점점 자바스크립트 언어 자체에서 브라우져까지 공부하게 되는 것을 알 수 있다. 자바스크립트는 node.js 나 electron 같은 런타임 환경을 제공받아 사용할 수도 있지만, 기본적으로는 브라우저 환경에서 사용되도록 만들어진 언어이다. 그러므로 브라우저에 대한 의존성이 높고, 개발자는 브라우저 조작에 대해 잘 알고 있어야 한다.
DOM
DOM이란?
DOM 은 document object model 의 줄임말로, HTML을 파싱해서 만들어지는 HTML의 계층 구조와 정보를 제어할 수 있는 트리 자료구조이다.
DOM은 노드객체의 계층 구조로 표현된다. 그리고 노드 객체에는 총 12개의 종류가 있다. 이 노드 객체들이 조합되어 DOM을 이룬다.
노드 객체
문서 노드
document.querySelector() 이렇게 사용하는 document 객체를 문서 노드라 한다. HTML 문서 전체를 가리키는 객체로서 window 객체에 프로퍼티로 바인딩 되어 있다. 그러므로 문서 당 하나밖에 존재하지 않는다.
요소 노드
HTML 태그가 노드 객체로 만들어지면 요소 노드가 된다.
어트리뷰트
class, id 등 HTML 요소의 어트리뷰트를 가리키는 객체이다. 요소 노드는 계층 구조를 나타내야하기 때문에 부모노드와 자식노드에 연결되어 있지만, 어트리뷰트 노드는 요소 노드에만 연결되어 있다. 이는 모자 관계가 아니다.
텍스트 노드
HTML 의 텍스트를 가리키는 객체이다. 텍스트 노드는 자식을 가질 수 없으므로 반드시 리프 노드여야 한다. 물론 리프 노드라고 모두 텍스트 노드는 아니다.
노드 객체의 상속 구조
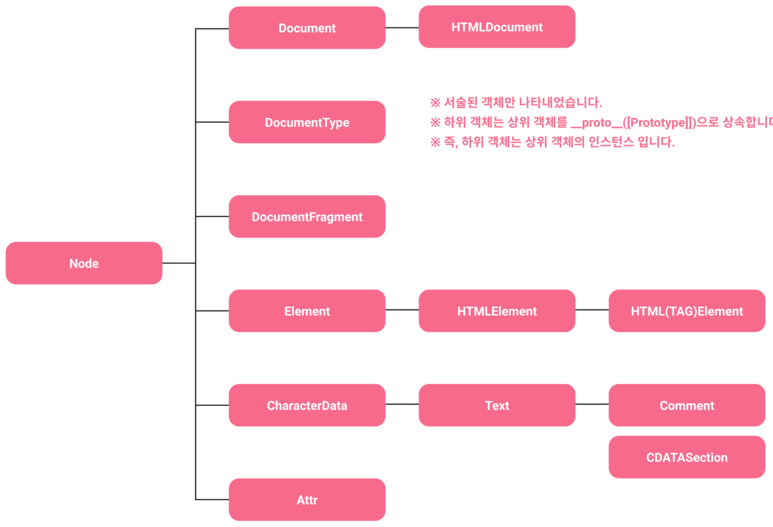
노드 객체는 위와 같은 상속 구조를 갖는다. 이 상속 구조는 DOM 트리의 상하위 구조와는 다르다. 이를 잘 구분하도록 하자.
이 그림에서는 나오지 않았지만, 노드는 Event Target 객체를 상속받는다. 예전에 말했듯이 Obejct.prototype은 자바스크립트 객체의 가장 상위 프로토타입이다. 이 Object.prototype과 Node.prototype 사이에 EventTarget.prototype이 존재한다. 이 말은 즉, DOM 트리에 모든 요소에 이벤트를 발생 시킬 수 있다는 뜻이다.
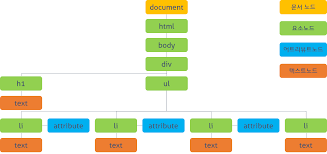
시사점
노드 객체의 상속 구조를 알아야 되는 이유는, 여러 DOM 노드 속성에 따라 제공되는 DOM Api 가 다르기 때문이다. 예를 들어 input 태그와, 일반 div 태그는 당연히 적용되는 프로퍼티가 다를 것이다. input 은 value 라는 프로퍼티가 존재하고 div는 존재하지 않는다.
또한 이 DOM 노드에 따라 제공되는 DOM api가 다르므로, 이 DOM api 를 자유자재로 다룰 수 있어야 하는 프론트엔드 개발자는 이 부분을 잘 알고 있어야 한다.
