https://www.youtube.com/watch?v=f2XqxOny3NA&t=9s
위 자료를 참고했다.
정~말 오랜만의 기록..!
작년 12월부터 약 9개월간의 데이터사이언티스트 근무를 하느라.. 그동안 소홀히 해왔던 기록을 차근차근 다시 해보고자 한다.
6월 중순쯤부터 (내 입장에서는) 좀 큰 프로젝트를 맡았어서, 그걸 하느라 평소처럼 퇴근하고 공부하는 데 시간을 쓰지 못한 게 그대로 보인다..
다시 열심히 해봐야짓!
그리고, 근무를 하며 데이터 엔지니어링 & 데이터 분석 & 데이터사이언스 분야에 더 많은 관심이 생겨서, 이쪽 분야 공부를 중점적으로 하게 될 것 같다. 관심분야가 너무 방대해진 감은 있지만, 그래도 저 세 분야 중 한 분야도 빼놓을 수 없는 것 같다.
어쨌든, 다시 본론으로
SHAP 개념
- Shapley additive explanation
- 게임이론에 기반함
SHAP 계산 예제
- 아래 예제에서 X1 변수에 대한 Shapely value 계산 부분에 주목
- X1변수를 제외한 나머지 변수의 사용 경우의 수마다 X1변수의 사용여부에 따른 예측값 비교
- 사용 O 예측값 - 사용X 에측값
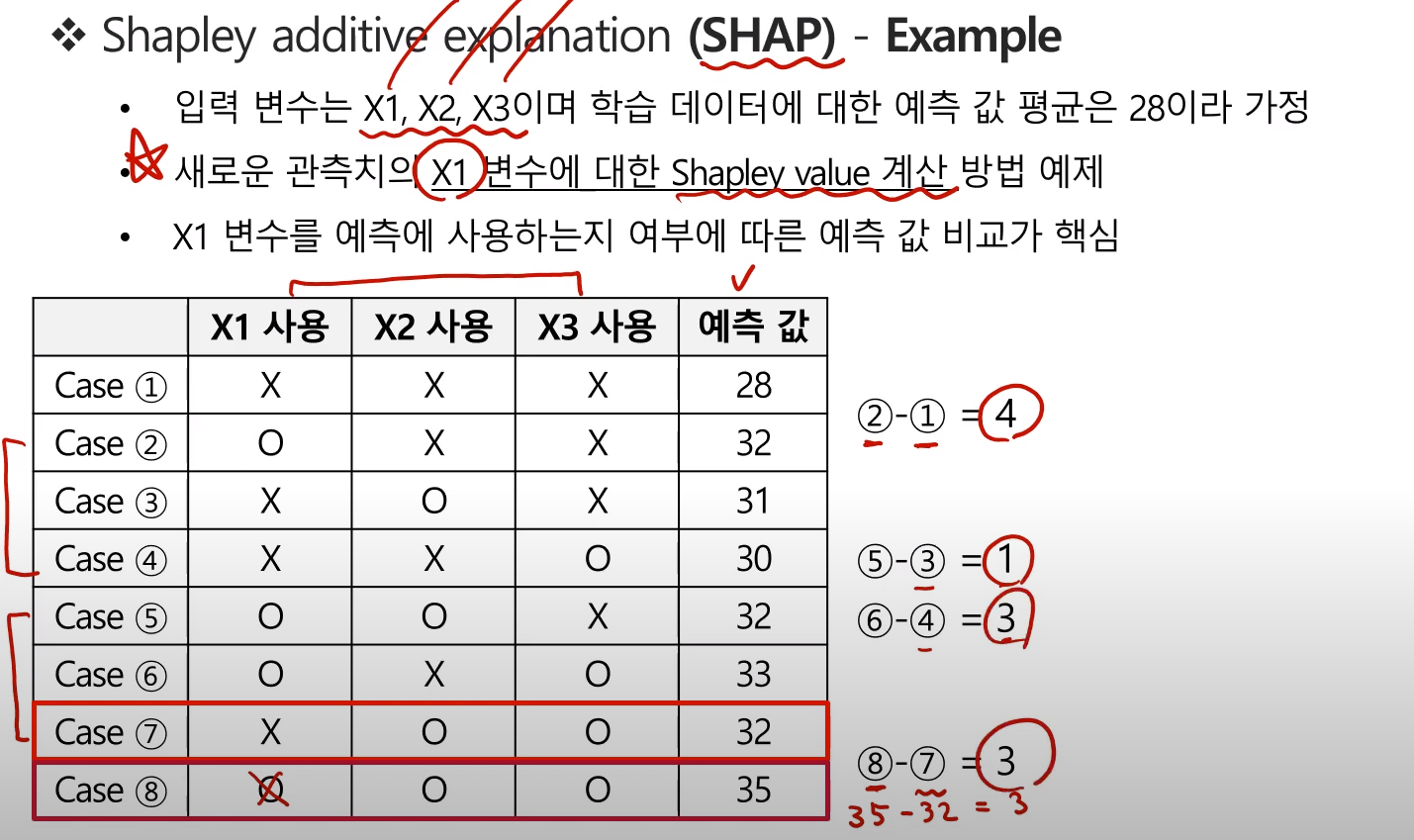
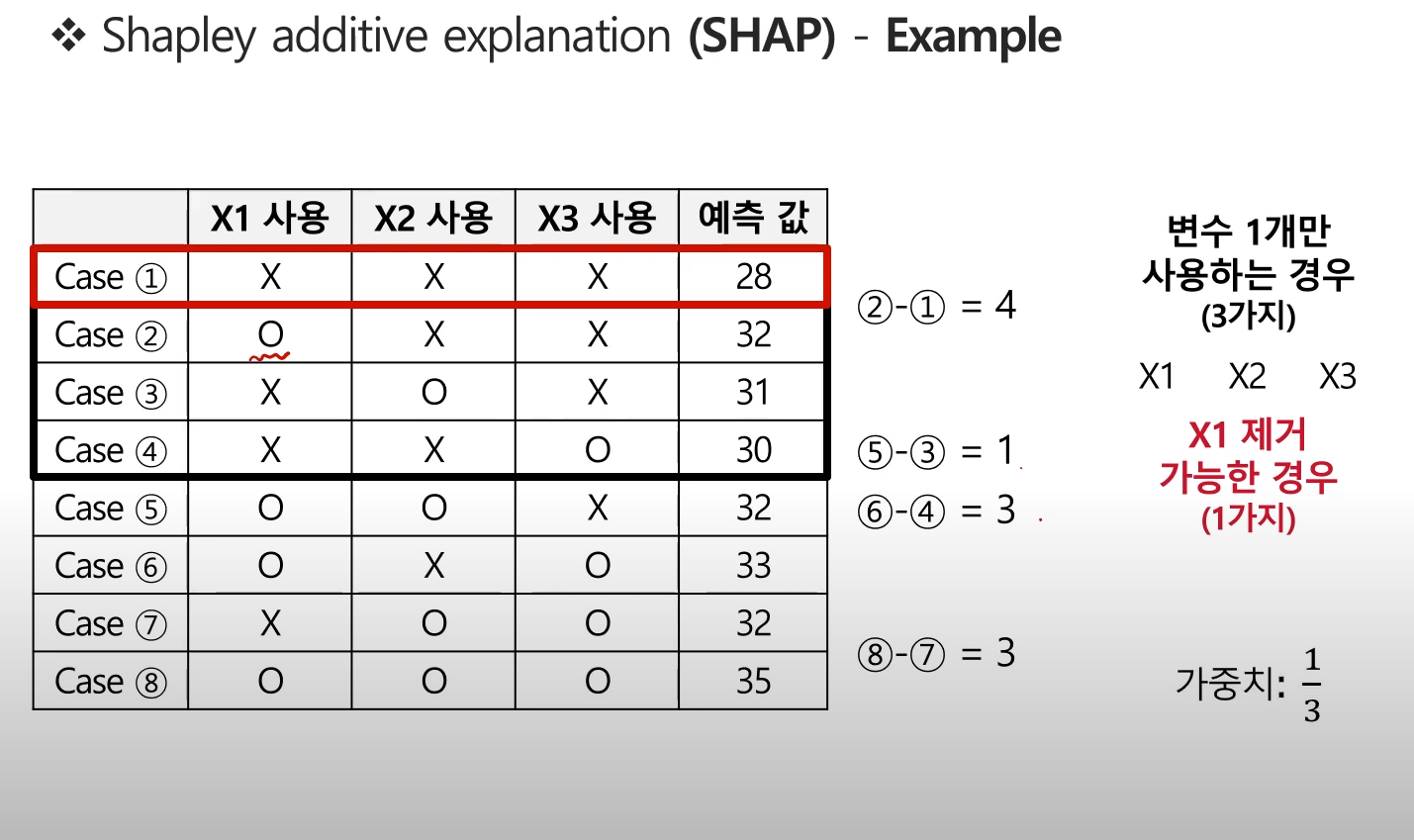
각 값은 X1변수의 포함 여부에 따른 Contribution이라 볼 수 있으나, 각각의 가중치 고려가 필요하다.
