인프런 김영한님의 스프링 데이터 JPA 강의를 듣고 정리한 글입니다.
스프링 데이터 공통 인터페이스 구성
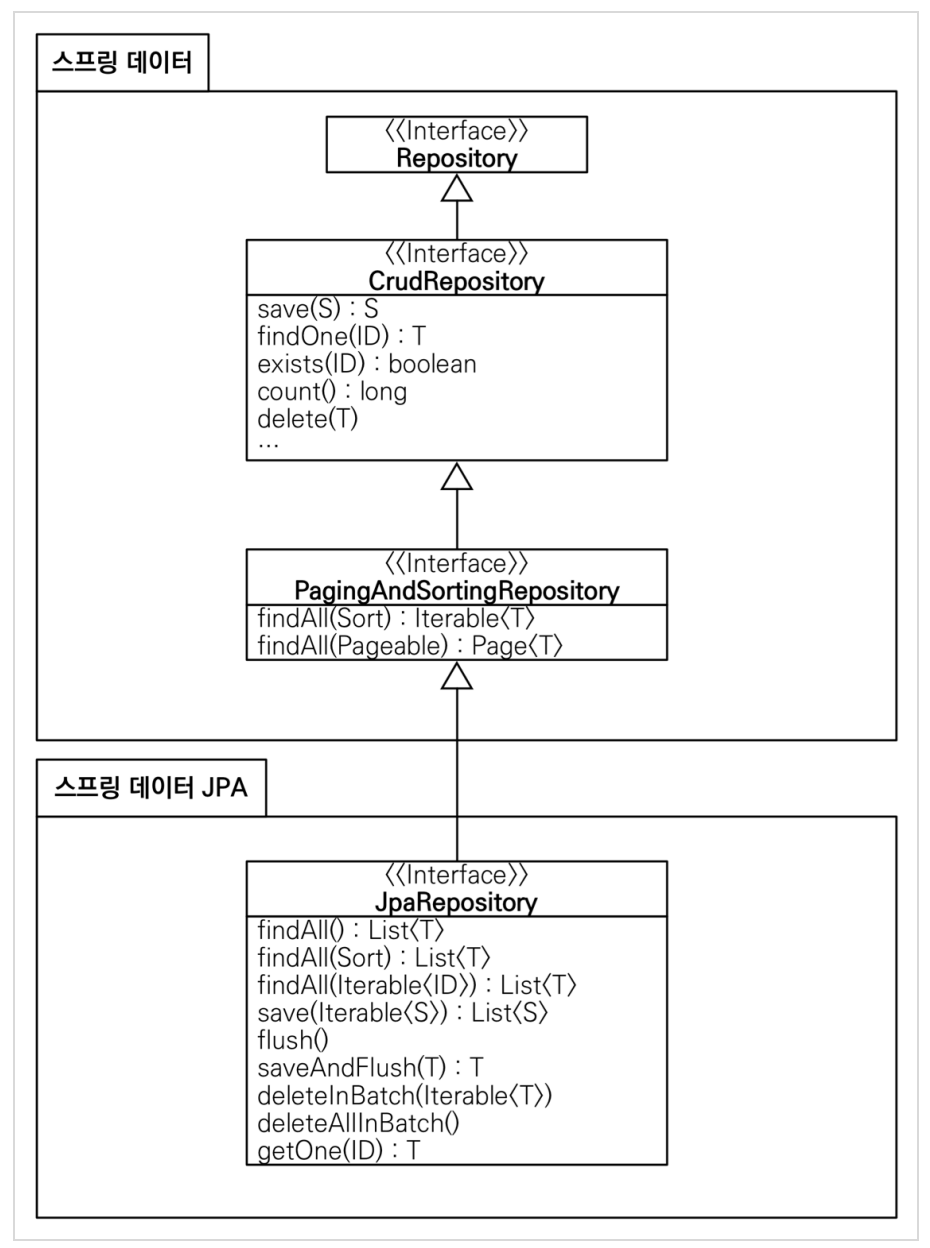
- CrudRepository : 기본적인 CRUD 기능을 제공
- PagingAndSortingRepository : 페이징 및 정렬 기능 제공
- JpaRepository : 스프링 데이터 jpa 사용 시 주로 쓰는 인터페이스로 CrudRepository, PagingAndSortingRepository의 기능을 제공하고 추가적인 기능 또한 제공
주요 메서드
-
save(S) : 새로운 엔티티는 persist 이미 이미 존재하는 엔티티는 merge한다.