요소 노드 취득
우리가 DOM 요소를 조작하려면 특정 기준점이 되는 노드를 정하고 그 노드를 조작하거나, 그 노드의 주변 노드를 조작해야 한다. 매 조작 시점마다 루트 노드에서 특정 노드를 찾아갈 수는 없는 노릇이다. 물론 우리가 특정 노드를 취득하는 과정에서 탐색이 발생하겠지만 해당 내용은 브라우저가 최적화되어 해주니 잘 이용하도록 하자.
id를 통한 요소 취득
const $node = document.getElementById('아이디');이렇게 사용한다. getElementById 는 Document 프로토타입의 메서드이다. 그러므로 반드시 Document에서 호출해야 한다. 물론 다른 노드에서 써도 해당 노드의 하위 노드에서 아이디 요소를 찾아주긴 한다... 하지만 이건 브라우저의 친절함 덕분이니.. 원래 되는걸로 오해하지 말자.
개인적으로도 그렇고 일반적으로도 id는 정말 사용해야만 하는 곳에만 사용하는 것이 좋다고 생각한다. 왜냐하면 id 는 범용성이 떨어지기 때문이다.
이 외에도 tagName 을 통한 요소 취득, class 이름을 통한 요소 취득의 방법이 있지만, 사용을 추천하는 것은 CSS 선택자를 이용한 요소 취득이다.
그 이유는 getElementByTagName, getElementByClassName 으로 취득되는 요소가 라이브 객체이기 때문이다. 해당 내용은 아래에서.
CSS 선택자를 통한 요소 취득
const $node = document.querySelector('.hi');
const $node = document.querySelectorAll('.hi');전자는 해당 클래스가 하나를 가져오려고 할 때, 사용한다. 만약 해당 클래스를 가진 노드요소가 여러개라면 가장 첫번째 클래스 선택자의 노드만 가져온다.
아래의 querySelectorAll 은 클래스 선택자에 해당되는 모든 요소를 유사배열객체로 가져온다.
라이브 객체
라이브 객체란 객체의 변화를 실시간으로 반영하는 객체이다. 라이브 객체는 변화가 있을 때마다 실시간으로 객체 전체의 변화를 일으키기 때문에 예측이 힘들다.
특히 getElementByTagName, getElementByClassName 으로 요소를 취득하는 경우, HTML Collection 형태의 객체가 반환되는데, 이 객체가 라이브 객체이다.
예를 들어, getElementByClassName 으로 받아온 3개의 HTML Collection 객체가 존재한다고 가정하자. 이 유사배열객체를 순회하면서 첫번째 세번째에 있는 클래스만 active로 바꿔주는 코드가 있을 때, 일반적인 객체였다면, 전혀 문제 없는 코드였을 것이다.
하지만 이렇게 for문을 돌게 되면 해당 클래스가 변형되는 라이브 객체는 클래스가 변경되자마자 이 유사배열객체에서 제외되게 된다.
그러므로 0번의 객체가 첫번째 for문을 돌면서 즉시 클래스에 변경이 일어나 해당 유사배열 객체의 길이는 2로 줄어들게 된다. 그러므로 3번째 객체까지 돌지 못하고 for문이 끝나버린다. 그래서 세번째 요소는 클래스의 변경이 일어나지 않는다.
요소 탐색
마크업에 따라서 특정 요소를 취득할 수 없는 경우가 있다. 이런 경우, 주변에서 요소를 취득한 뒤 해당 요소를 탐색해야 한다.
왠만하면 처음부터 마크업을 제대로 해서, 이런 탐색 명령어로 코드를 더럽히는 일은 만들지 않는 것이 좋다고 생각한다.
탐색은 부모, 형제, 자식으로 갈 수 있다.
공백 텍스트 노드
요소 탐색을 할 때, 신경을 써주어야 할 부분이 공백 텍스트 노드이다. html 파일을 보면 엔터와 탭으로 구분되어 있는 것을 알 수 있는데, 이 부분이 파싱되어 DOM 트리로 만들어지면 공백 텍스트 노드가 된다. 이 부분은 생각하기 쉽지 않으므로 DOM 처리를 할 때 고려해야 되는 요소이다.
자식 노드 탐색
Node.prototype.childNodes
해당 프로퍼티로 자식 노드를 찾으면 공백텍스트 노드까지 포함되어, NodeList 유사배열객체로 반환된다.
Node.prototype.children
텍스트 노드를 제외하고 모든 요소를 HTMLCollection 객체에 담아 반환한다. 라이브 객체인걸 조심하자.
