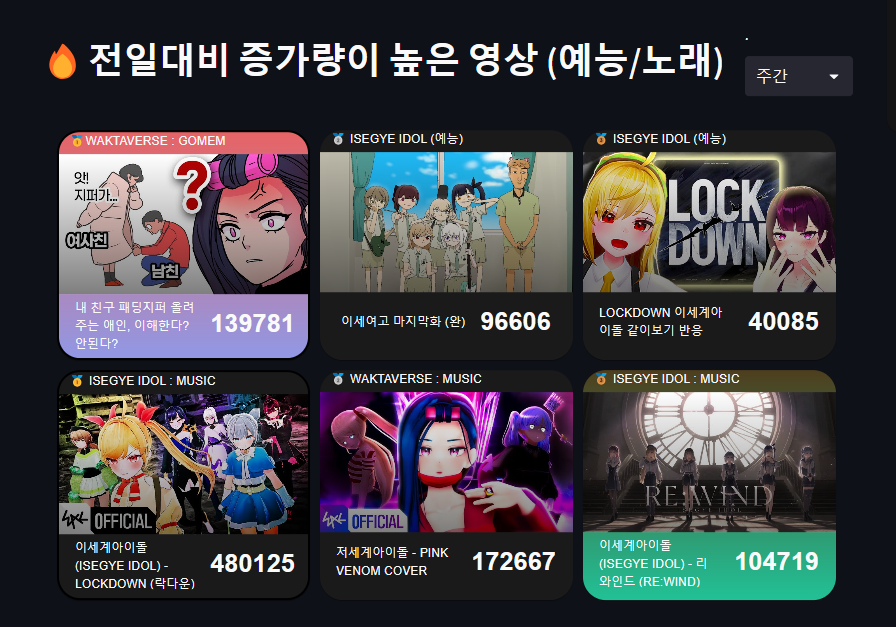
📊전일대비 증가량
채널의 전일대비 증가량이 높은 대표영상을 (일간/주간/월간) 별로 한눈에 모니터링 할 수 있도록 추가해봤습니다. (완성은 아니고 심심해서 css 도 좀 꾸며 봤습닏..)
전처리
왁타버스 채널의 영상 컨텐츠의 경우 보통 노래와 예능(편집영상) 으로 되어 있기 때문에, 크게 예능 부분 노래부분으로 데이터를 정리했습니다. csv 로 데이터를 불러오다보니 날짜형태의 데이터들을 strftime() 함수로 잘 맞춰주는게 중요했습니다.
일간
- playlist_title 이 'WAKTAVERSE : GOMEM ', 'ISEGYE IDOL (예능)' 인 경우, 예능(편집영상)에 해당합니다.
today_hot_enter- playlist_title 이 "WAKTAVERSE : MUSIC", 'ISEGYE IDOL : MUSIC' 인 경우, 노래 부분에 해당합니다.
today_hot_musicdrop_duplicates(subset='video_id')중복을 제거해줍니다. 한 영상에 2개이상의 재생목록에 들어간 경우가 일부 있습니다.nlargest.(3, 'view_count_diff')view_count_diff 가 높은 3개의 데이터를 가져옵니다.주간
- 현재 날짜를 기준으로 시작하는주 를 구하고, 주간별로 누적된 view_count_diff 가 계산된 weekly_df를 만듭니다.
- 똑같이 view_count_diff 가 높은 3개의 데이터를 가져옵니다.
