 faithfulness를 향상시키는 방법은 원문에서 content를 그대로 갖고 오는 것입니다(i.e. more extraction). 이와 같이, 어떠한 방법론으로 인해 extractiveness 수준이 높아진다면 faithfulness 역시 높아지게 됩니다. 그래서 extractiveness으로 인한 faithfulness향상과 향상된 abstraction으로 인핸 faithfulnes향상을 분리해서 볼 필요가 있습니다.
이러한 필요성에서 시작해서, 본 논문에서는 effective faithfulness, 즉 같은 수준의 extractiveness에서 작동하는 baseline모델(control)에 대한 faithfulness의 향상을 고려하여, faithfulness를 평가하는 프레임워크를 제안합니다. 특히, 학습 데이터를 summary의 extractivness에 따라 다른 그룹으로 분리하여 각 그룹의 control models를 학습합니다. 이러한 각 모델의 결과를 바탕으로 trade-off curve를 형성하고, 이는 오로지 extractiveness에 의존해 얼마나 많은 faithfulness를 높일수 있는지를 알려줍니다. 만약 모델이 effective faithfulness를 향상시켰다면 이 curve의 위쪽에 위치가헤 됩니다.
이 프레임워크를 사용하여, 최근에 제안된 방법론의 향상된 faithfulness가 주로 증가된 extractiveness에서 기인한 것임을 보였습니다. 그리고 추가적인 연구를 통해 system이 baseline system보다 더 abstractive하면서 faithful할 수 있는지 확인했습니다. 다양한 extractiveness 정도에 따라 output summaries가 있는 human annotated data의 하위 집합에 대해selector를 학습시키고, 원문에 대해 faithful하면서 가장 abstractive한 output을 선택하였습니다. 그 결과, baseline모델에 비해 더 faithful하고 abstractive할 수 있었습니다.
그래서 요약하자면,
-
같은 모델을 가지고 데이터를 extractiveness에 따라 나눠 각각의 데이터에 대해 학습시켜 faithfulness-abstractiveness trade-off curve를 만듦. 이를 바탕으로 모델이 effective faithfylness를 향상시킨 것인지 평가 가능.
-
1번을 사용해 최근 모델이 향상한 faithfulness는 extractiveness에서 주로 기인한 것이라는 걸 보임.
-
selector를 제안하며, 이 방법이 현재 존재하는 방법론에 비해 더 높은 efective faithfulness를 달성했다는 것을 보임.
Dataset
최대한 덜 extractiveness하고 hallucination이 없는 데이터셋으로 선정
- Gigaword : headline generation dataset that contains around 4M examples. source document is first sentence of article, summary is headline of article.
- Wikihow : dataset of how-to articles covering a diverse set of topics, collected from the wikihow.com website. There are about 12M such paragraphs in the dataset, paired with a one setence summary.
Dataset Extractiveness
data의 extractiveness를 측정하기 위해, extractive fragment coverage와 extractive fragment density를 사용하였습니다. 이 둘은 각각 coverage와 density를 나타냅니다
- Coverage : the percentage of words in summary that are from the source article
- Density : the average length of the text spans copied from the document that are contained in the summary.
Analysis on Metrics of Faithfulness
최근의 faithfulness evaluation은 모델을 기반으로 원문에 대해 요약문이 faithful한지를 판별하는 방식의 atomated metrics를 제안합니다.
예를 들어,
- Entailment : pretrained entailment based method를 사용해 생성된 결과가 원문에 entailed되는지를 평가
- FactCC : rule-based transformation을 적용해 hallucinated summaries를 생성하고, 이를 사용해 버트 기반 모델이 generated output이 faithful한지 아닌지를 분류하도록 학습시킴
- DAE : word-, dependendy- and sentence-level faithfulness에 대한 fin-grained annotation을 수집해서 factuality detection model을 학습하는데 사용
아래의 그림을 살펴보면, 다양한 생성 요약 모델로 생성된 결과의 평균 coverage와 평균 metric 점수사이의 관계를 알 수 있습니다.