그렇기에, 아래와 같이 가중치를 계산해준다.
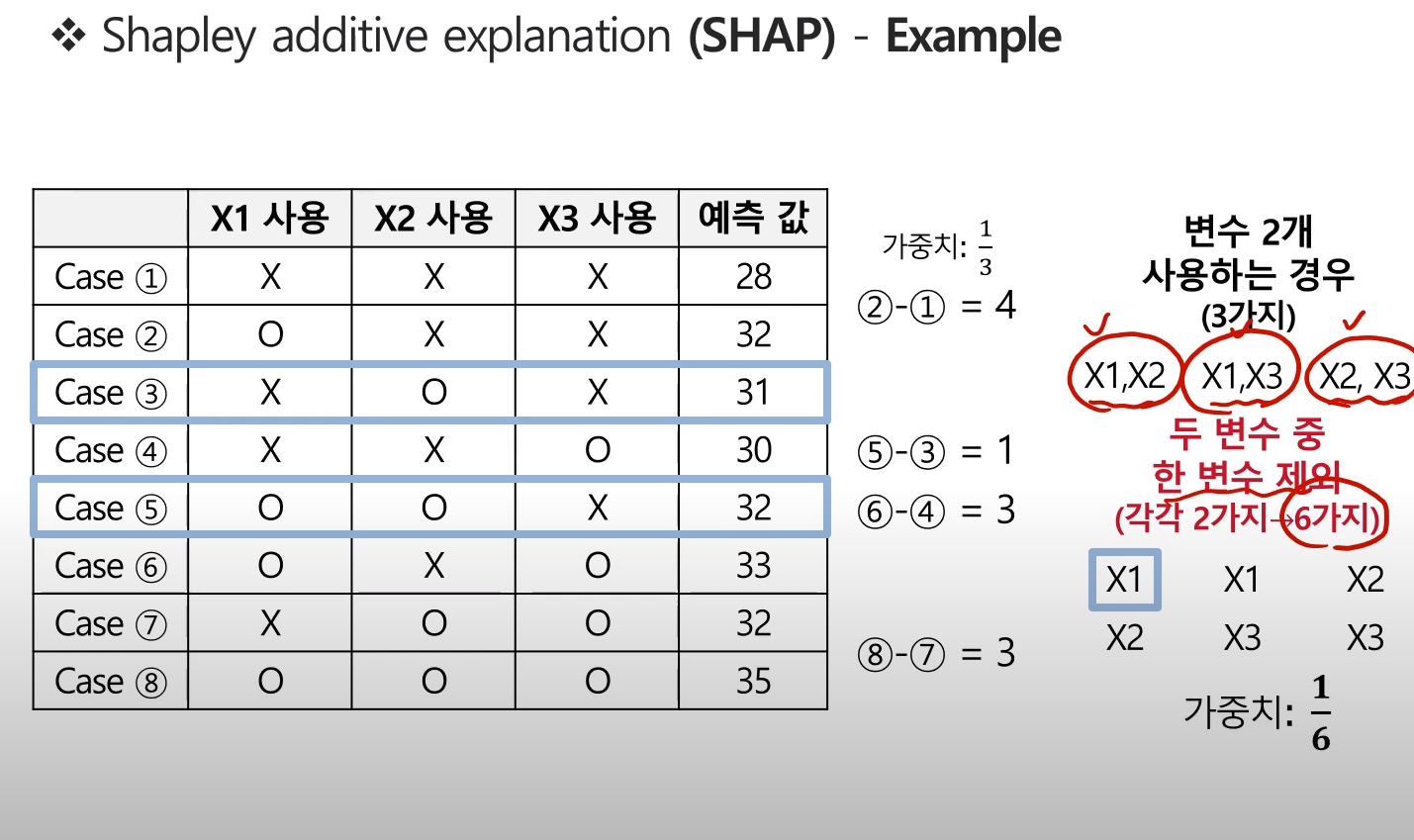
마찬가지로, 변수 2개를 사용하는 경우에 대한 가중치는 다음과 같이 계산된다.
