[논문 리뷰] The Factual Inconsistency Problem in Abstractive Text Summarization: A Survey
Paper review
Abstract
현재 다양한 신경망 인코더 디코더 모델이 생성 요약 분야에서 좋은 모습을 보이고 있다. 하지만 신경망 모델의 생성 요약 능력은 양날의 검과 같다. 생성 요약의 흔한 문제 중 하나는 원문의 factual information을 왜곡하거나 생성하는 것이다. 이러한 원문과 요약문 사이의 inconsistency문제는 여러 응용 분야에서 우려하고 있고, 이전의 생성 요약 평가 지표들은 이러한 문제에 적합하지 않다. 위의 문제를 해결하기위해 현재 연구 방향은 크게 2가지 방향으로 나뉘어 있다. 하나는 factual inconsistency error없이 output을 선택하도록 fact-aware evalutation metrics를 설계하는 것이고, 다른 하나는 factual consistency를 유지하는 새로운 요약 시스템을 개발하는 것이다. 이번 서베이에서, 우리는 fact에 특화된 평과 방법과 요약 모델을 포괄적으로 리뷰하는데 집중하고 있다.
Introduction
문서 요약은 NLP에서 가장 중요하면서 어려운 태스크 중 하나다. 문서 요약은 원문에서 중요한 정보를 포함한 짧을 버전으로 텍스트를 농축시키는 것이다. 문서 요약은 크게 2가지 방법으로 나뉜다 : extraticve(추출), abstractive(생성)
extractive summarization은 퉁계적 특성을 고려하고 요약을 만드는 추출된 문장을 정렬해 텍스트에서 중요한 문장을 찾는 것이다. abstractive summarization은 새로운 단어를 사용하거나 rephrasing해 새로운 문정을 생성하면서 요약을 만드는 방법이다.
현재의 생성 요약 모델은 유창하고 사람이 읽을 수 있는 요약을 만들 수 있지만, factual inconsistency error를 생성하는 경향이 높다. 즉, 생성이 종종 원문의 사실을 왜곡하거나 조작하는 현상을 의미한다. 최근 연구에 따르면, 생성 요약의 30% 정도까지는 이러한 factual inconcsistencies를 포함한다고 밝혔다. 이는 생성 요약 시스템의 신뢰와 사용 가능성에 심각한 문제를 가져온다.

위의 그림을 살펴보면, "magnitude-4.8 earthquake"는 "powerful quake"로 강조되었고, 사회적으로 역효과를 낼 수 있다.
다른 한 편, 현존하는 대부분의 요약 평과 방법은 생성 요약과 사람이 쓴 reference 요약 사이에 N-gram overlap를 계산한다(fact-level consistency는 무시한 채). 예를 들어, "I am having vacation in Hawaii"와 "I am not having vacation in Hawaii"는 거의 모든 unigram과 bigram을 공유하지만, 반대의 의미를 지니고 있다.
이런 factual inconsistency issue를 다루기 위해, 많은 automatic factual consistency evaluation metrics과 meta-evaluation for these metrics이 제안되었다. 게다가, 요약 시스템에 factual consistency를 최적화 하기 위해 많은 노력이 들어갔다. 우리는 factual consistency evalutaion과 factual consistency optimazation method의 개론을 제공함으로써 factual inconsistency문제에 초점을 맞춰보고자 한다.
Background
2.1 Abtractive Summarizatoin methods
진부한 생성 요약 방법은 보통 원문에서 몇몇 키워드를 뽑아내고, 키워드에 대해 정렬 및 언어적 변형을 수행한다. 그러나 이전 paraphrase기반 생성 방법은 유창한 문장을 쉽게 생성한다.
Nallapati 외[2016]은 처음으로 RNN을 사용해 원문을 단어 벡터의 시퀀스로 인코드, 다른 RNN을 사용해 단어 시퀀스를 생성해내는 방법을 제안했다. encoder와 decoder는 CNN과 Transformer으로도 만들어질 수 있다. 신경망 문서 생성을 기반으로 하는 시퀀스 투 시퀀스의 디코더는 conditional language model이고, 이는 읽을 수 있고 유창한 텍스트를 생성해낸다. 하지만 대부분의 요약 시스템은 단어 수준에서 reference summary의 log-likelihood를 최대화하는 방식으로 학습된다. 이는 모델이 충실성에 대해선 보상을 주지 않는다.
