- 본 리뷰는 모두의연구소 공간 지원을 받아 작성되었습니다. *

Abstract
- 깊은 신경망은 트레이닝하기 어렵다.
- 이 논문에서는 깊은 네트워크 트레이닝을 쉽게 만드는 residual learning (잔차 학습) 프레임워크를 제시한다.
- 레이어가 입력을 참조하는 residual function (잔차 함수)를 학습하도록 명시적으로 재공식화한다.
Introduction
네트워크의 깊이가 중요하다는 증거들이 (2015 기준에서) 최근 제시되었다.
깊은 네트워크는 학습하기 어렵다. 우선 vanishing/exploding gradient로 인해 네트워크의 가중치가 제대로 수렴하지 못하는 문제가 있다. 이 문제는 normalized initialization 과 intermediate normalized layers으로 대처가 되었다. (Xavier, He의 weight 초기화와 Batch Normalization)
수렴 문제가 해결되자 degradation 문제가 발견되었다. 네트워크의 깊이가 깊어짐에 따라 나타나는데, overfitting과는 다르게 training error가 증가하는 현상이다.
- degradation이란?
degradation of training accuracy. 트레이닝 정확도의 저하.
degradation 문제는 모든 시스템(네트워크 구조)들이 비슷하게 최적화하기 쉬운건 아니라는 것을 암시한다. 얕은 모델 S와 여기에 레이어 몇개를 더한 깊은 모델 D를 생각해보자. 만들어진 방식에 의해, 깊은 모델 D에는 한 해답은 반드시 존재하게 된다. 얕은 모델 S에서 가져온 레이어들은 S와 같은 weight를 쓰고, 더해진 나머지 레이어는 identity 매핑으로 만드는 것이다. (아래 그림의 D1)
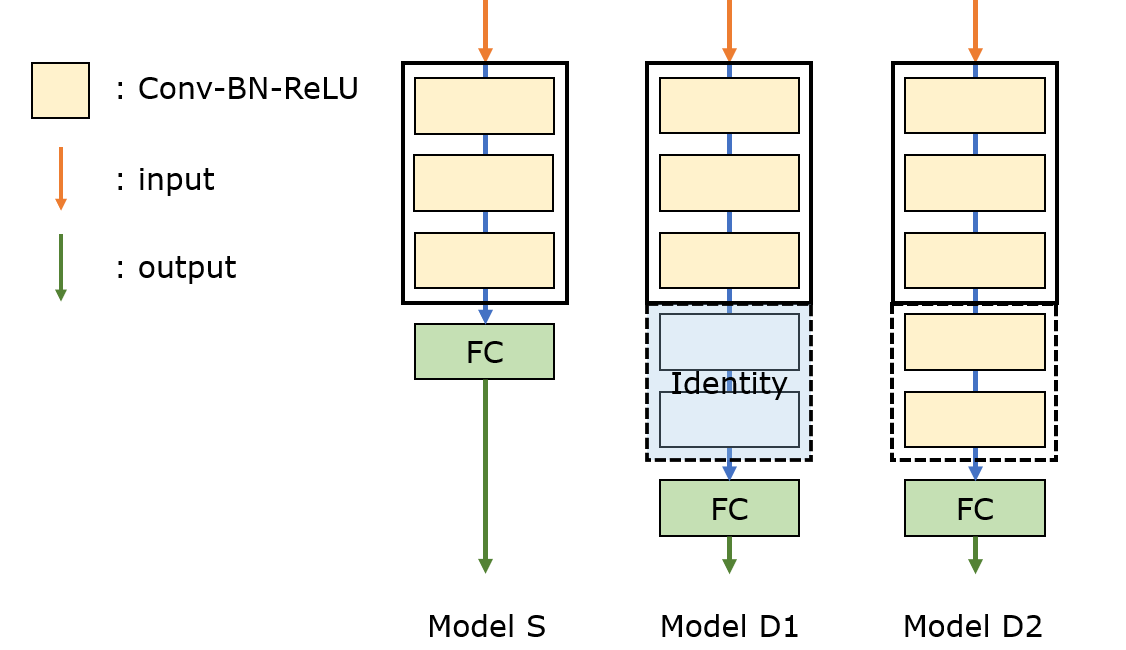
이 해답의 존재를 보아 깊은 네트워크 D는 S와 같거나 S보다 나은 training error를 내야 한다. 하지만 우리가 현재 사용하는 solver들로는 그런 해답을 못 찾는 경우가 실험적으로 나타난다.