- 현재는 X1변수에 대한 Shapley value계산에만 중점을 둠!
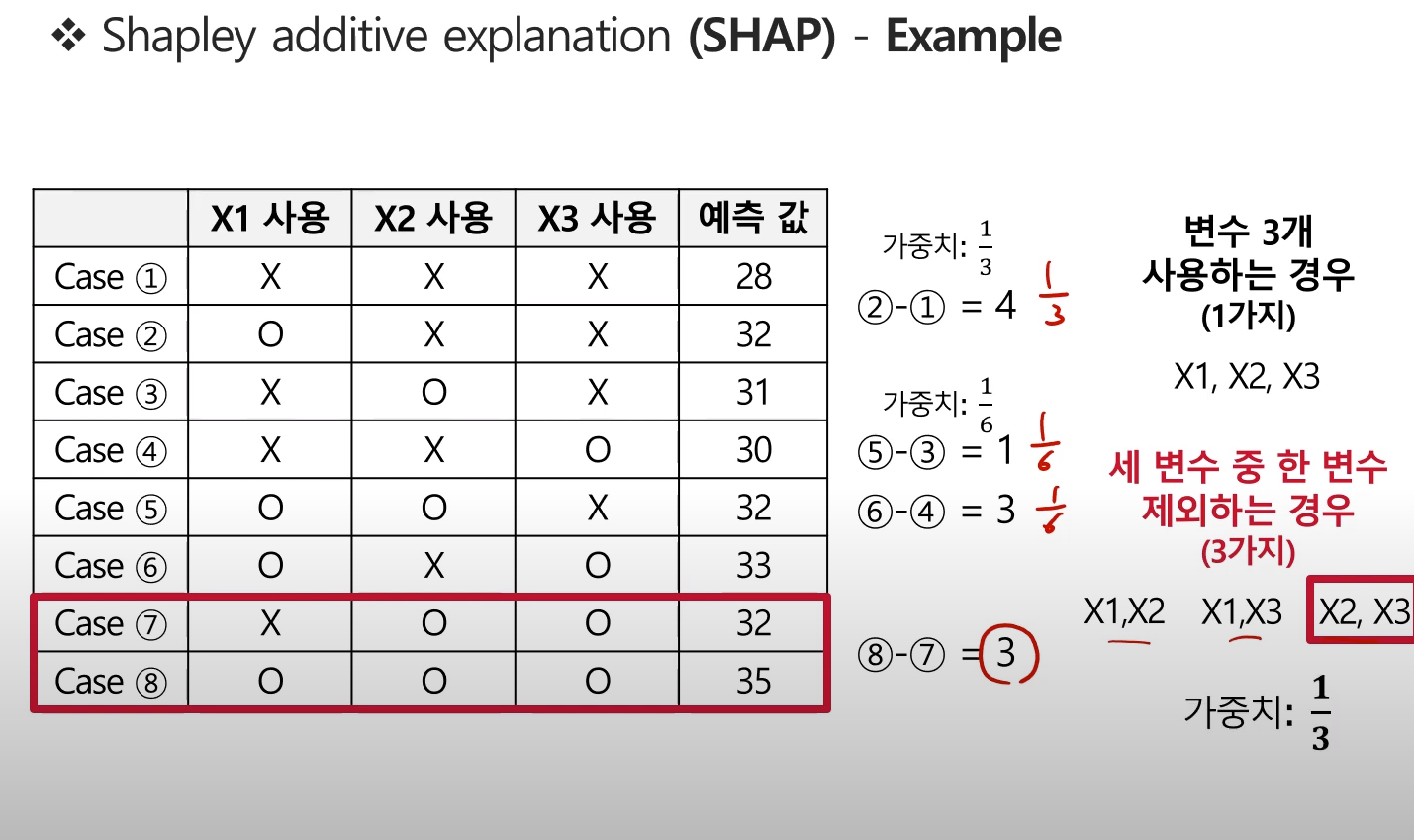
이렇게 최종적으로 계산된 X1변수에 대한 Shapley value는 다음과 같다.