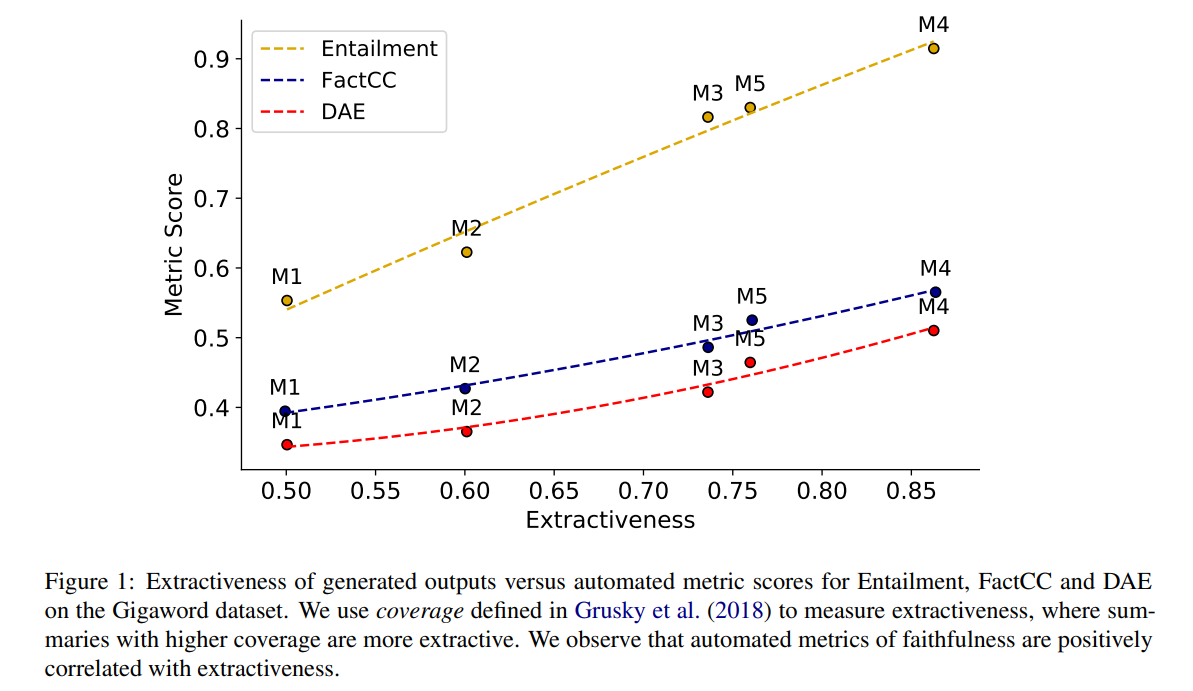
이 장표를 보면 extractiveness와 faithfulness scores사이에 양의 상관관계가 존재함을 알 수 있습니다. 즉, 모델이 더 extractive한 summary를 생성할수록, 더 높은 faithfulness점수를 받을 것입니다. 이러한 관계로 인해 모델이 높은 factuality score를 달성해도 이것이 extractive에서 기인한 것인지 혹은 전과 같은 extractiveness수준에서 faithful summary를 만들어 점수가 높아진 것인지 알 수 없습니다. 이를 통해 faithfulness를 비교할 땐, extrativeness정도도 함께 고려해야함을 알 수 있습니다.
Evaluating Effective Faithfulness
본 논문에서는 모델의 extractiveness도 고려하는 effective faithfulness를 평가하는 프레임워크를 제안합니다. 이를 위해서, 우리는 우선 다양한 수준에서의 extractiveness에서 작동하는 모델의 faithfulness를 결정할 필요가 있습니다. 이를 Faithfulness-Abstractiveness Tradeoff라 부릅니다. 모델의 effective faithfulness은 간단하게 모델의 faithfulness score와 trade-off curve에 따라 같은 평균적인 extractiveness에서 작동하는 모델의 점수를 상대적 비교하는 것입니다.