Node.prototype.firstChild
첫번째 자식 노드 반환. 텍스트 노드도 포함가능
Node.prototype.lastChild
마지막 자식 노드 반환. 텍스트 노드도 포함가능
Node.prototype.firstElementChild
첫번째 자식 노드 반환. 텍스트 노드 미포함
Node.prototype.lastElementChild
마지막 자식 노드 반환. 텍스트 노드 미포함
형제 노드 탐색
자식 노드를 탐색하는 것과 유사하게 형제 노드 또한, 이전과 이후, 텍스트노드를 포함한 탐색과 미포함한 탐색을 구분짓고 있다.
Node.prototype.previousSibling
이전 형제를 탐색한다. 텍스트 노드를 포함한다.
Node.prototype.nextSibling
이후 형제를 탐색한다. 텍스트 노드를 포함한다.
Node.prototype.previousElementSibling
이전 형제를 탐색한다. 텍스트 노드를 포함하지 않는다.
Node.prototype.nextElementSibling
이후 형제를 탐색한다. 텍스트 노드를 포함하지 않는다.
요소 노드의 텍스트 조작
텍스트 노드를 조작하는 방법은 두 가지가 있다. nodeValue 접근자 프로퍼티와 textContent 접근자 프로퍼티이다.
Node.prototype.nodeValue
nodeValue 접근자 프로퍼티는 getter 와 setter 모두 존재한다. 즉, 값을 받아올 수도 있고, 변경도 해줄 수 있다는 뜻이다.
하지만 이는 텍스트 노드를 참조했을 경우만 가능하다. 텍스트 노드가 아닌 노드를 참조했을 경우, null을 반환한다.
하지만 문제는 텍스트 노드는 요소 취득이 불가능하다. 요소 취득은 특정 id, class 등 탐색 기준이 되는 attribute 가 존재해야 하는데, 텍스트 노드에는 이런 attribute가 존재하지 않기 때문이다. 그래서 반드시 상위 노드나 주변 노드에서 요소를 취득해 탐색 프로퍼티를 사용해 접근해야 한다. 즉 코드가 복잡해진다.
Node.prototype.textContent
textContent와 nodeValue 와 마찬가지로 getter setter가 모두 존재한다. 하지만 nodeValue 와 크게 다른 점은 특정 노드의 textContent를 get 하면 해당 노드의 하위의 모든 텍스트 노드의 텍스트를 가져온다. 때문에 하위 노드에 텍스트 노드가 여러개 존재할 경우, 예상과 다른 결과를 불러올 수 있으니 조심해야 한다.
DOM 조작
바닐라 자바스크립트로 개발을 한다면 가장 중요한 부분이라고 생각한다. DOM이 굉장히 중요하기 때문에 여러가지 함수가 있을 거 같지만, 그렇게 많지 않다. 때문에 이 부분을 잘 알고있어야 한다.
innerHTML
Element.prototype.innerHTML은 getter setter 접근자 프로퍼티가 모두 존재한다. getter로 사용할 경우, 해당 하위 html 마크업이 문자열로 반환되고 setter 로 사용할 경우 해당 문자열을 DOM 으로 변환해준다.
innerHTML의 경우 받아온 문자열을 그대로 DOM 으로 만들기 때문에, input으로 받은 문자열을 그대로 DOM 에 반영한다면 위험할 수 있다. XSS(cross site scripting) 공격에 노출 될 수 있기 때문이다. 이런 위험이 노출될 수 있으면 해당 input 내용을 살균해주는 과정이 필요하다.
innerHTML 은 단점이 하나 더 존재한다.
$fruits.innerHTML = $fruits.innerHTML + `<li>banana</li>`이런 li 태그를 추가해주는 코드가 있다고 해보자. 나는 이 새로 추가 되는 li 태그만 DOM 트리에 추가하고 싶지만, 이 코드는 ul 태그 내부 전체를 다시 그린다. 변화가 있는 부분만 감지해서 추가하는 것이 아니라, set 되는 모든 내용을 다시 그려내는 것이다.
insertAdjacentHTML
그래서 많이 사용하는 것이 insertAdjacentHTML 메서드이다. 해당 메서드는 기존 요소를 제거하지 않고, 위치를 지정해 새로운 요소를 삽입할 수 있다.
이 메서드는 4개 중 하나를 인수로 받아, 삽입 위치를 지정해줄 수 있다.
$fruits.insertAdjacentHTML('beforebegin', `<li>banana</li>);
이렇게 사용할 수 있다.
이 인수는 beforebegin, afterbegin, beforeend, afterend 가 있다. 태그의 처음 부터 삽입 위치를 결정해준다.