solver: task와 모델이 주어졌을때 적합한 weights를 찾아주는 도구, 또는 optimizer라고 생각하면 될 듯
이 논문에서는 deep residual learning 프레임워크를 도입해서 degradation 문제에 대처한다. 몇개의 레이어들이 바람직한 매핑에 최적화되길 바라는 대신에, 명시적으로 레이어들이 residual mapping에 최적화되도록 만든다. 바람직한 기저의 매핑을 H(x)라고 하고, 적층된 비선형 레이어들을다른 매핑 F(x):=H(x)-x에 맞춘다. 그러면 원래의 매핑 H(x)는 F(x)+x로 다시쓰인다. 저자들은 잔차 매핑 F(x)에 최적화하는것이 unreferenced mapping H(x)에 최적화하는 것보다 더 쉽다고 가정한다. 극단적으로, identity 매핑이 최적인 상황을 가정하자. 이 때 비선형 레이어들을 identity 매핑이 되도록 최적화하는 것보다 잔차가 0이 되게 만드는 것이 쉬울것이다.
feedforward 신경망에서 F(x)+x라는 식은 “shortcut connections”를 갖고 구현될 수 있다. shortcut connection은 하나 혹은 여러개의 레이어를 뛰어넘는 연결이다. 이 논문의 경우에 shortcut connection은 단순히 identity 매핑으로 기능하고, 그 아웃풋은 적층된 레이어들의 아웃풋에 더해진다.
저자들은 ImageNet에서의 포괄적인 실험을 통해 degradation 문제와 residual learning에 대한 평가를 보여준다. CIFAR-10에서도 비슷한 현상을 보여준다. 따라서 이 현상들이 특정 데이터셋에만 국한된 것이 아니라는 것을 암시한다.
residual learning 프레임워크를 활용해 학습한 극단적으로 깊은 표현들은 다른 인식 과제들에서도 뛰어난 일반화 성능을 보여주었다. 그 결과 ImageNet classification 뿐만 아니라 ImageNet detection, ImageNet localization, COCO detection, 그리고 COCO segmentation에서 1위를 차지했다. 이러한 강한 근거를 보아 residual learning 원리는 일반적이다. 저자들은 residual learning이 다른 vision과 non-vision 문제들에도 적용가능할 것으로 예상하였다.
‘generalization performance on other recognition tasks’ 에서 generalization의 뜻을 잘 모르겠음
Related Work
중요하지 않아보이므로 생략
Deep Residual Learning
Residual Learning
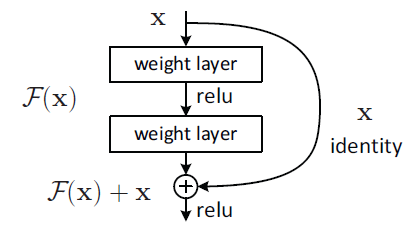
H(x)를 몇개의 적층된 레이어들이 맞추어야 하는 underlying mapping이라고 하자. x는 이 레이어들의 처음에 들어가는 입력이다. 여러개의 비선형 레이어들이 복잡한 함수를 점근적으로 근사할 수 있다고 가정한다면, 이는 레이어들이 잔차 함수 H(x)-x를 점근적으로 근사할 수 있다고 가정하는 것과 같다. 따라서 저자들은 적층된 레이어들이 H(x)를 근사할 것이라 기대하기보다, 명시적으로 이 레이어들이 잔차함수 F(x):=H(x)-x를 근사하도록 만든다. 원래의 함수는 따라서 F(x)+x가 된다. 비록 두 형태 모두 desired functions를 점근적으로 근사할 수 있겠지만, 그 난이도는 다를것이다.
이 재수식화는 직관과 반대되는 degradation 문제로부터 동기를 받았다. Introduction에서 다루었듯이, 만약 더해진 레이어들이 identity 매핑으로 구성될 수 있다면, 더 깊은 모델은 얕은 모델보다 크지 않은 training error를 가질것이다. degradation 문제는 solver들이 여러개의 비선형 레이어를 갖고 identity mapping을 근사하는데에 어려움을 겪는것을 암시한다. residual learning 재수식화를 통한다면, 만약 identity mapping이 최적이면 solver는 단순히 비선형 레이어들의 weight들을 0에 가까이 만들면 된다.
실제로 identity mapping이 최적인 경우는 별로 없지만, 재수식화는 문제의 사전 조건을 설정하는데 도움이 될 수 있다. 만약 최적의 함수가 zero mapping보다 identity mapping에 가깝다면 solver가 그 함수를 새로운 함수로써 학습하기보다는 identity mapping을 기준으로 했을 때의 변화량을 찾는 것이 더 쉬울것이다. 실험에서 학습된 residual function이 일반적으로 작은 반응량을 가지는 것을 볼 수 있다. 이는 identity mapping이 합리적인 사전조건을 제공함을 나타낸다.