2.2 Factual Inconsistency Error
Factual inconsistency error는 크게 2가지로 나뉠 수 있다.
- Intrinsic Error : 원문에 반대되는 사실. 예를 들어서, "central"인데 "north"라고 하는 경우
- Extrinsic Error : 원문에 중립적인(neutral) 사실. 예를 들어서 "적어도 7명의 사람들이 죽고 100명 이상이 부상을 당했다"와 같은 말은 원문에는 없었던 문장이다.
현존하는 fatual consistency optimization 방법은 주로 intrinsic error에 초점을 두고 있다. 그리고 이 2가지 분류는 factual consistency evaluation metrics에선 구별되지 않는다.
3 Factual Consistency Metrics
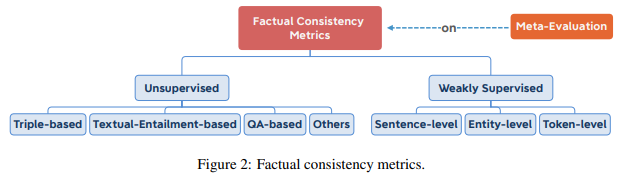
우리는 factual consistency metrics를 2가지로 나눈다. 하나는 Unsupervised metrics(Treple-based, Textual entailment-based, QA-based ..), 다른 하나는 Weakly supervised metrics이다. 또한 이러한 factual consistency metrics를 서로 비교하기 위해 Meta-evaluations이 부상하였다. 여기선 2가지의 meta-evaluation을 소개한다.
3.1 Unsupervised Metrics
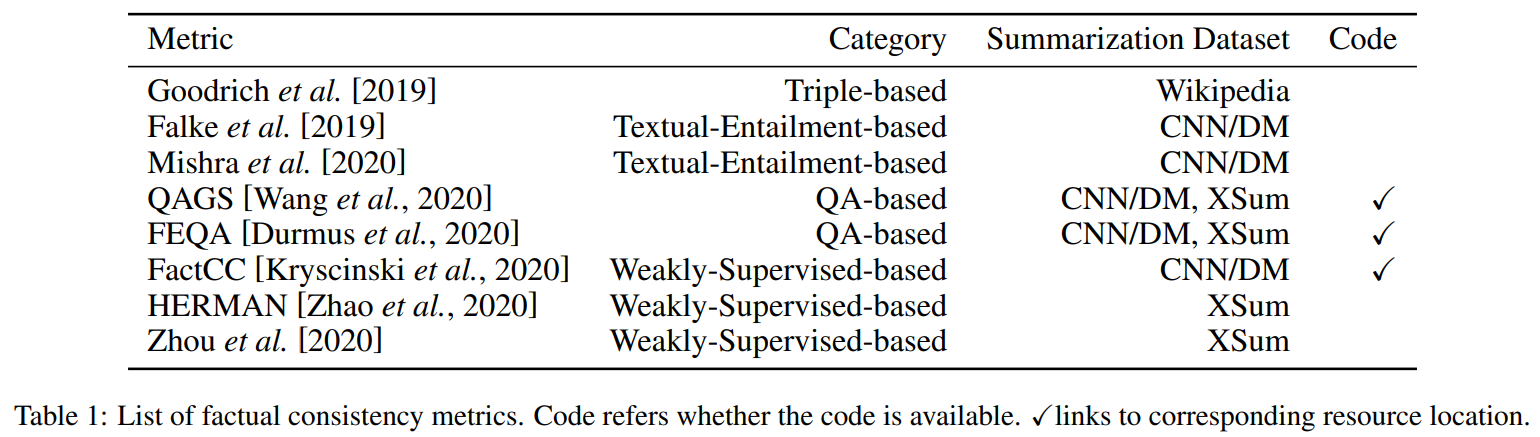
Triple-based
factual consistency를 평가하는 가장 직관적인 방법은 생성된 요약과 원문 사이의 overlap되는 fact를 세는 것이다. 아래 그림과 같이 fact는 보통 relation triples(subject, relation, object)로 나타난다(여기서 subject는 object에 대한 관계를 나타낸다).