- save()의 유의 사항은 뒤에서 정리한다.
-
delete(T) : 엔티티 삭제, EntityManger.remove() 호출
-
findById(ID) : 엔티티를 pk 값을 통해 조회, EntityManger.find() 호출
-
getOne(ID) : 엔티티를 프록시로 조회, EntityManger.getReference() 호출
-
findAll(...) : 모든 엔티티를 조회, Sort, Pageable 조건을 파라미터로 넘길 수 있다.
findOne과 getOne()의 차이
findOne : 데이터베이스에 접근하여 해당 엔티티를 return, 없을 경우 null return
getOne : Lazy Loading을 사용하기 위해 참조값만 return, 없을 경우 EntityNotFoundException 발생
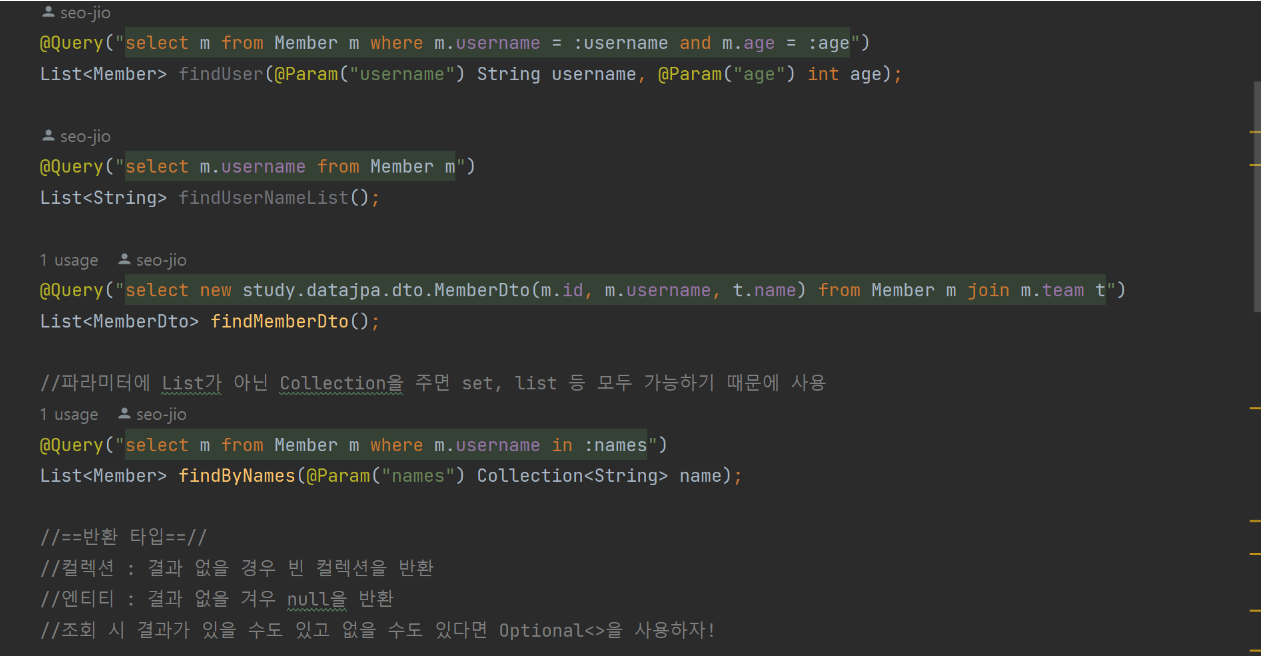
쿼리 메소드
메소드 이름으로 쿼리 생성
- 스프링 데이터 jpa가 메소드 이름을 보고 자동으로 쿼리를 생성하는데 이때 규칙이 존재
- 조회 : find...By, read...By
- COUNT : count...By, 반환 타입 long