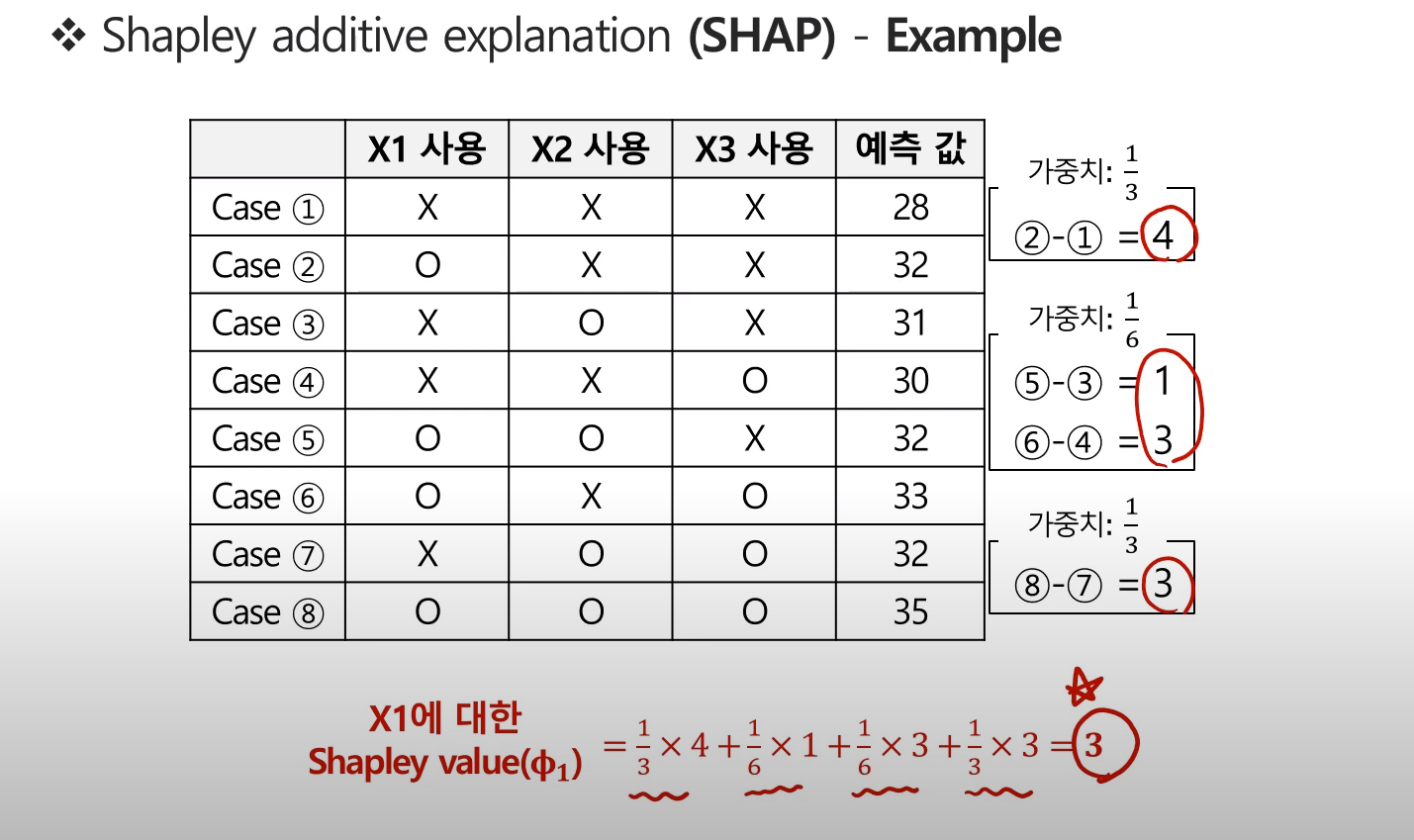
같은 원리로 입력변수별 Shapley value를 계산할 수 있다.

위 결과에 따르면, X1변수가 예측값에 가장 많은 기여를 했다고 볼 수 있다.