triples를 추출하기 위해, Goodrich 외[2019]는 처음으로 OpenIE tool을 사용하기 시작했다. 하지만, OpenIE는 고정된 스케마 대신 명시되지 않은 스케마(unspecified schema)를 가진 triples를 추출한다. unspecific schema extraction에서, relation은 subject와 object사이의 관계가 텍스트에서 추출된다. fixed schema extraction에서, 관계는 미리 정의된 relation set에서 예측된다(일종의 분류 문제 느낌쓰). Unspecific schema추출은 추출된 triples끼리 비교하기 어렵다. Example 1을 보면 같은 사실을 표현한 2개의 문장에서 서로 다른 triples를 얻어낸다는걸 알 수 있다.

이런 문제를 해결하기 위해, Goodrich 등[2019]는 fixed schema를 가진 relation extraction tools을 사용하는 것으로 바꿨다. Example 1,에서 2개의 문장을 고려했을 때, 원문에서 추출하든 요약에서 추출하든, 추출된 triples은 fiexed schema extraction에서 (Hawaii, is the birthplace of, Obama)이다. 이는 triples끼리 비교하기 용이하게 한다.
Text-Entailment-based
factually consistent summary는 원문에 의미적으로 entailed여야 한다는 아이디어에 따라, Falke 외[2019]는 요약에서 factual consistency를 위해 textual entailment prediction tool을 사용하는 것을 제안했다. Textual entailment prediction, NLI는 text P(premise)가 다른 text H(hypothesis)를 entail할 수 있는지를 감지하는 걸 목표로 한다. 그러나, out-of-the-box entailment models는 문서 요약에서 factual consistency evaluation을 대해 바라는 성과를 내지 못했다. 그 이유 중 하나는 NLI dataset에서 summarization dataset으로 도메인이 바뀌었기 떄문이고, 또 다른 이유는 NLI 모델이 높은 entailment확률을 설명하기 위해 lexical overlap과 같은 휴리스틱한 방식에 의존하기 때문이다. 결과적으로 현존하는 NLI모델은 downstream task에서 낮은 일반화를 보인다.
NLI모델을 좀 더 일반화하게 만들기 위해, Mishra 외[2020]dms NLI datasets과 downstream task사이에 주요한 차이를 premise의 길이로 봤다. 자세히 말하자먼, 대부분의 NLI dataset은 하나 또는 소수의 문장을 premise로 고려한다. 그러나 요약과 같은 대부분의 downstream NLP task은 더 긴 문장을 premise로 여기고, 이는 긴 텍스트에 대한 추론을 요한다. 더 긴 텍스트에 대한 추론은 무수한 추가적인 능력(ex. coreference resolution, abductive reasoning)을 요한다. 이 사이의 갭을 메꾸기 위해서, 연구자들은 일반화할 수 있는 NLI model을 학습하기 위핸 긴 premise를 가진 NLI dataset를 만들었다. 이 새로운 NLI dataset으로 학습한 후에, 그 모델은 factual consistency evaluation task에서 상당한 성과를 이룩했다.
QA-based
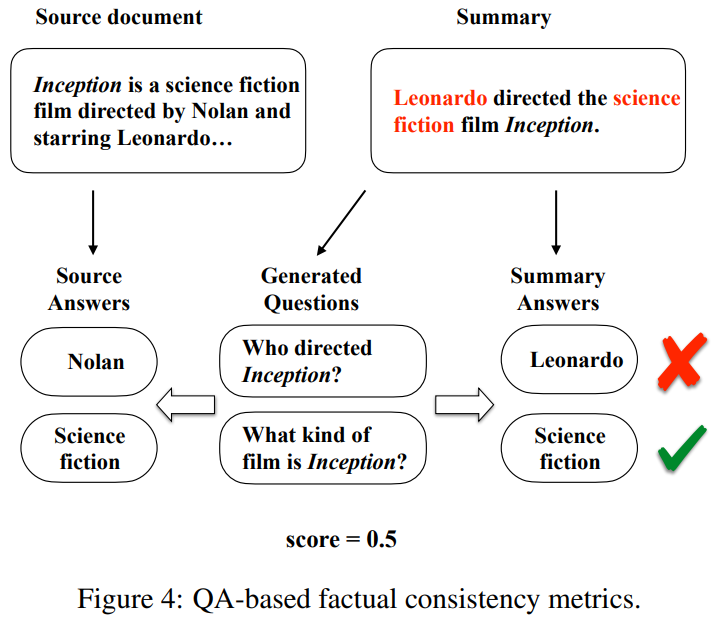
요약에서 automatic metric에 QA아이디어를 넣어서 Wang과 Drumus등[2020]은 factual consistency evaluation metrics에 기반한 QA, QAGS, FEQA를 제안했다. 이 두 metric은 모두 요약과 원문에 대한 질문을 했을 때, 요약이 원문과 factualy consistent하다면 우리는 유사한 답변을 받을거라는 직관을 기반으로 한다. Figure 4에 설명된 것처럼, 총 3가지 단계로 구성되어 있다.