- EXISTS : exists...By, 반환 타입 boolean
- 삭제 : delete...By, remove...By, 반환타입 long(삭제한 엔티티의 pk값)
- DISTINCT : find...DistinctBy, 중복 제거
- LIMIT : findFisrt3, findTop3
사용 예시
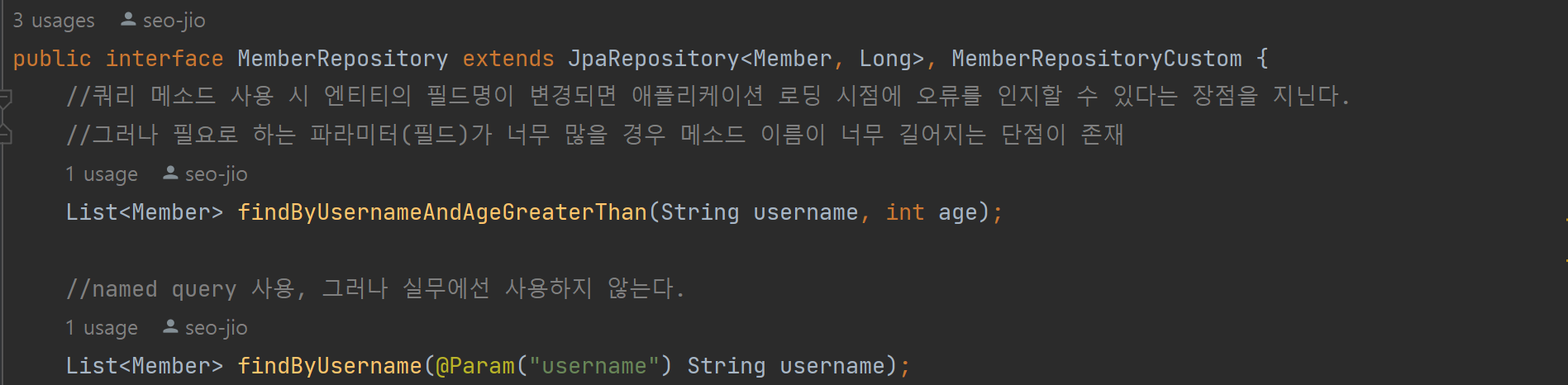
- 쿼리 메소드 사용 시 엔티티의 필드명이 변경되면 애플리케이션 로딩 시점에 오류를 인지할 수 있다는 장점을 지닌다.
- 그러나 필요로 하는 파라미터(필드)가 너무 많을 경우 메소드 이름이 너무 길어지는 단점이 존재
Spring Data Jpa 사용 시 Named Query를 직접 등록해서 사용하는 일은 드물고 대신 @Query를 사용해서 레포지토리 메소드에 쿼리를 직접 정의한다.(밑에 설명)
@Query, 레포지토리 메소드에 쿼리 정의하기
- Spring Data Jpa 사용시 자주 사용되는 방법
- @Query 어노테이션을 사용하여 실행할 메서드에 정적 쿼리를 직접 작성
- 어플리케이션 실행 시점에 문법 오류를 발견할 수 있다.
- 메소드 이름으로 쿼리 생성 시 발생하는 메소드명이 길어지는 단점을 해결해준다.
