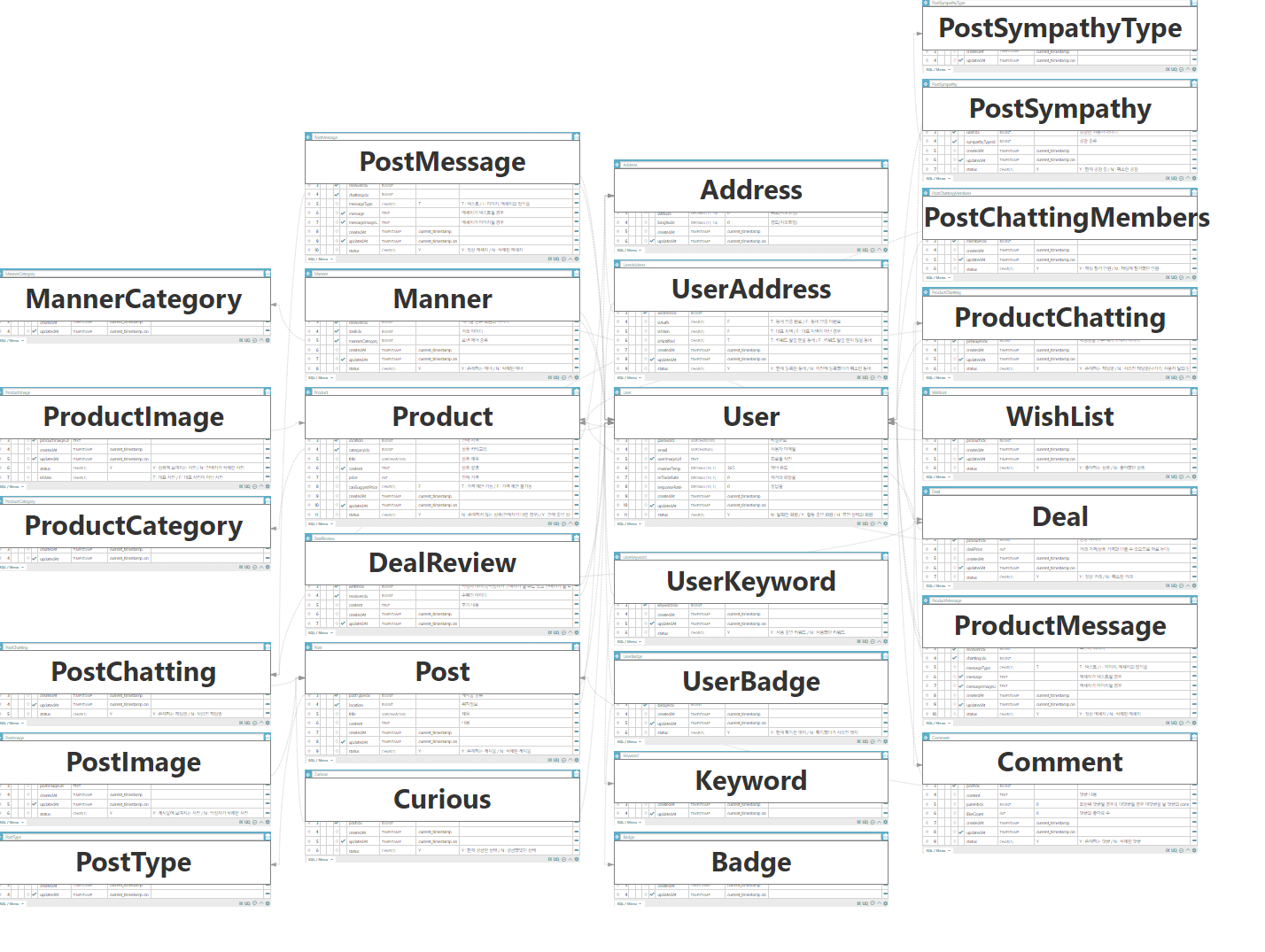
1. Aquery를 사용한 DB 설계⚒️
💡 테이블 주석에 다른 테이블과의 무슨 관계(1:N, 1:1, N:N)로 연관 되는지 설명을 달아 놓았다.