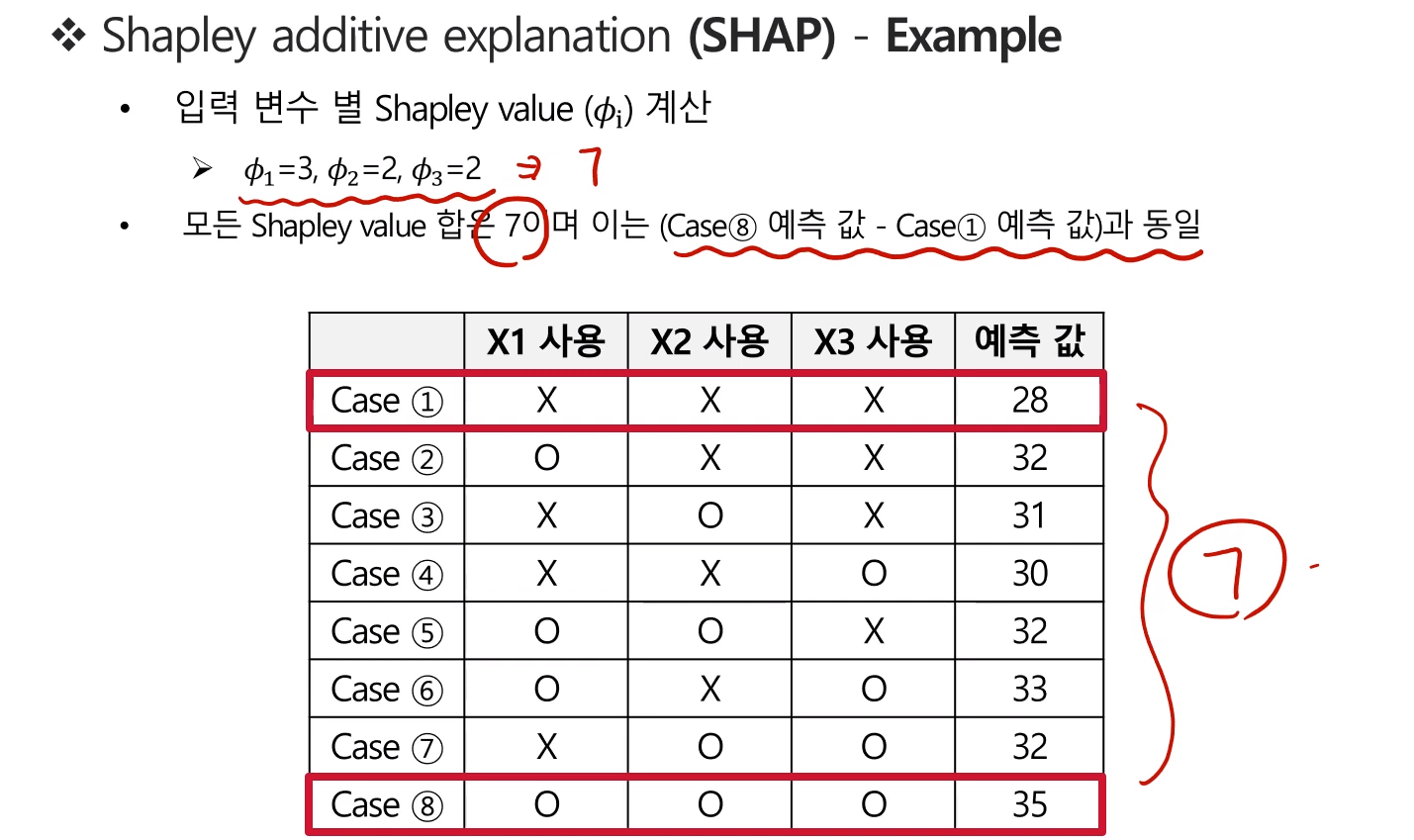
Shapley value 참고
모든 변수를 사용했을 때의 에측값 - 어떤 변수도 사용하지 않았을 때의 예측값을 구하면, (고려 대상)변수의 Shapley value총합을 구할 수 있다.
Shapley Value Formula
Shapley value의 계산 수식은 다음과 같다.
- 관심 관측치마다 다음 수식에 따른 계산이 필요하기에, 연산량이 많다.
- 수식의 앞부분은 가중치, 뒷부분은 각 변수별 기여도에 해당한다.