Faithfulness-Abstractiveness Tradeoff
제안된 모델의 향상된 faithfulness를 효과적으로 분석하기 위해, 그 모델의 extractiveness를 고려하는 것이 필요합니다. 본 논문에서는 faithfulness를 향상시키는 다른 외부 요인 없이 다양한 수준의 extractivenss에 대해 pre-trained BART모델을 파인튜닝했습니다. 그리고 이 모델을 이용해 요약 모델의 effective faithfylness를 측정하기 위한 control로써 faithfulness-abstractiveness trade-off curve를 만들었습니다. effective faithfulness를 향상시킨 모델은 반드시 faithfulness-abstractiveness trade-off curve위에 놓여 있어야 합니다.
특히, 원문에 대해 reference summary의 coverage를 계산해 extrativeness quartiles에 따라 학습 데이터를 sub-sample했습니다. 이 후 각각의 quartiles에 대해 BART를 파인튜닝시켜 다양한 수준의 extractiveness를 가진 quartile model를 만들었습니다. 거기에 더해, 모든 데이터에 대해 BART를 파인 튜닝해 baseline를 만들었습니다.
랜덤하게 선택한 200개 데이터에 대해 각 모델이 생성한 요약문에 faithfulness annotation을 수집했다. 우리는 AMT를 이용해 데이터별로 3개의 annotations을 받았고, 각 데이터에 대해 "faithful"이라고 선택한 annotators의 percentage를 계산해 이를 faithfulness score로 사용했습니다. 아래의 표를 보면 baseline과 quartile model에 대한 coverage와 faithfulness점수를 볼 수 있고, Q1는 가장 abstractive한 qurtile을, Q4는 가장 extractive quartile를 나타냅니다.
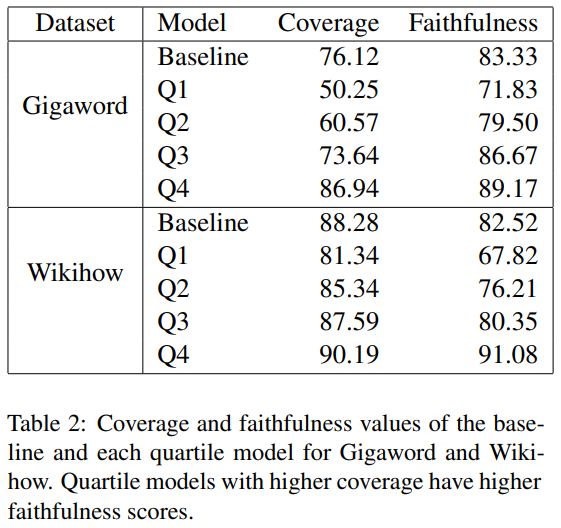
우리는 더 extractive한 quartiles에 파인튜닝한 모델이 더 훨씬 더 높은 coverage와 faithfulness score를 가진 요약문을 생성한다는 것을 알 수 있었습니다. baseline모델은 Gigaword와 Wikihow 모두에 대해 Q3에 가까운 coverage를 가진 비교적 extractive한 결과물을 생성했습니다. 게다가, baseline모델의 경우 Gigaword에 대해 Q3에 대해 파인튜닝된 모델보다 더 높은 coverage를 가졌지만, faithfulness 점수는 낮았습니다.

표1을 보면, Wikihow 데이터의 원문과 각 baseline, quartile 모델이 생성한 요약문이 나타나있습니다. 생성된 요약문들이 의미적으로 매우 유사하다는걸 알 수 있지만 Q1 모델이 생성한 요약문의 경우 타 모델이 생성한 요약문에 비해 novel word가 많이 등장하는 것을 볼 수 있습니다. 반대로 Q4모델의 경우 coverage가 1, 즉, 생성한 요약문의 모든 단어가 원문에 등장하는 단어라는 것을 알 수 있습니다. 평균적으로 Q1 모델이 Q4모델에 비해 더 abstractive하고 덜 faithfulness한 요약문을 생성합니다.
Mitigating the Trade-off
Oracle Experiments
몇가지 human judgements이 가능한 oracle experiments를 설계해 faithfulness-abstractiveness tradeoff를 완화할 수 있는지에 대해 알아봅시다.
baseline + faithfulness(bf)
3명 중 2명 이상의 annotator가 faithful하다고 판단한 baseline output을 사용했습니다. 만약 baseline output이 faithful하지 않다면, baseline과 유사한 coverage를 ㅏ지지만 faithfylness를 보존하는지를 보기 위해, 우리는 baseline보다 더 extractive한 quartile model에서 output을 선택했습니다.
