1. 리스트
리스트는 순서가 있는 자료구조로 중복을 허용하는 자료구조입니다.
// 선언
List<Integer> arrayList = new ArrayList<>();
List<Integer> linkedList = new LinkedList<>();
//할당부의 new ArrayList<>()의 <>()는 각각 제너릭 옵션,초기화 옵션이다.
// 배열에서 초기화
Integer[] array = {1, 2, 3, 4, 5};
List<Integer> listFromArray = new ArrayList<>(Arrays.asList(array));
// 리스트의 제너릭 옵션으로 리스트를 받을 수 있다.
// 보통 정점-간선 느낌의 그래프를 선언할때 해당 방식 씀
private List<List<Integer>> adjList;
public Graph(int vertices) {
// 정점 수만큼 용량 지정
adjList = new ArrayList<>(vertices);
// 각 정점마다 빈 리스트 초기화
for (int i = 0; i < vertices; i++) {
adjList.add(new ArrayList<>());
}
}- arraylist : 배열 기반이므로 인덱스 접근이 빠름.
- linkedlist : 이중 연결 리스트 기반이므로 삽입,삭제가 빠름.
1-1) 메소드(CRUD)
// 추가
list.add(element); // 끝에 추가
list.add(index, element); // 특정 위치에 삽입
list.addAll(collection); // 다른 컬렉션 전체 추가
// addAll은 리스트에 리스트를 넣는다고 생각하면 됨
List<Integer> list1 = new ArrayList<>(Arrays.asList(1, 2, 3));
List<Integer> list2 = new ArrayList<>(Arrays.asList(4, 5, 6));
// - CASE 1
// list2의 모든 요소를 list1 끝에 추가
list1.addAll(list2);
System.out.println(list1); // [1, 2, 3, 4, 5, 6]
// - CASE 2
// 인덱스 1 위치에 list2 추가
list1.addAll(1,list2);
System.out.println(list1); // [1, 4, 5, 6, 2, 3]
// 조회
list.get(index); // 인덱스로 조회
list.size(); // 크기 반환
list.isEmpty(); // 비어있는지 확인
// 삭제
list.remove(index); // 인덱스로 삭제
list.remove(element); // 객체로 삭제
list.clear(); // 전체 삭제1-2) 메소드(검색 및 확인)
list.contains(element); // 요소 포함 여부(boolean)
list.indexOf(element); // 중복일 경우 처음에 나타나는 요소의 인덱스 번호
list.lastIndexOf(element); // 마지막 인덱스1-3) 메소드(정렬)
Collections.sort(list)
Collections.reverse(list)2. 스택
스택은 위에 작성한 자바의 Arraylist와 linkedlist로 구현이 가능합니다.
3. 큐
큐는 Arraylist보단 Linkedlist로 구현하는것이 더 효율적입니다
- Arraylist로 구현 시
poll()연산에서 시간복잡도가 O(n)
3-1) 큐 연산
queue.offer(1) // 큐 뒤쪽에 연산 추가
queue.poll() // 큐 앞쪽 요소 제거하고 *반환*
queue.peek() // 큐 앞쪽 요소 조회 (제거 안함)
queue.isEmpty() // 큐가 비어있는지 확인3-2) 큐 & BFS
public void bfs(int[][] graph, int start) {
Queue<Integer> queue = new LinkedList<>();
boolean[] visited = new boolean[graph.length];
queue.offer(start);
visited[start] = true;
while (!queue.isEmpty()) {
int current = queue.poll();
System.out.print(current + " ");
// 인접한 모든 노드를 큐에 추가
for (int i = 0; i < graph[current].length; i++) {
if (graph[current][i] == 1 && !visited[i]) {
queue.offer(i);
visited[i] = true;
}
}
}
}큐는 추후에 정리할 너비 우선 탐색기법인 BFS에서 주로 사용합니다.
3-3) 큐의 구현체
// 1. LinkedList
Queue<Integer> queue = new LinkedList<>();
// 장점: offer/poll 모두 O(1)
// 단점: 메모리 오버헤드
// 2. ArrayDeque
Queue<Integer> queue = new ArrayDeque<>();
// 장점: 메모리 효율적, 빠른 성능
// 단점: 없음 (대부분의 경우 최선)
// 웬만하면 이거 사용
// * Arraylist로는 큐 구현하지 말기4. 우선순위 큐(PriorityQueue)
우선순위 큐는 큐 내에서 우선순위가 높은 요소가 먼저 나오는 자료구조입니다.
최소 힙으로 구현되어 있으며, 숫자가 작을수록 높은 우선순위입니다.
- 힙 구조라 큐 자체는 정렬된 순서가 아님
4-1) 우선순위 큐 구현
// 1. 기본
PriorityQueue<Integer> minHeap = new PriorityQueue<>();
// 2. 역순으로 구현
PriorityQueue<Integer> maxHeap = new PriorityQueue<>(Collections.reverseOrder());
// 3. 커스텀 정렬
// 절댓값 기준 정렬
PriorityQueue<Integer> absHeap = new PriorityQueue<>((a, b) -> {
if (Math.abs(a) == Math.abs(b)) {
return a - b; // 절댓값 같으면 더 작은 수 우선
}
return Math.abs(a) - Math.abs(b);
});etc) 큐,리스트의 용량 및 성능
큐나 Array리스트 선언 시 초기 용량을 설정해주는 편이 더 성능이 좋아지는 특징이 있습니다.
자료구조의 용량이 예상 가능하면 선언시 용량을 설정해주는 편이 좋습니다.
// 문제의 범위가 1~10000이면
List<Integer> result = new ArrayList<>(10000);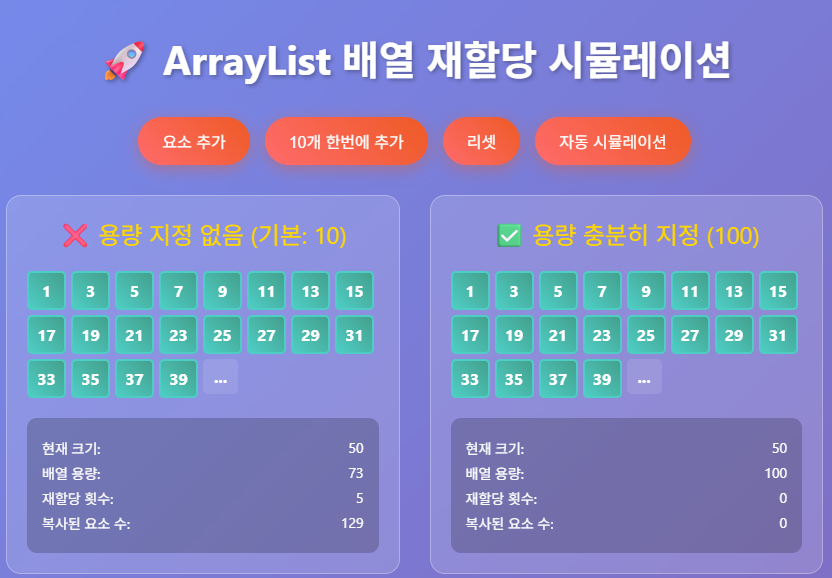
- 용량 지정이 없을경우 요소가 추가될때마다 재할당 및 요소 복사됨
- 용량 지정해줄 경우 추가만 됨


프론트엔드 개발자 지망생입니다