Shapley value 해석 예제
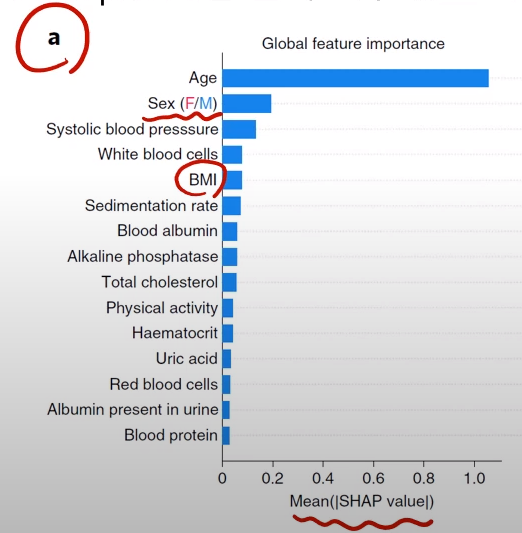
- 사망률에 어떤 변수가 많은 기여를 했는지 보는 예제
- Shapley value가 클 수록 사망률에 큰 기여를 했다는 것
아래 표의 경우,
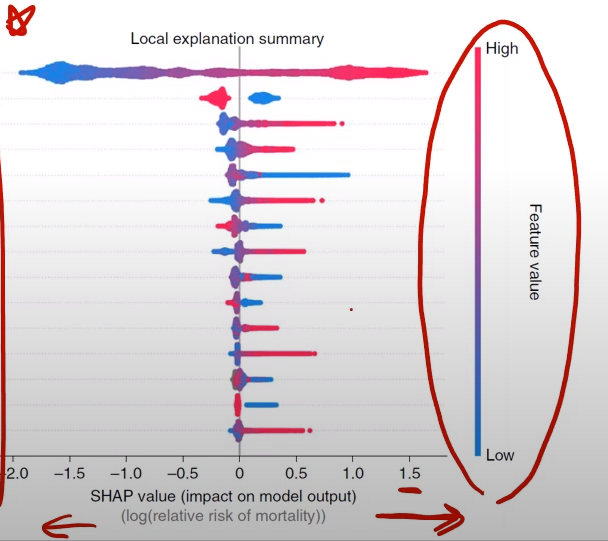
- 나이가 많을 수록 사망률에 큰 기여를 했다는 것
- Sex 변수의 경우, 범주형 변수이기에 위와 같이 나타난다. 남성의 사망률에 대한 기여도가 높으며,
- Systolic blood pressure가 높을 수록 사망률에 대한 기여도가 높고,
- BMI가 낮을 수록 사망률에 대한 기여도가 높고...
위와 같이 해석하면 된다.
Shapley Value를 통한 Feature importance 구하기
- 입력 변수별 양수 Shapley value값을 모두 더해 전체 변수 중요도로 환산할 수 있다.
- 나이가 사망률에 큰 기여를 하는 것을 알 수 있다.
- 이때, Uric acid, Blood protein 등의 변수는 변수 중요도는 낮지만, 사망률을 높이기에 주의해야한다는 것을 알 수 있다.
- 무작정 Feature importance만 보지 말자!
- 무작정 Feature importance만 보지 말자!
이미지 분류 모델에 대한 Shapley value 해석 예제
- 어떤 픽셀이 분류 결과에 영향을 많이 주었는가 확인 가능

Shapley Value 장단점
장점
- LIME과 달리 모든 학습데이터에 대한 예측값을 기준으로 시작한다.
- LIME은 모든 학습데이터가 아닌, 근방의 데이터(?)로만 예측값을 구함 (Local Model)
- 전체 데이터 중 관심 관측치의 위치를 파아갛고 해석하는 것으로 이해할 수 있다.
- 정형데이터의 경우, 관측치 별 해석과 전반적 변수 중요도를 산출해낼 수 있다.
- '모델에 관계없이' Shapley Value를 사용할 수 있다 (아래 단점과 연관)
- 모델에 관계없는 설명방법
- Model-Agnostic Explainable AI
- LIME 또한 사후분석방법론이기에, Model-Agnostic한 방법론이다.
- Deep Learning에서 쓰이는 Attention 기법은 Model-Agnostic하지 않다.
- 모델에 영향을 미치며 해당 중요도가 산출되기 때문
- Model-Dependent 해석 방법론
- Deep Learning에서 쓰이는 Attention 기법은 Model-Agnostic하지 않다.
단점
- 모든 순열에 대한 계산을 진행해야 하기에, 많은 시간이 필요하다.
- 수식 참고
- Shapley value는 모델 학습 후 산출하는 것이다.
- 예측값을 활용하기 때문!
- 즉, 원인/결과의 관계로 해석해내면 안된다.
- '에측에 중요하게 작용한 것'이지, '예측결과의 원인'은 아니다.
- 이를 다르게 보면, '모델에 관계없이' Shapley Value를 사용할 수 있다는 것