==> faithful하면 baseline output, baseline output이 faithful하지 않으면 유사하거나 더 높은 extractiveness를 가진 quartile model의 output사용
baseline + faithfulness-extractiveness(bfe)
이 oracle system은 baseline output이 unfaithfyl할 때 위에 서술한 것과 유사하게 작동합니다. 하지만, 결과값이 faithful할 때 항상 baseline 결과를 선택하는 것이 아니라 quartile모델의 결과같 중에 baseline보다 더 abstractive한게 있다는 그 결과값을 택합니다.
==> baseline, quartile모델들 중에서 가장 abstractive하면서 faithful한 모델의 결과값을 사용
quartile + faithfulness-extractiveness(qfe)
faithful를 유지하면서 abstractive한 결과값을 생성할 수 있는지 알아보기 위해 4개의 quartile model중에서 가장 abstractiveness가 높은, 가장 faithful한 결과값을 선택합니다.
Analysis
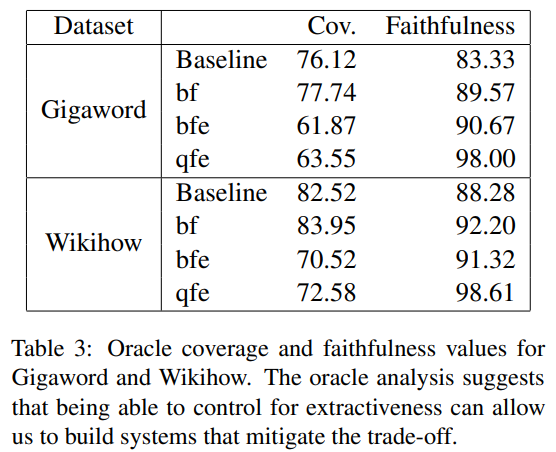
표3을 보면, Gigaword와 Wikihow에 대해 baseline과 이러한 oracles에 대한 coverage와 faithfylness를 볼 수 있습니다. bf를 보면 baseline과 유사한 수준의 abstractivenss에서 더 faithful할 수 있다는 것을 알수 있습니다. 게다가, bfe를 통해 더 faithful하면서 baseline보다 더 abstractive할 수 있다는 것도 알 수 있습니다. quartile model들에서 가장 faithful하고 abstractive output을 선택하는 것은 baseline에 비해 낮은 coverage를 유지하면서도 매우 높은 faithfulness score에 도달할 수 있다는 것을 보여줍니다. 이러한 oracle analysis를 통해 우리는 extractivenss수준을 조절함으로써 faithfulness-abstractiveness trade-off를 완화시킬 수 있는 모델을 만드는 것이 가능하다는 것을 알 수 있었습니다. 이러한 분석 결과에 따라, 본 논문에서는 자동적으로 faithfulness-abstractiveness trade-off관계를 완화하는 selection을 할 수 있는 selector를 학습시킬 수 있는지에 대해 추가적인 연구를 진행하였습니다.
Loss Trucation
Kang과 Hashimoto는 모델에서의 결과값과 reference와의 차별성을 최대화하기 위해, 큰 loss의 데이터를 적절하게 제거하는 방법을 제안했습니다. 그들은 이러한 Loss Truncation 모델에 의해 생성된 데이터가 다른 baseline 방법에 비해 더 높은 factuailty rating을 달성했다는 것을 보였습니다. 우리는 이 방법이 faithfylness-abstractiveness trade-off의 관점에서 어디에 놓여있는지, 이들이 정말로 control에 비해 더 effective faithfulnfess를 달성했는지를 관찰합니다.