(+ 2023-07-14 like_count_diff 도 추가 )
# 현재 날짜
now = datetime.datetime.now()
now_time_str = str(now.strftime('%Y-%m-%d'))
# 시작주
week = now - datetime.timedelta(days=now.weekday())
week_start = week.strftime('%m-%d')
# ------ 2023 현재 뜨고 있는 컨텐츠
#일간
today_hot = total_diff[total_diff['down_at'] == total_diff['down_at'].max()] # # now_time_str
today_hot_enter = today_hot[today_hot['playlist_title'].isin(['WAKTAVERSE : GOMEM ', 'ISEGYE IDOL (예능)'])].drop_duplicates(subset='video_id')
today_hot_music = today_hot[today_hot['playlist_title'].isin(["WAKTAVERSE : MUSIC", 'ISEGYE IDOL : MUSIC'])].drop_duplicates(subset='video_id')
top_3_videos = today_hot_enter[~(today_hot_enter['video_id'].isin(['JY-gJkMuJ94', 'fgSXAKsq-Vo']))].nlargest(3, 'view_count_diff')[['playlist_title','video_id', 'title','view_count_diff','like_count_diff']]
top_3_music = today_hot_music.nlargest(3, 'view_count_diff')[['playlist_title','video_id', 'title','view_count_diff','like_count_diff']]
# 주간
total_diff['down_at'] = pd.to_datetime(total_diff['down_at'], format='%Y-%m-%d')
total_diff['week_start'] = total_diff['down_at'] - pd.to_timedelta(total_diff['down_at'].dt.dayofweek, unit='d')
weekly_df = total_diff.groupby(['playlist_title','video_id','title','week_start'])[['view_count_diff', 'like_count_diff']].sum().reset_index()
weekly_df['week_start'] = pd.to_datetime(weekly_df['week_start']).dt.strftime('%m-%d')
weekly_hot = weekly_df[weekly_df['week_start'] == week_start] # 이번주를 보고싶다면
weekly_hot_enter = weekly_hot[weekly_hot['playlist_title'].isin(['WAKTAVERSE : GOMEM ', 'ISEGYE IDOL (예능)'])]
weekly_hot_music = weekly_hot[weekly_hot['playlist_title'].isin(["WAKTAVERSE : MUSIC", 'ISEGYE IDOL : MUSIC'])]
top_3_videos_week = weekly_hot_enter[~(weekly_hot_enter['video_id'].isin(['JY-gJkMuJ94', 'fgSXAKsq-Vo']))].nlargest(3, 'view_count_diff')[['playlist_title','video_id', 'title','view_count_diff','like_count_diff']]
top_3_music_week = weekly_hot_music.nlargest(3, 'view_count_diff')[['playlist_title','video_id', 'title','view_count_diff','like_count_diff']]
streamlit 시각화
일간, 주간별 먼저 만들어 봤습니다!
dataframe 형태로 가져오다 보니, iloc 를 이용해서 해당 값들을 가져왔습니다. 대략 아래와 같은 형식입니다. (ㅎㅎ css.. 어렵네요. 많이 부족합니다.) 저같이 프론트엔드쪽에 지식이 많이 없더라도, python 과 streamlit으로 layout이나, 디자인적 요소들을 비교적 쉽게 만들 수 있습니다.
# select option
with st.container():
col1_1,col2_1 = st.columns([6,1])
with col1_1:
st.markdown('''
## 🔥뜨는 컨텐츠 TOP3(예능/노래)
''')
with col2_1:
sort_option_count = st.selectbox('___', ['today',f'주간 ({week_start})','월간'], key='sort_option_hot')
if sort_option_count == '일간':
top3_data_enter = top_3_videos
top3_data_music = top_3_music
elif sort_option_count == '주간':
top3_data_enter = top_3_videos_week
top3_data_music = top_3_music_week
st.markdown(f'''
* ({sort_option_count} 기준) 조회수/좋아요 증가량 TOP3를 가져옵니다.
''')
with st.container():
with elements("hot_video"):
layout=[
dashboard.Item("item_1", 0, 2, 2, 1.5, isResizable=False ),
dashboard.Item("item_2", 2, 2, 2, 1.5, isResizable=False),
dashboard.Item("item_3", 4, 2, 2, 1.5, isResizable=False),
dashboard.Item("item_4", 0, 2, 2, 1.5, isResizable=False),
dashboard.Item("item_5", 2, 2, 2, 1.5, isResizable=False),
dashboard.Item("item_6", 4, 2, 2, 1.5, isResizable=False),
]
hot_video_card_sx = { # 타이틀 조회수증가량 css
"display": "flex",
.......
}
with dashboard.Grid(layout):
mui.Card(
mui.CardContent( # 재생목록/링크
sx={'display':'flex',
'padding': '2px 0 0 0'
},
children=[
mui.Typography(
f"🥇{top3_data_enter['playlist_title'].iloc[0]}",
component="div",
sx={"font-size":"12px",
"padding-left": 10,
"padding-right": 10}
),
mui.Link(
"🔗",
href=f"https://www.youtube.com/watch?v={top3_data_enter['video_id'].iloc[0]}",
target="_blank",
sx={"font-size": "12px",
"font-weight": "bold"}
)
]
),
mui.CardMedia( # 썸네일 이미지
sx={ "height": 140,
"backgroundImage": f"linear-gradient(rgba(0, 0, 0, 0), rgba(0,0,0,0.5)), url(https://i.ytimg.com/vi/{top3_data_enter['video_id'].iloc[0]}/sddefault.jpg)",
# "mt": 0.5
},
),
mui.CardContent( # 타이틀 조회수증가량
sx = hot_video_card_sx,
children=[
mui.Typography(
f"{top3_data_enter['title'].iloc[0]}",
component="div",
sx={"font-size":"12px",
"align-self": "center",
"max-height": "100%",
"overflow": "hidden"
}
),
mui.Box(
mui.Typography(
f"{int(top3_data_enter['view_count_diff'].iloc[0])}",
variant='body2',
sx={
"font-size" : "25px",
"fontWeight":"bold",
"text-align":"center",
"height":"30px"
},
),
mui.Typography(
f"❤️{int(top3_data_enter['like_count_diff'].iloc[0])} +",
variant='body2',
sx={
"font-size" : "14px",
"fontWeight":"bold",
"text-align":"center"
},
),
)
]
)
,key='item_1',sx={"borderRadius": '23px',
"background": "linear-gradient(#4b411fe0, #27b98e)"
if "WAKTA" in f"{top3_data_enter['playlist_title'].iloc[0]}" else "linear-gradient(#e66465, #9198e5)"})
........