1) 생성된 요약을 바탕으로 질문 생성(QG) 모델이 요약에 대한 질문 set를 생성한다. 이 때 보통 답은 entity의 이름과 요약에서의 key phases에 관한 것이 된다.
2) 원문이 주어질 때, QA모델을 사용해서 이 질문에 대해 답을 한다.
3) factual consistency score는 상응하는 답의 유사성에 기반해 계산된다.
entity-level에서 factual consistency를 계산하기 때문에, 이러한 방법들은 textual-entaiment 기반 모델보다 더 interpretable하다. QG와 QA의 독해 능력이 이 방식의 어느 정도의 성능을 가져온다. 하지만 이러한 방식은 계산 비용이 비싸다.
Other Methods
위의 방법들 외에, 몇 가지 간단하지만 효과적인 방법이 있다. Durmus 등[2020]은 factual consistency를 위한 직관적인 metric을 제안한다.
- word overlap-based metrics : 요약문과 각 원문의 문장을 하나씩 비교해 겹치는 단어 카운트, 이후 평균 or 최고점 선택
- ROUGE- BLEU
- Semantic similarity-based metric
- BERTScore
실험해보니, low-level의 생성 요약 데이터셋에서는 word overlap-based metric이 더 좋았고, highly 생성 요약 데이터셋에선 semantic similarity based metric이 더 좋았다.
요약 데이터셋의 abstractiveness는 원문 대비 reference summary가 얼마나 abstract되었는지를 의미한다. 극단적으로, 모든 reference summary가 각 원문에서 바로 추출될 때, 요약 데이터셋이 최소한으로 abstractive하다고 한다.
3.2 Weakly Supervised Metrics
Weakly supervised metrics은 특히 evaluating factual consistency를 위해 모델을 설계한다. 그리고 이러한 모델은 자동적으로 요약 데이터셋에서 생성되는 synthetic data에 대해 학습된다. 평가되는 objects에 따라서, 현존하는 metric들은 크게 3가지 카테고리로 나뉠 수 있다 : sentence-level, entity-level, token-level
Sentence-level
Kryscinski 외[2020]은 FactCC를 제안했고, 이 모델은 원문이 주어질 때 요약 문장에 대해 factual consistency를 확인한다. FactCC는 pre-trained langauge model BERT를 이진 분류기로 fine-tuning함으로써 구현된다. 그리고 이후에 요약 데이터셋 CNN/DM으로부터 syntectic training data를 자동 생성하는 것을 제안한다. 학습 데이터들은 원문에서 처음에 문장 하나를 샘플링하고, 후에 이를 claims로 refer한다. Claims은 이후 output이 positive 혹은 negative label인 novel sentence가 되는 textual transformation의 집합을 통과한다. positive examples는 의미적으로 불변인 변형(like paraphrasing)에 의해 생성된다. negative examples는 negation과 entity swap과 같은 의미적으로 변하는 변형을 통해 생성된다. FactFF는 원문과 요약문을 input으로 받아서, 요약문에 대한 factual consistency label를 output으로 반환한다. 다른 종류의 factual inconsistency error를 만들면서, 이 방법은 factual consistency evaluation에서 향상된 성과를 거뒀다. 하지만, 이러한 rule-based dataset 구축은 performance bottleneck을 가져온다. 모든 종류의 factual inconsistency error를 만들기는 어렵기 때문이다.
Entity-level
Zhao 외[2020]은 HERMAN을 제안한다. 이는 quantity entities(number, dates, 등)의 factual consistency를 평가하는데 집중한다. HERMAN은 input은 원문과 요약문이고, output은 inconsistent quantity entities를 구성하는 토큰을 가리키는 label sequence인 sequence labeling architecture를 기반으로 한다. 이 HERMAN을 위한 syntectic training data는 자동적으로 요약문 데이터셋인 XSUm에서 생성된다. sampling document sentence를 claims으로 샘플링하는게 아니라, reference summary를 claims으로 사용한다. 그리고 이러한 claims는 positive summaries로 바로 라벨링된다. negative summaries는 positive summaries에서 quantity entities를 교체함으로써 생성된다.