- Aquery 주소
- Aquery Tips
- 마우스 오른쪽 클릭 후 테이블 재배치를 누르면 자동으로 예쁘게 테이블들을 배치해준다.
- 테이블 주석을 활용하자
- 테이블 생성 쿼리 추출 가능
- 테스트 케이스 자동 추가 가능
2. Study 내용📚
1. 사용자 정보 관리
isDeleted혹은status를 두어 사용자가 탈퇴했는지 혹은 휴먼 계정인지 등 사용자 계정에 대한 정보를 나타낸다.
2. 생성 일자, 수정 일자 관리
- 실제로 사용자가 탈퇴했다고 해서 데이터를 삭제하지 않는다.(because 데이터 == 돈)
- 데이터베이스에서 시간과 관련된 데이터를 관리할 때 사용하는 TIMESTAMP 타입을 사용한다.
- createdAt : default를
CURRENT_TIMESTAMP로 두어 생성 일자를 관리한다.- DB가 자동으로 관리
- updatedAt : defualt를
CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP쿼리로 두어 최근 정보 수정 일을 관리한다.- DB가 자동으로 관리
3. CHAR vs VARCHAR vs TEXT
- CHAR와 VARCHAR 모두 DB에서 문자열을 표현할 때 사용하는 자료형으로 사용할 때 길이(byte)를 명시해줘야 한다. ex) VARCHAR(45) → ‘45자 까지 가능하다’
- CHAR, VARCHAR 모두 미리 설정한 최대 길이를 넘는 데이터가 들어올 경우 최대 길이 이상의 정보는 유실된다.
- CHAR : 고정형 문자열이기 때문에 CHAR(10)을 예로 들면 저장한 데이터의 크기가 2byte여도 기존에 설정한 10바이트 만큼의 공간을 사용한다.
- 모든 데이터의 크기가 고정되어 데이터의 크기를 찾는데 별다른 연산을 필요로 하지 않아 VARHCAR 보다 검색 속도가 빠르다.
- VARCHAR : 가변형 문자열이기 때문에 실제 저장된 데이터의 크기 만큼의 공간을 사용한다.
- 데이터의 크기가 데이터마다 모두 다르므로 데이터의 크기를 찾는 별도의 연산이 필요해 CHAR 보다 검색 속도가 느리다.
- TEXT : CHAR, VARCHAR와 달리 데이터의 최대 길이를 지정하지 않기 때문에 들어올 데이터의 최대 길이를 모르는 경우에 사용한다.
- VARCHAR 보다 검색 속도가 느려 셋 중에 젤 느리다.
CHAR : 다음 데이터의 위치는 ‘현재 가리키는 데이터가 저장된 메모리 주소 + 미리 설정한 크기’에 존재하게 된다.
VARCHAR : 다음 데이터의 위치가 ‘현재 가리키는 데이터가 저장된 메모리 주소 + 데이터의 실제 크기’ 이기 때문에 데이터의 크기를 찾는 별도의 연산이 필요.
4. SubQuery & Join
- SubQuery : 여러 테이블을 고려해야 하는 sql문을 짤 때 각 테이블 마다 쿼리를 날려 쿼리 문 안에 쿼리 문을 넣는 경우를 의미. 쿼리가 여러 번 나가기 때문에 검색 속도가 느리다.
select *
from Room
where no in (select roomNo from Member where userId = 'seojio');- Join : 여러 테이블을 fk, pk를 기준으로 합쳐 여러 테이블을 고려해야 하는 sql문을 짤 때 단 한번의 쿼리로 수행한다.
