- 본 논문은 2019 NeurIPS에 실린 논문으로, 강화학습을 사용해 좀 더 flexible하고 amenable한 sequence를 생성하는 모델을 제안
- token을 step-by-step으로 생성하는 것이 아니라, insertion 혹은 deletion을 사용해 현재 state를 수정하는 형식으로 generation을 하는 모델
Introduction
- 현재 decoding model의 lack of flexibility를 해결하기 위해 모델을 고안
- 기존의 framework에서는 생성할 시퀀스의 길이를 고정하거나 decoding proceeds에 따라 step-by-step으로 시퀀스의 길이를 늘림
- 하지만, 사람이 글을 쓸 때를 생각해보면 한 번에 하나의 단어를 늘리는 것이 아니라 썼던 것을 다시 지우기도, 중간에 단어를 추가하기도 함
=> 기존 방식은 human-level intelligence와 갭이 존재
==> LevT에서는 이러한 갭을 줄이기 위해 기존의 decoding mechanism을 2가지 operation(insertion과 deletion)으로 바꿈!
- LevT를 imitation learning을 사용해 학습함
- sequence generation을 강화학습에 대입하여 expert model의 policy를 따라서 학습하는 방식
- 즉, decoder가 initial state가 low-quality generated sequence일 때 refinement model처럼 작동하면서 sequence를 생성
=> 그래서 MT로 학습된 LevT모델을 바로 translation post-editing에 적용할 수 있음
Contribution
- insertion과 deletion으로 구성된 새로운 sequence generation model, Levenshtein Transforemer(LevT)를 제안
- dual policy를 다루는 imitation learning의 framework을 기반으로 모델을 학습하는 learning algorithm을 제안
- sequence generation과 refinement를 일원화한 최초의 모델
Problem Formulation
Sequence Generation and Refinement
- sequence generation과 refinement문제를 Markov Decision Process(MDP)문제로 상정
- MDP는 로 구성
- as set of discrete sequences up to length where is a vocabuary of symbols
- 모든 decoding step마다 agent는 input 를 받아서 action 를 선택하고 reward 을 얻음
- 일반적으로 으로 D는 distance measurement
- agent는 policy 에 의해 모델링 됨
(policy는 y를 A에 대한 확률 분포로 맵핑)