Token-level
Zhao 외[2020]은 token-level에 대한 factual consistency 평가 방법을 제안한다. 이는 sentence-level 혹은 entity-level에 비해 더 세밀하고 설명가능하다. 이러한 token-level metric은 pre-trained langauge model을 fine-tuning함으로써 구현된다. Zhoa 외[2020]처럼, reference summaries는 바로 positive examples에 라벨링되고, negative examples는 reference summaries의 부분을 reconstructing함으로써 생성된다. 이러한 방법은 human factual consistency evaluation과 더 높은 상관성을 보인다.
이러한 weakly supervised metrics은 최근에 더 이목을 끌고 있다. 하지만 이 방법들은 여전히 많은 양의 human annotated data(원문, 모델이 생성한 요약문, factual consistency label)가 필요하다는 한계가 있다. 그러나 이러한 데이터를 제작하는 것은 많은 시간과 돈이 든다. 현재 weakly supervised methods는 자동으로 training data를 heuristic을 갖고 생성하지만, 그들은 document sentences 또는 reference summaries를 positive와 negative examples를 생성하는데 사용한다. 그럼에도 불구하고, 둘다 요약 모델에 의해 생성된 요약문과는 다르다. 그래서 현재 모델 기반 방법들이 학습 데이터셋에서 효과를 보여줌에도 불구하고, 현실에서 이를 적용하기엔 매우 제한적이다.
3.3 Meta Evaluation
factual consistency metrics에 대한 효과를 증명하기 위해, 대부분의 관련 논문들은 그들의 metric과 human-annotated factual consistency score가 상관성이 높다는 것을 보인다. 그러나, 여러 annotating setting이 다양하기 때문에 각 metric끼리 상관성으로 비교하기엔 여전히 어렵다는 문제가 있다. 다양한 factual consistency metrics의 효과를 측정하기 위해 Gabriel 외[2020], Koto 외[2020]은 요약에서 factual consistency의 meta-evaluation을 실행했다. 그들은 여러 metrics에 의해 얻은 점수와 같은 그룹의 annotator에 의해 측정된 점수 사이의 상관성을 계산함으로써 여러 factual consistency metrics의 질을 평가하였다.
meta-evaluation을 통해, Koto외[2020]은 semantic similarity-based method(ex. BERTScore)가 XSum과 같은 highly 생성 요약 데이텃셋에서 optimal model parameters을 찾으며 factual consistency evaluation에 대한 SOTA를 도달할 수 있었다고 밝혔다. 그럼에도, human evaluation과 상관성은 0.5이상을 넘지 못한다. 그럼으로 factual consistency evaluation은 여전히 열려있는 문제이다.
4 Factual Consistency Optimization
우리는 factul consistency쪽으로 요약 시스템을 optimizing하는 접근법에 대해 개괄적인 시각을 제공한다. 아래 그림과 같이, 우리는 현존하는 methods를 각각의 방법이 기반하고 있는 원리에 따라 크게 4가지 클래스로 나눴다 : fact encode-based, textual entailment-based, post-editing-based, 그리고 이 외 방법.