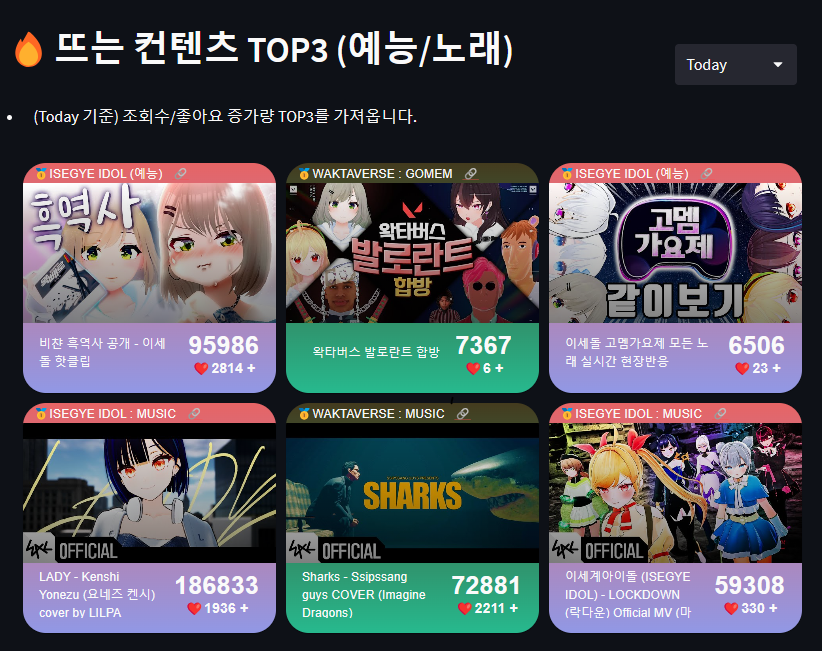
✔️일간 조회수 증가량 top3
(+ 수정 07-14)
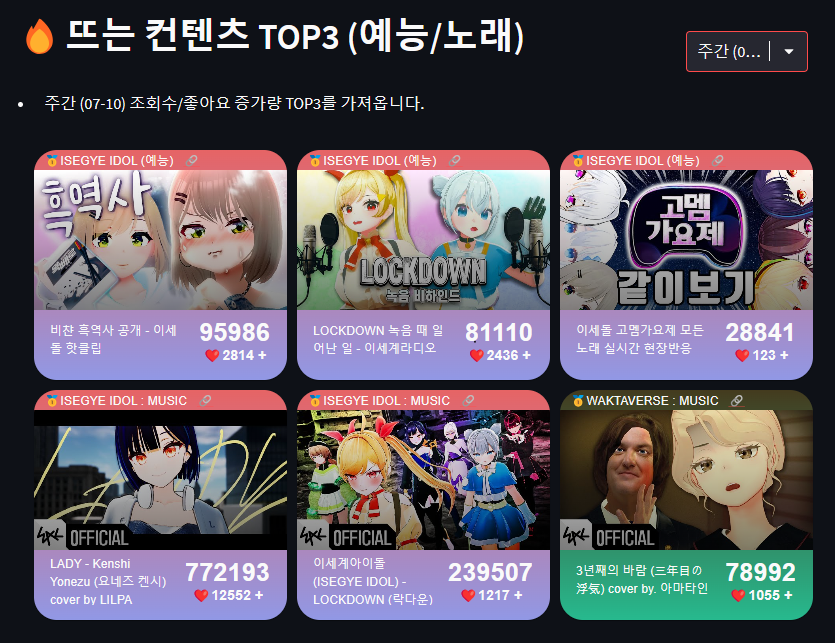
✔️주간 조회수 증가량 top3
next
민심체크 - (일간, 주간별 top3 영상) 시청자 반응 text 분석을 해보자 !!!

다양한 컨텐츠가 있는 곳을 좋아합니다. 시리즈를 참고하시면 편하게 글을 보실 수 있습니다🫠