Identity Mapping by Shortcuts
저자들은 residual learning을 몇개의 적층된 레이어마다 적용했다. 빌딩블록은 그림 2에 나와있다. 이 논문에서는 빌딩블록을 다음과 같이 정의한다:
… (수식 1)
여기서 x와 y는 레이어들의 입력과 출력 벡터들이다. 함수 F(x,{W_i})는 학습될 residual mapping을 나타낸다. 예를 들어 2개의 레이어를 가진 그림 2에서 이다. 는 ReLU를 뜻하고 bias는 생략되었다. 연산 F+x는 shortcut connection과 element별 덧셈에 의해 수행된다. 저자들은 덧셈 이후에 두 번째 비선형함수를 두었다.
수식1에 있는 shortcut connection 은 추가적인 파라미터도 연산량도 더하지 않는다. 이것은 실용 면에서 매력적일 뿐만 아니라 plain 네트워크와 residual 네트워크를 비교하는 데에 있어서 중요하기도 하다. 우리는 같은 수의 파라미터, 깊이, 너비, 그리고 연산비용(무시할 수 있는 element별 덧셈을 제외하고) plain/residual 네트워크를 공정하게 비교할 수 있다.
수식1에서 x와 F의 차원은 같아야 한다. 만약 그렇지 않은 경우(e.g. 입력/출력 채널수를 바꿀때), 우리는 차원을 맞추기 위해 shortcut connection에 의한 선형 투사 W_s를 할 수 있다.
정사각형 행렬 W_s는 수식1에서도 쓰일 수 있다. 하지만 identity mapping이 degradation 문제에 대처하기에 충분하고 경제적이라는 것이 실험에서 보일 것이다. 따라서 W_s는 오직 차원수를 맞출 때만 쓰인다.
residual function F의 형태는 유연하다. 실험에서 F는 2개 또는 3개 레이어를 가지는데, 그 이상의 레이어들도 가능하다. 하지만 F가 단 하나의 레이어만 갖는다면 수식1은 선형 레이어와 비슷해진다: . 여기에서 우리는 이점을 찾을 수 없었다.
위의 notation들은 간략함을 위해서 FC 레이어에 대해 쓰였지만, conv 레이어에도 적용가능하다. 함수 F(x,{W_i})는 여러개의 conv 레이어를 나타낼 수 있다. element별 덧셈은 두 피쳐맵에서 채널마다 적용될 것이다.
Network Architectures

우리는 다양한 plain/residual 네트워크들을 실험했고, 일관적인 현상을 관측했다. 논의를 위한 한 사례를 들기 위해, 우리는 ImageNet을 위한 두 모델을 다음과 같이 설명한다.
Plain Network. plain baselines는 주로 VGG 네트워크의 철학에서 영감받았다. 대부분의 conv 레이어들은 3x3 필터를 가지며 다음의 설계 법칙을 따른다: (i) 같은 출력 피처맵 사이즈에 대해서 레이어들은 같은 수의 필터를 가진다. (ii) 만약 피처맵 사이즈가 반으로 줄어들면, 필터 수는 두배로 증가해서 레이어마다의 시간복잡도를 유지한다. 우리는 downsampling을 stride가 2인 conv 레이어들을 통해서 수행한다. 네트워크는 global average pooling과 1000갈래의 FC 레이어, softmax로 끝난다. 그림3에서 weight를 가진 레이어의 총 숫자는 34이다.
우리의 모델이 VGG보다 더 적은 필터수와 낮은 복잡도를 가진다는것을 주목할 만 하다. 우리의 34-레이어 베이스라인은 3.6 billion FLOPs(multiply-adds)를 가지는데 이것은 VGG-19(19.6 billion FLOPs)의 18% 밖에 안된다.
3.6 billion = 36억
19.6 billion = 196억
Residual Network. plain 네트워크를 기반으로해서 우리는 shortcut connection을 삽입한다(그림 3, 오른쪽). 이것은 네트워크를 plain 버전에 상응하는 residual 버전으로 바꾼다. 입력과 출력이 같은 차원수일 때 identity shortcut은 바로 쓰일 수 있다(그림에서 실선). 차원 수가 증가할 때(그림에서 점선), 두 가지 선택지를 고려해본다. (A) shortcut은 여전히 identity mapping을 수행하며 증가한 차원에는 0이 패딩된다. 이 옵션은 별도의 파라미터를 부가하지 않는다. (B) 수식2에 있는 projection shortcut이 차원수를 맞추기 위해 사용된다. projection은 1x1 conv를 통해 이루어진다. shortcut이 두 가지 사이즈의 피처맵을 건너갈 때, 두 옵션 모두 stride 2를 갖고 행해진다.
Experiments
실험부분은 아래 블로그 참조
https://wandukong.tistory.com/18
https://jxnjxn.tistory.com/22

설명이 너무 깔끔해서 이해할 수 있었네요~