Dependency Arc Entailmend(DAE)
Goyal과 Durrett가 제안한 factuality evaluation metric(DAE)는 생성된 결과에서 각각의 dependency arc가 input과 consistent한지를 평가합니다. 그들은 그들의 제안된 metric이 기존의 factuality metrics에 비해 더 좋다는 것을 입증했고, generated output이 non-factual한 부분을 localize할 수 있습니다. Goyal과 Durrett는 factuality error를 localize하는 DAE의 장점을 이용해 오직 DAE metric에 따라 factual하다고 여겨지는 token의 subset에 대해서만 요약 모델을 학습했습니다. 우리는 이러한 방법론을 따라 요약 모델을 학습시키고, 우리의 평가 프레임워크를 사용해 모델을 평가합니다.
Selector Model
우리는 trade-off를 향상시키기 위해 가장 abstractive하지만 faithfyl한 결과값을 식별할 수 있는 selector를 제안합니다. 우리는 우선 quartile 모델을 사용해 4개의 후보 요약문을 생성합니다. 이 겨과는 다양한 수준의 extractiveness를 가지게 됩니다. 우리의 selector를 위해, 우리는 trade-off curve를 생성하기 위해 수집한 데이터에 대해 FactCC모델을 학습시키고(10-fold cross validation), 생성한 요약문에 대해 faithfulness 점수를 매기도록 합니다. 게다가, ROC curve아래의 지역을 최대화하는 faithfulness score에 대한 threshold를 학습합니다. text fold에서 각 데이터에 대해, 우리는 FactCC기준 faithful하면서 가장 abstractive한 후보를 선택합니다.
ROC curve아래의 지역을 최대화하는 것 대신, 우리는 점수를 최대화하기 위한 faithfylness threshold를 조정할 수 있습니다(Selector-). 를 사용해서, 가 1보다 작으면 우리의 selector의 precision에 더 높은 가중치를 준 것이고, 즉 coverage가 높으면서 faithfulness한 결과가 나오게 됩니다.
우리는 FactCC가 다양한 데이터셋에 대해 학습되어 있기 때문에 원하는 데이터에 대해 파인튜닝하는 것이 중요하다는 것을 알았고, 이는 그 전의 연구 결과와 일관됩니다.
Results
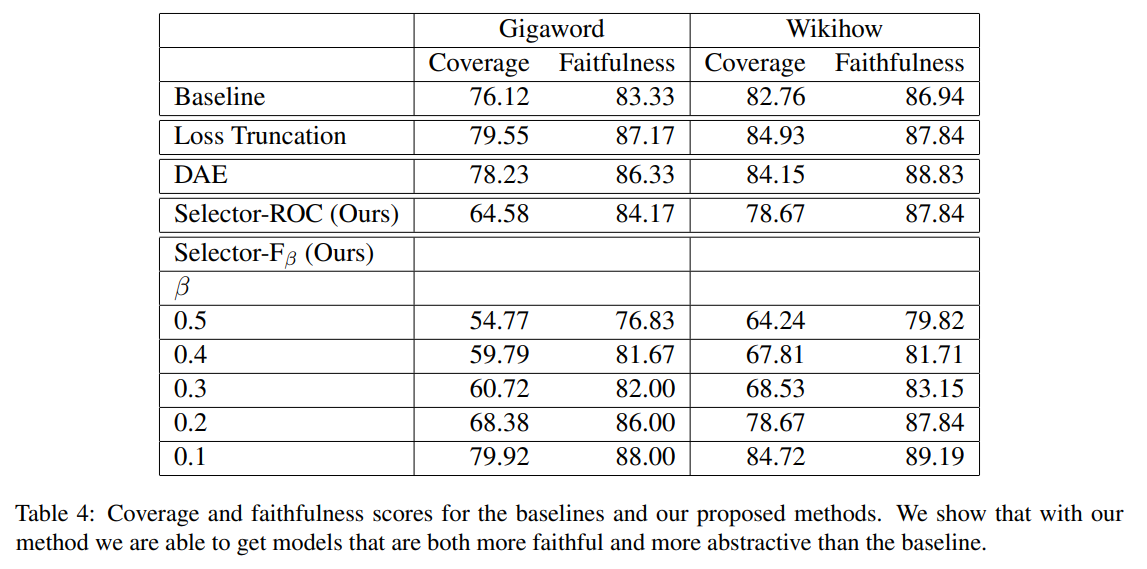
표 4를 보면, baseline, Loss Truncation, DAE 그리고 selector에 대한 coverage와 faithfulness를 알 수 있습니다.