Actions : Deletion & Insertion
- MDP formulation을 따라서, subsequence 에서 2가지 action을 사용해 을 생성할 수 있음
- 여기서, 과 은 special symbol 와로 설정
Deletion
- 모든 토큰 에 대해 deletion policy 는 binary decision을 함(0이면 해당 토큰 삭제, 1이면 해당 토큰 유지)
Insertion
- insertion의 경우 deletion과 달리 세부적으로 2단계, placeholder를 예측하는 단계와, token을 예측하는 단계로 나뉨
- 우선, 에서 가능한 모든 inserteds slots 에 대해, 는 몇 개의 placeholder가 추가할지에 대한 확률을 예측
- 이후 예측한 모든 placeholder에 대해서 token prediction policy 가 placeholder를 vocab에 있는 실제 token으로 교체
Policy combination
- sequence generation의 1 iteration을 3가지 단계로 분해할 수 있음 : delete tokens - insert placeholders - replace placeholders with new tokens
- the policy for one iteration is :
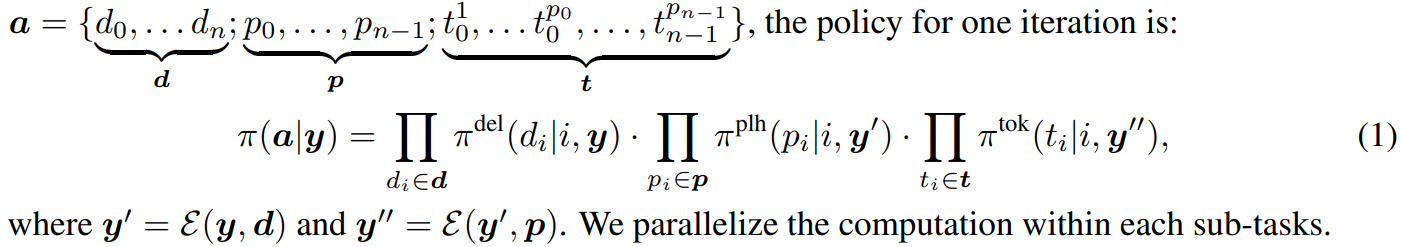
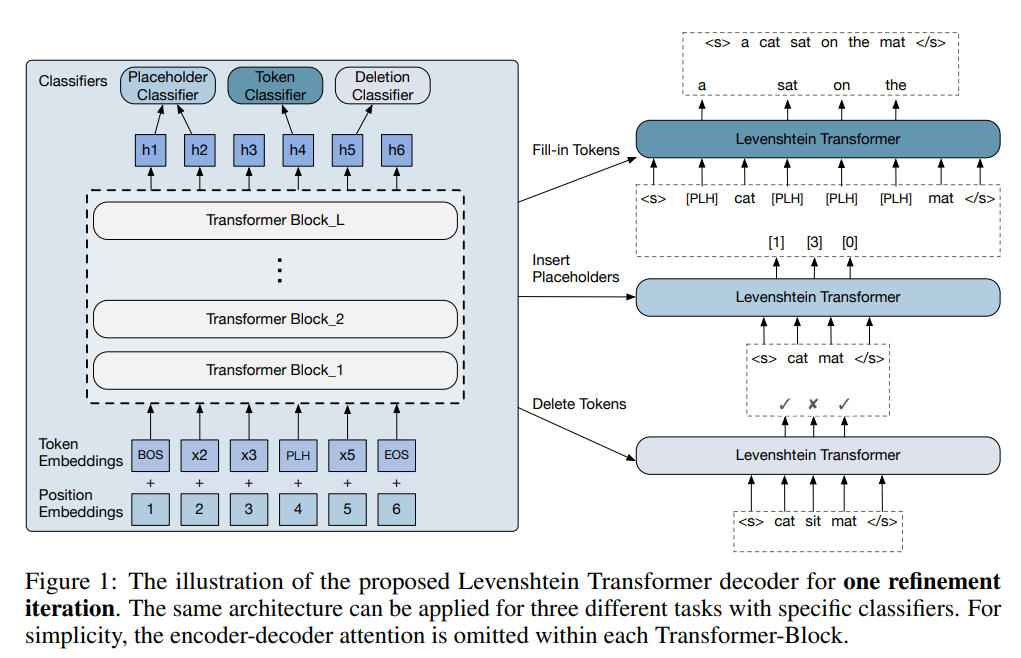
Levenshtein Transformers
Policy Classifier
-
Deletion Classifier
: LevT가 boundaries를 제외한 모든 input token에 대해 각 토큰이 deleted될지 kept될지를 결정
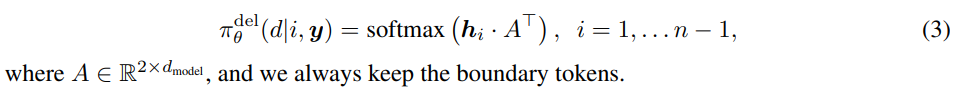
-
Placeholder Classifier
: LevT가 모든 연속된 position pair에 대해서 몇개의 토큰이 inserted될 것인지를 결정
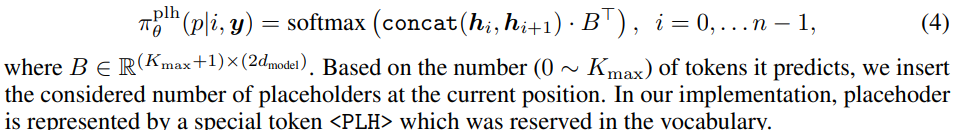
-
Token Classifier
: LevT가 모든 placeholder에 대해서 채워넣을 토큰을 예측
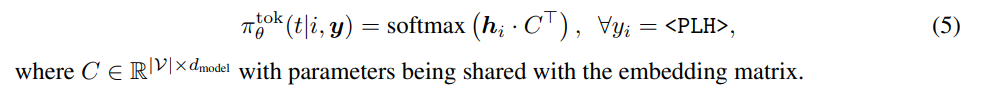
Weight Sharing
-
defalut implementation은 3가지 operation에 대해서 같은 Transformer backbone을 공유
Early Exit
-
performance과 computational cost를 trade-off할 수 있게, 중간 단계의 블럭에 classifier를 붙여 early exit를 수행하는것 을 제안(과 에)
(마지막 h를 바탕으로 decision하는게 아니라 중간 레이어의 h를 바탕으로 decision할 수 있도록!)