사용예시
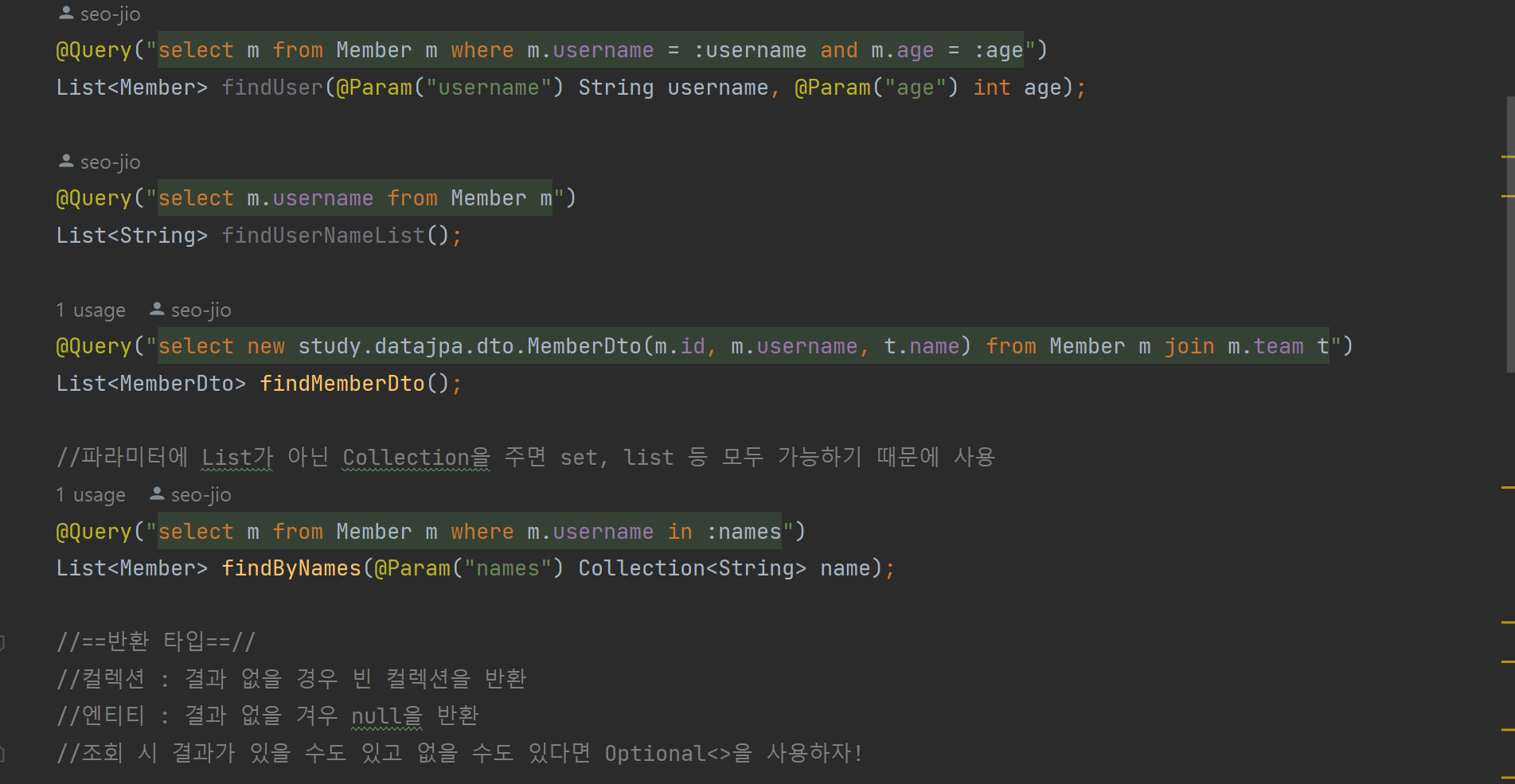
-
Jpa의 new 명령어를 사용하여 DTO로 직접 조회 할 수 있다.
-
jpql의 파라미터 바인딩과 동일하게 ":names" 형식으로 파라미터를 넘길 수 있다.
-
반환 타입
- 컬렉션 : 결과 없을 경우 빈 컬렉션을 반환
- 엔티티 : 결과 없을 경우 null을 반환
- Optional<> : 자바8의 기능으로 값이 null일 수도 있을 경우 Optional로 감싸서 사용

백엔드 개발자를 꿈꾸는 학생입니다!