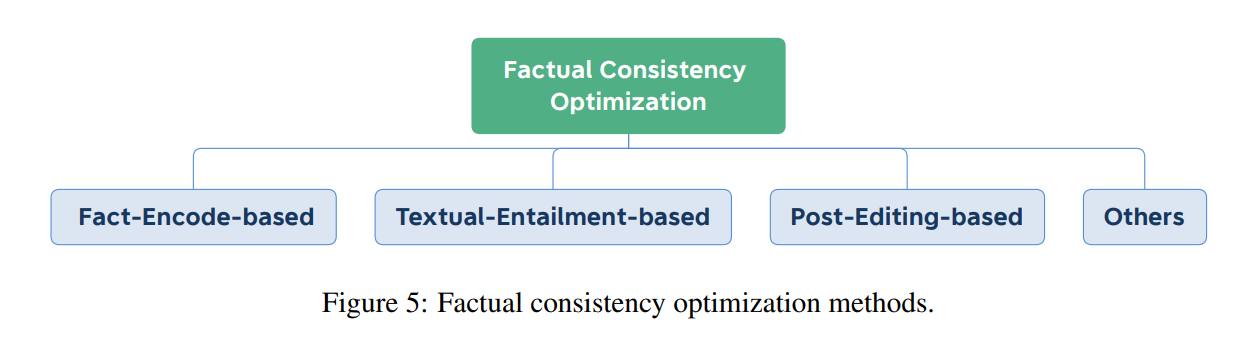
4.1 Fact-Encode-based
factual consistency에 대한 연구 초기에는, 대부분의 연구가 주로 intrinsic factual inconsistency error에 초점을 두고 있었다. Intrinsic factual inconsistency error는 원문의 fact와 틀리게 전한다. 이는 보통 다른 fact에서 의미적인 unit의 cross-combination을 보면 명백하다. 예를 들어, "Jenny likes dancing. Bob likes playing football."을 "Jenny likes playing football"이라고 하는 경우이다. 이러한 에러의 원인은 모델이 원문에서 fact를 잘못 이해하기 때문이다.
요약 시스템이 fact를 제대로 옳게 이해하도록 하기 위해, 가장 직관적인 방법은 원문에서의 fact를 외재적으로 모델링하는 것이다. 이 아이디어에 따라, fact encode-based methods는 처음에 원문에서 fact를 추출(보통 relation triples(subject; relation; object))한다. 그리고 나서 이러한 방법들을 추가적으로 요약 모델에 추출한 fact를 encode한다. fact를 encoding하는 방법에 따라, 이러한 방법들은 크게 2가지로 나눌 수 있다 : sequential encode와 graph-based encode
sequential fact encode
Cao 외[2018]은 두 개의 RNN encoder와 한 개의 RNN decoder 로 구성된 FTSum을 소개한다. FTSum은 원문의 사실을 "fact description"이라 하는 string으로 concatenate한다. encoder하나는 원문을 encode하고, 또 다른 decoder는 fact description을 encode한다. 이후, decoder가 summary를 요약할 때 두 개의 encoder를 attend한다. 실험 결과는 FTSum이 크게 factual inconsistent error를 줄였음에도 불구하고, FTSum이 모든 fact에서 entities사이의 interaction을 포착하는 것은 어렵다.
graph-based fact encode
이 문제를 해결하기 위해, Zhu 외[2020];Huaning 외[2020]은 원문에서 fact를 knowledge graph로 모델링하는 방법을 제안한다. 트랜스포머 기반의 요약 모델인 FASum(Fact-Aware Summarization)은 각 노드의 표현을 학습하기 위해 graph neural network(GNN)을 사용하고, 이를 요약 모델에 녹인다. FASum과 비교해서, ASGARD(Abstractive Summarization with Graph Augmentation and semantic-driven RewarD)는 output에 대해 semantic understanding을 모델이 습득하도록 mutiple choice cloze reward를 사용한다.
원문에서 fact의 표현을 강화시키는 것에 더해, commonsense knowledge를 합치는 것은 요약 시스템이 fact을 이해하는걸 용이하게 한다. 그러므로, Gunel 외[2019]는 위키데이터에서 commonsence knowledge graph를 구축하기 위해 relation triples를 샘플링한다. 이러한 knowledgd graph에서, 유명한 multi-relational data modeling 방법인 TransE은 entity embedding을 학습하는데 사용된다. 그리고 요약 시스템은 원문을 encoding했을 때 관련 entities의 임베딩을 attend한다. 이런 방법에서, commonsiense knowledge는 요약 시스템으로 통합된다.
4.2 Textual-Entailment-based
factual consistent summary는 의미론적으로 원문에 entail된다는 아이디어에 따라, Li외[2018]은 entailment knowledge를 요약 모델로 통합시키려는 목표를 가진 entailmoent-aware summarization model을 제안한다. 특히, 그들은 entailment-aware encoder와 decoder의 pair를 제안한다. entailment-aware encoder는 요약 생성과 textaul entailment prediction을 학습하는데 사용된다. 그리고 entailment-aware decoder는 Reward Augmented Maximum Likelihood(RAML) training에 의해 구현된다. RAML은 직접 task-specific reward(loss)를 최적화하는 계산적으로 효과적인 방법을 제공한다. 이 모델에서 reward는 생성된 요약의 entailment score이다.