Dual-policy Learning
Imitation Learning
-
Levenshtein Transformer를 학습시키기 위해 imitation learning을 사용
-
expert policy 에서 끌어낸 행동을 agent가 따라하도록 함
- exper policy는 ground-truth target을 그대로 사용하거나, sequence distillation으로 필터링된 less noisy version을 사용
-
다음 식을 최대화하도록 목적함수가 구성됨
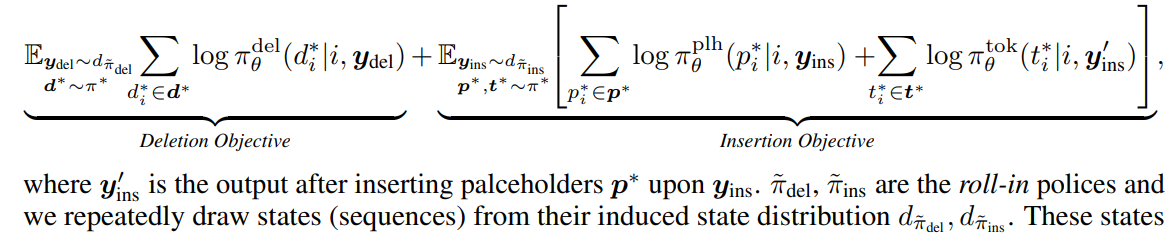
-
roll-in policy : 학습 동안 에 주어지는 state distribtuion을 결정
- ground-truth에 noise를 더하거나 adversary policy에서 나온 결과값을 사용


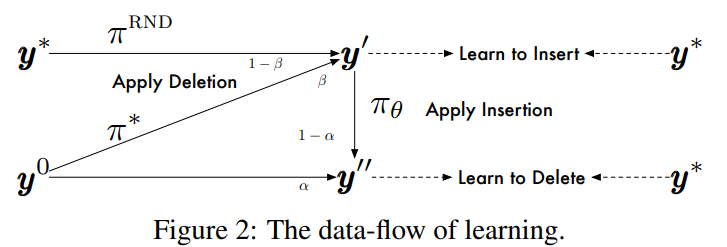 (즉, insertion을 학습하기 위해 deletion을 적용하거나 ground-truth에서 랜덤하게 토큰을 삭제한 상태를 입력값으로 사용하고, deletion을 학습하기 위해 initial input혹은 insertion을 적용한 상태를 입력값으로 사용)
(즉, insertion을 학습하기 위해 deletion을 적용하거나 ground-truth에서 랜덤하게 토큰을 삭제한 상태를 입력값으로 사용하고, deletion을 학습하기 위해 initial input혹은 insertion을 적용한 상태를 입력값으로 사용)
- ground-truth에 noise를 더하거나 adversary policy에서 나온 결과값을 사용
-
즉, roll-in policy로 만든 state에서 expert의 action을 할 확률을 최대화하도록 함
-
Expert Policy
- imitation learning에서 사용할 export policy를 구축
- 본 논문에서는 2가지 종류의 expert를 사용
-
Oracle : One way is to build an oracle which accesses to the ground-truth sequence. It returns the optimal actions

-
Distillation : 먼저 같은 dataset를 사용해서 auturegressive teacher model를 학습한 후 groud-truth sequence 을 teacher-model의 beam-search결과인 로 교체. 이후 1번과 같은 방법을 사용해 action 반환

Inference