-
더 작은 을 가지는 Selector가 더 extractive하고 faithful한 결과를 얻음
==> faithfulness와 abstraciveness사이에 trade-off관계가 있다! -
Selector-ROC와 Selector- 모두에 대해, baseline보다 coverage는 낮으면서 faithfulness점수는 높은 결과를 만듦
-
Wikihow에 대해선, Selector-ROC가 Loss Truncation에 비해 낮은 coverage + 유사한 faithfylness를 가진 요약문을 생성
-
를 0.1로 할 때 DAE와 Loss trucation과 유사한 coverage level에서 더 높은 faithfulness를 달성
-
Gigaword에 대해, Select-ROC는 DAE와 Loss Truncation에 비해 훨씬 낮은 coverage를 가진 겨과를 생성
-
Selector-는 더 높은 faithfulness score를 가지면서도 Loss Turncation에 비해 유사한 ouverage를 갖는 결과값을 생성
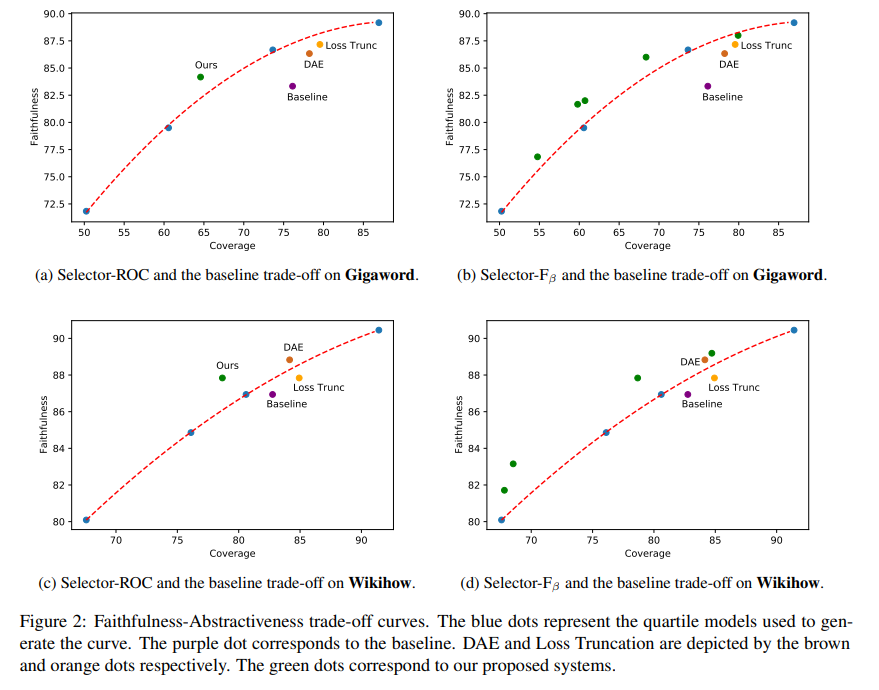
위의 그래프에서 점선 위쪽에 있어야 effective faithfulness를 향상시켰다고 볼 수 있습니다. -
Gigaword와 Wikihow 모두에 대해, Selector-ROC는 위쪽에 위치. trade-off 향상시킴.
-
baseline과 Loss Trucnation모델은 아래에 위치, 더 나쁜 trade-off 얻음
-
Selector-를 사용해 서너개의 모델이 Gigaword와 Wikihow 모두에 대해 curve 위쪽에 놓여있는 것을 알 수 있음
==> selector 방법은 abstractiveness-extractiveness spectrum에서 다양한 점들이 효과적인 effective faithfulness를 얻을 수 있다는 것을 보여줌 -
DAE기반 모델의 경우 Wikihow에서는 curve 위쪽에 존재하지만, Gigaword에 대해선 아래쪽에 위치하며 모델의 성취가 데이터셋에 일관되지 못하다는 것을 보임
