
📖문제 184
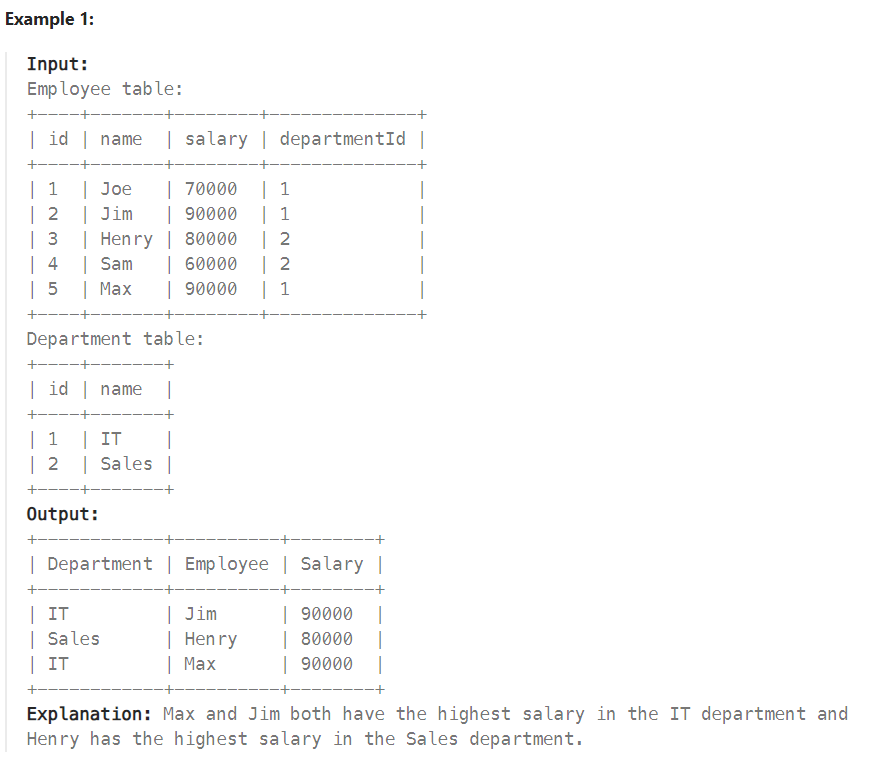
각 department 별 가장 높은 Salary 값을 갖는 이름을 구하는 문제입니다! Salary 값이 동일한 경우 모두 가져오며, output은 아래처럼 Department, Employee , Salary 컬럼의 형태로 나타내야합니다.
code
SELECT Department,Employee,Salary
FROM(SELECT D.name AS Department
, E.name AS Employee
, Salary
, DENSE_RANK() OVER(PARTITION BY departmentId ORDER BY salary desc) as RNK
FROM EMPLOYEE E
JOIN DEPARTMENT D ON E.departmentId = D.id) a
WHERE RNK = 1
ORDER BY Salary
위 문제의 핵심은 WINDOW 함수 입니다.
각 부서별로 가장 높은 급여를 갖는 employee 를 구해야 하는데! 중복 허용하여 가져와야 하기 때문에,DESN_RANK를 이용하여 순위를 매긴다음 가장 높은 순위(1)의 데이터만 가져오는 방법을 사용했습니다.
즉, '부서별' PARTITION BY departmendId 로 '급여'가 높은 ORDER BY salary 순으로 순위를 매기는데요! 공동 1등인 경우 모두 1등으로 중복하여 나타내주는 거죠! RNK 컬럼은 일종의 FILTER 역할을 합니다.
윈도우 함수를 이용하여 추가한
RNK컬럼을 보면 아래와 같은 결과가 나옵니다.
| Department | Employee | Salary | RNK |
|---|---|---|---|
| IT | Jim | 90000 | 1 |
| IT | Max | 90000 | 1 |
| IT | Joe | 70000 | 2 |
| Sales | Henry | 80000 | 1 |
| Sales | Sam | 60000 | 2 |
IT 부서에 JIM 과 MAX가 공동 1등이며, Sales 부서의 Henry 가 1등 이네요. 이제 RNK = 1 인 데이터만 가져와서 문제에서 요구하는 테이블 형태로 바꿔주면 끝입니다! WEHRE RNK = 1
📖문제 185
직전 184번 문제와 비슷한 문제입니다. 이번에는 top3 를 구해야합니다.
A company's executives are interested in seeing who earns the most money in each of the company's departments. A high earner in a department is an employee who has a salary in the top three unique salaries for that department. Write a solution to find the employees who are high earners in each of the departments.
code
top3 이므로 rnk 조건만 추가해주면 됩니다!
SELECT Department
, Employee
, Salary
FROM(SELECT E.name AS Employee
, Salary
, D.name AS Department
, DENSE_RANK() OVER(partition by departmentId order by salary desc) as rnk
FROM Employee E
INNER JOIN Department D on E.departmentId = D.id) A
WHERE rnk <= 3 ✔️ GROUP BY 와 PARTITION BY 차이
GROUP BY와PARTITION BY의 느낌이 비슷하지만 사용 차이는 분명합니다.
GROUP BY는 뭉탱이로 집계하는 느낌 PARTITION BY는 테이블 안을 조심히.. 세말하게(?) 집계하는 느낌 이라고 생각이 드는데요 ㅋㅋ
예를들어, GROUP BY의 경우 정말 한 테마, 주제를 묶어서 집계할 때 사용하기 때문에 테이블이 변형되는 일이 많습니다.
# 예를들어, 부서별 평균 급여를 구하고 싶을 때
SELECT Department
, MEAN(Salary)
FROM EMPLOYEE
GROUP BY Department| Department | avg(salary) |
|---|---|
| Sales | 70000 |
| IT | 83333 |
하지만, 윈도우 함수의 경우 기존의 테이블 안에서 행과 행 간을 비교, 연산이 필요할 때 사용합니다. 기존의 테이블을 유지하고 본인이 필요한 조건, 집계, 순서 등 함수를 이용해서 말이죠.
여기서 PARTITION BY 는 해당 윈도우 함수를 사용하는 컬럼의 기준이 되고
DESN_RANK 나 ROW_NUMBER 같이 등수를 매기고 싶을 때 필요한 ORDER BY는 나열의 기준이 됩니다.
, DENSE_RANK() OVER(PARTITION BY departmentId ORDER BY salary desc) AS RNK
, AVG(salary) OVER(PARTITION BY departmentId) AS SAL_AVG| Department | Employee | Salary | RNK | SAL_AVG |
|---|---|---|---|---|
| IT | Jim | 90000 | 1 | 83333 |
| IT | Max | 90000 | 1 | 83333 |
| IT | Joe | 70000 | 2 | 83333 |
| Sales | Henry | 80000 | 1 | 70000 |
| Sales | Sam | 60000 | 2 | 70000 |
RNK: 공동 등수를 포함한 부서별 급여 순위SAL_AVG: 각 부서별 평균 급여
위의
GROUP BY와 반대로 기존 TABLE를 유지한체 각 PARTITION BY 에 따라 집계, 등수에 관한 컬럼을 추가할 수 있는것이죠! 이 예시 외에도 다양한 윈도우 함수들이 많이 있기 때문에. 코딩테스트나 쿼리 연습을 하면서 나올때마다 정리해보려합니다!