- 연속된 2개의 refinement iteration의 결과가 같거나 matimum number of iteration에 도달했을 경우 decoding을 멈춤
- "empty" placeholder의 경우 output을 짧아지게 할 수 있으므로 이에 대해 패널티를 부여(eq 4에서 0의 logit에 penalty term 을 뺌)
Experiments
-
machine translation(MT), text summarization(TS), automatic post-editing(APE) for machine translatione에 대해 실험을 진행
Sequence Generation
-
sequence generation의 관점에서 LevT를 평가
-
sequence generation은 empty 를 input으로 가정, initial deletion은 적용 X
-
dataset으로는 Ro-En(WMT'16), En-De(WMT'14), En-Ja(WAT2017 Smal-NMT)를 사용, 평가 지표로는 MT에선 BLEU를, TS에선 ROUGE-1,2,L를 사용
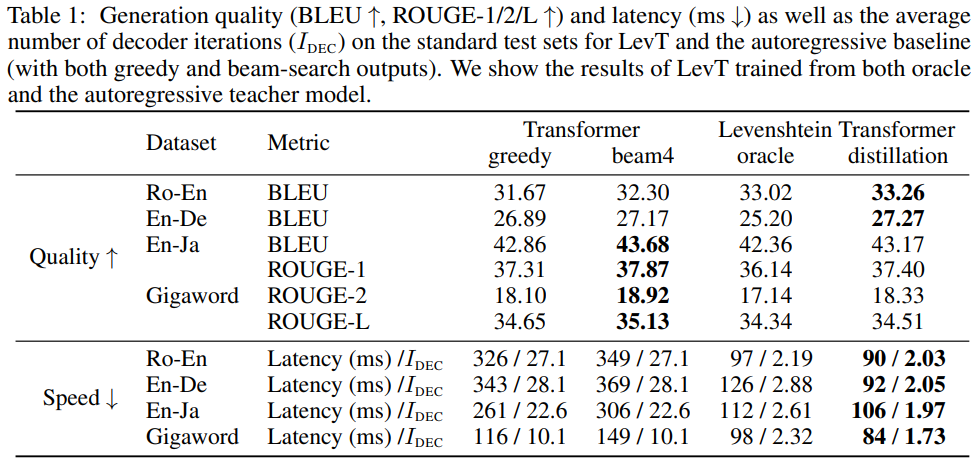
-
전반적으로 Transformer에 견줄만한 성능을 내면서 훨씬 빠른 decoding 속도를 보임
-
LevT의 경우 보통 2번의 iteration이면 decoding이 끝나는 것을 볼 수 있음
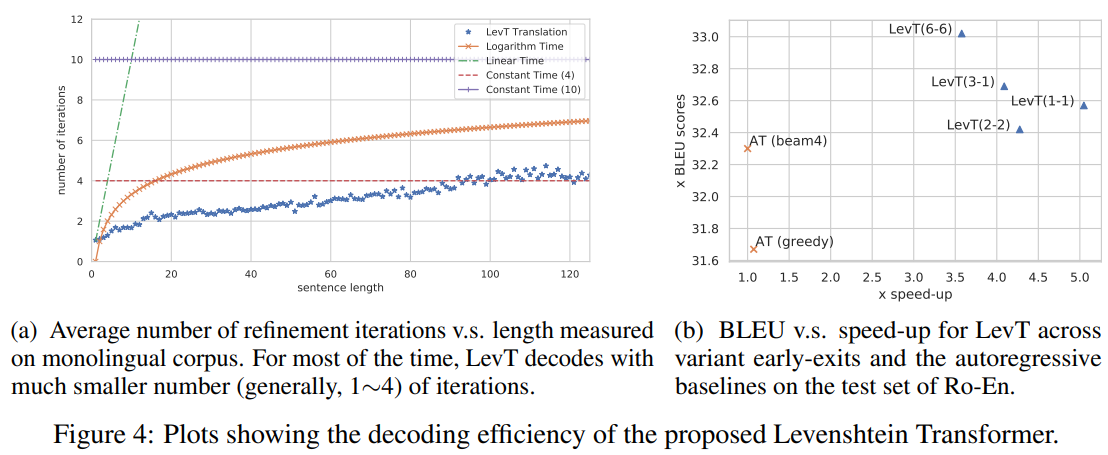
-
Figure 4a를 보면, monolingual corpus에 대한 input의 길이에 따른 iteration의 평균 횟수가 나타나 있음
-
Figure 4a에서 IT와 MaskT는 기존 refinement-based model의 성능을 보여줌
- 본 논문에서 제안하는 모델이 명시적으로 insertinon과 deletion을 구분하여 학습하기 때문에 refinement process를 학습하기 위해 유사한 denoising objective를 사용해도 타 모델들 보다 뛰어난 성능을 보임
-
Figure 4b를 보면, early exit를 넣었을 때의 속도 vs 성능 을 볼 수 있음(LevT(m-n) as a model with m and n blocks for deletion)
-
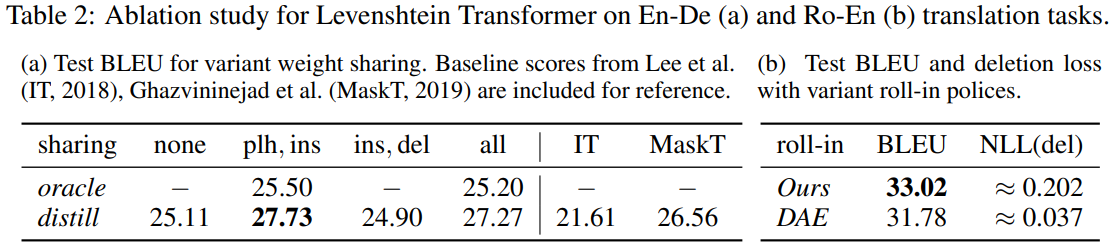
Weight sharing했을 때의 결과가 Table 2a에, roll-in polices로 eq6(Ours)과 eq6에서 mixing하지 않은 버전(DAE)을 사용했을 때의 결과가 Table 2b에 나타나 있음(확실히 DAE가 deletion loss가 훨씬 적음)