4.3 Post-Editing-based
위의 두 가지 방법은 모델 구조를 수정해 요약 시스템을 factual consistency쪽으로 최적화한다. 이러한 방법들과 달리, post-editing-based method는 모델이 생성한 요약을 요약의 초고를 보고 fact corrects를 사용해 후처리(post-editing)해 최종 요약의 factual consistency를 강화한다. Fact correctors는 input으로 원문과 요약 초고를 받고, 최종 요약으로 수정된 요약문을 생성한다.
QA sapn selection task에 아이디어를 받아, Dong 외[2020]은 SpanFact를 제안한다. 이는 2개의 span selection-based fact correctors로 구성되고, 이는 반복적으로 entitiy를 수정하거나 auto regressive한 태도로 각각에 대해 entity를 수정한다. fact correcting을 수행하기 전에, 하나 또는 모든 entity(iterative - 1개, auto-regressive - 전체)는 mask된다. 그리고 SpanFact가마스크 토큰에 상응하는 것으로 교체하기 위해 원문에서 spans를 선택한다. SpanFact를 학습하기 위해, 데이터셋을 자동으로 구축한다.
Human evaluation은 SpanFact가 성공적으로 약 26%의 factually inconsistent summaries를 수정하고, 1% 미만의 factually consistent summary를 틀리게 오염시킨다고 밝혔다.
SpanFact보다 더 간단하게, Cao 외[2020]은 더 많은 종류의 error를 수정할 수 있는 End-to-End fact corrector를 제안한다. 이 End-to-End fact corrector는 pre-trained langauage model BART를 인공 데이터로 fine-tuning함으로써 구현된다. 오염된 요약을 input으로 받고, output은 고쳐진 요약이다. 이 방법이 더 SpanFact보다 개념적으로 더 많은 factually inconsistent error를 수정할 수 있다하더라고, 이는 human envaluation result에서 SpanFact를 넘지 못했다.
Dong 외[2020]과 Cao 외[2020] 둘다 비싼 humman annoation대신 자동으로 인공 데이터를 구축했다. 그러나, 이 학습 단계(which learns to correct the corrupted reference summaries)와 test단계(which aims to corerect the model-generated summaires)의 사이의 갭은 posting-editing-based methos의 성능을 제한한다. 오염된 reference summaries와 모델이 생성한 summaries는 다른 데이터 분포를 가지기 때문이다.
4.4 Other
위의 방법과 다르게, 유용하지만 domain-specific한 방법들이 있다.
- Matsumatu 외[2020]는 모델이 종종 factually inconsistent summary를 만드는 원인으로 unfaithful documment-summary pair에 있다고 봤다. 이러한 문제를 줄이기 위해, 그들은 textaul entailment classifier로 inconsistent training examples를 거르는 방법을 제안한다.
- Mao 외[2020]은 inference 단계에서 constraints를 적용하는 방법으로 factual consistency를 향상시켰다. 특히 모든 제약을 충족시켰을 때만 요약 생성이 완료된다. 그리고 제약은 중요한 entities와 keyphrases이다. infer단계 때만 작동하기 때문에 어떤 생성 요약 모델에도 붙일 수 있다는 장점이 있다. 하지만, 이 방법에 의해 factual consistency가 얼마나 향상되었는지랑 어떻게 더 유용한 제약을 설계할지는 아직 연구중이다.
뉴스 분야와 비교적 같은 열린 도메일 요약과 비교해, 특정 필드에서 factual consistency쪽으로 최적화하는 방법은 필드 특성에 따라 더 다르다. 의료 분야에서는 radiology reports summarization의 factual consistency를 최적화하는 방법을 제안한다. 또한 e-commerce분야에서도 e-commerce 상품 요약의 factual consistency를 최적화하는 방법을 제안한다.
5 Conclusion and Future Directions
향후 과제로 다음을 제안한다.
1. Optimization for Extrinsic Errors : extrinsic factual inconsistency를 막을 방법
2. Paragraph-level Metrics : 문단 단위의 평가 지표
3. Factual Consistency in other Coditional Text Generation : 이미지 캡셔닝이나 비주얼 스토리텔링과 같은 conditional text generation task에서 발생하는 factual inconsistency를 해결할 방법