Sequence Refinement
- dataset으로 크게 2가지를 사용
- 기존의 MT dataset의 반을 바탕으로 MT systemt을 학습, 이후 나머지 반절을 바탕으로 MT모델이 낸 output을 input으로, ground-truth를 output으로 refinement model학습
- real APE task에서는 WMT17 Automatic Post-Editing Shared Task에서 En-De의 데이터를 활용
- baseline모델에서는 source와 MT system의 output을 concat해서 encoding
- statistical phrase-based MT system과 RNN-based NMT system을 사용
- BLEU scores와 멀 경우, translation error rate(TER)를 추가적으로 적용(APE literature에서 널리 사용되는 방식)
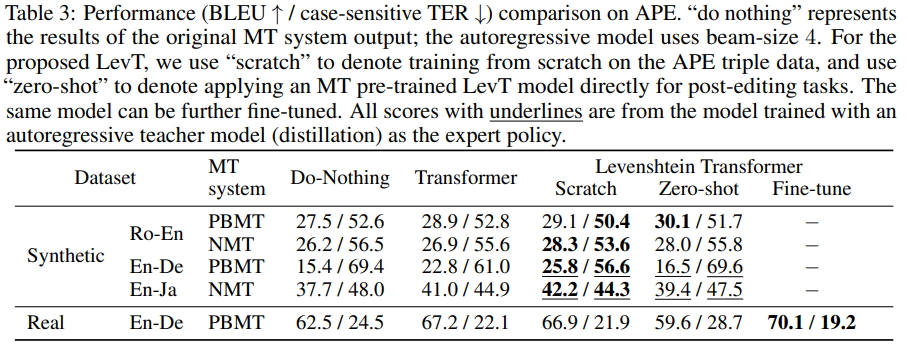
- Table3에서 do notiong은 원래 MT system의 output 결과를, scratch는 APE triple data에 대해 바닥부터 학습한 것을 의미, Zero-shot은 MT pre-trained LevT model에 바로 post-editing task를 적용한 것을 의미
- ((Underline은 뭐징 . . ? NMT는 RNN기반 모델이라면서 Transforemr는 또 뭐람. . .?))
- 실험 결과, 대부분의 경우에서 autoregressive Transformer보다 좋은 성능을 보임
- 하지만 do-nothing과 LevT의 성능 차는 미비..'
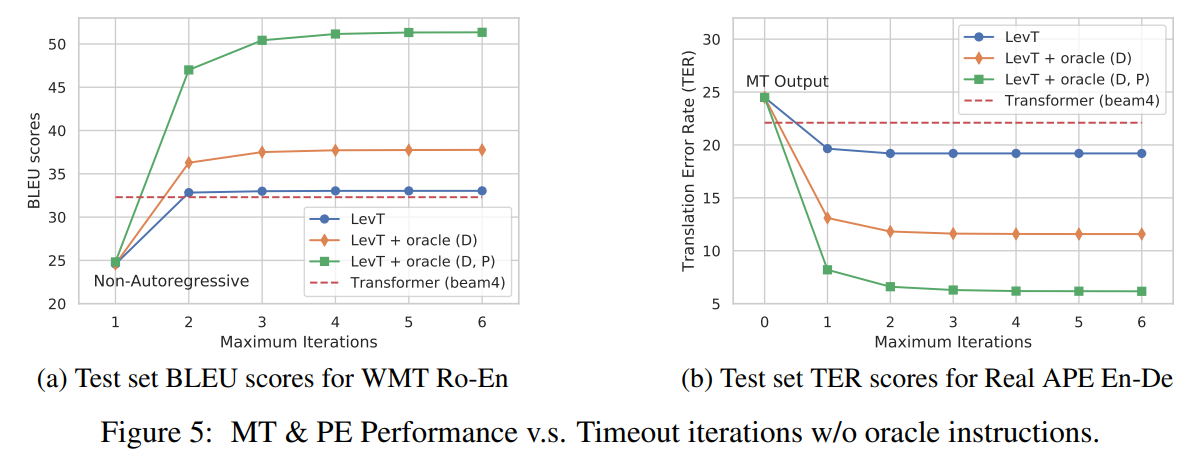
- Figure 5를 보면 2번의 iteration으로도 높은 성능을 달성한다는 것을 볼 수 있음
- 특히, oracle(e.g. human translators) 지시를 LevT가 얼마나 잘 적용하는지에 확인할 수 있음
Conclusion
- insertion과 deletion을 기반으로 작동하는 neural generation model, Levenshtein Trnasformer를 제안
- 제안된 모델은 기존의 autoregressive model에 준하는 성능을 보이면서, 훨씬 빠른 decoding 속도를 보임
- generation sequence와 refinement를 한 모델에서 구현할 수 있음을 보임
- 이 모델을 바탕으로 human-in-the-loop generation으로 확장할 수 있는 여지를 보임