select roomNo, title, imageUrl, Room.createdAt
from Member
inner join Room on Room.no = Member.RoomNo //fk, pk간 고려
where userId = 'seojio'5. Group By & Having & Order By
- GROUP BY : 특정 컬럼에 데이터를 그룹화 할 때 사용
- 그룹 내 데이터 갯수(row)를 알기 위해 밑에 와 같이 사용
select p.location, count(p.productIdx) as cnt from Prodcut p group by p.location- 상품의 위치가 같은 것들 끼리 그룹화 후 그룹에 해당하는 데이터의 개수를 cnt에 저장
- HAVING : 그룹화 한 결과에 조건을 걸 때는 사용
- WHERE문과 유사하지만 WHERE문은 그룹화 하기 전의 모습에 조건을 걸 때 사용한다.
- ORDER BY : 특정 테이블을 정렬 할 때 사용
- DESC : 내림차순
- ASC : 오름차순
💡 SQL 작성 시 WHERE → GRUOP BY → HAVING → ORDER BY 순서로 작성
6. Left Join(== Left Outer Join)
- ProductImage, ProductChatting, WishList와 Product 테이블을 join 할 때 inner join을 하게 되면 상품의 이미지가 없거나, 열린 채팅방이 없거나, 좋아하는 사람이 없는 상품은 전체 상품을 나열할 때 나오지 않게 되므로 Left Join을 통해 위 세가지 경우에 해당하더라도 상품을 보여줄 수 있도록 한다.
7. Case When & TimeStampDiff
- 파이썬의 if, elif, else 문과 유사하다.
- case when~then, when~then, else 순으로 이루어져 있다.
select lastChatMessage,
case when TIMESTAMPDIFF(HOUR, lastChatMessageTimeStamp, current_timestamp()) < 24
then DATE_FORMAT(lastChatMessageTimeStamp, '%p %l:&i')
else DATE_FORMAT(lastChatMessageTimeStamp, '%c월 %e일')- 현재 시간과 가장 최근에 온 메세지가 생성된 시간이 24시간 이내라면 메세지가 생성된 시간을 보여주고 24시간을 넘겼다면 메세지가 온 날짜를 보여준다.
8. Count & ifNull
- count : 테이블에 존재하는 데이터의 개수를 알고 싶을 때 사용
- 컬럼 내 row의 개수를 조회할 때 값이 null 이라면 개수에서 제외 시킨다!
select count(*) from Product p; //테이블 내 전체 행 개수
select count(p.content) from Product p; //컬럼 내 행의 개수, content가 null이라면 count에서 제외- if null : 값이 null 일 경우 데이터를 지정할 수 있다.
select ifnull(p.content, 0) from Prodcut p //p.content가 null 일 경우 0으로 표시9. concat
- 여러 문자열 혹은 컬럼 값을 합쳐서 저장하거나 읽어올 경우 사용
select concat('안녕하세요', '저는', '서지오', '입니다') as profile;10. ‘=’ 와 ‘:=’의 차이
- ‘=’ : 같은 지를 비교(파이썬의 ‘==’과 동일)
- ‘:=’ : 대입 연산자(파이썬의 ‘=’과 동일) ****
11. 부동 소수점 타입(double, float) vs 고정 소수점 타입(Decimal)
- 부동 소수점 : 가수부와 지수부로 표시한 실수 표현으로 범위를 넘어가면 근사 값을 저장한다.
- double
- float
- 고정 소수점 : 정수부와 소수부로 표시한 실수 표현
- decimal
💡 돈을 계산할 때와 같이 정확한 값을 다루고자 한다면 고정 소수점(decimal)을 사용하자!
12. 지오 코딩(Geocoding)
- Geocoding : 도로명 주소를 통해 위도와 경도를 알아 내는 것
- 주로 네이버 api, 구글 api를 사용한다.
13. 예약어는 테이블 이름으로 설정하지 말자!!(ex. ‘like’)
- 사용할 경우 테이블 생성 시 오류가 뜬다…
참고 자료
https://luminitworld.tistory.com/94?category=975147
https://coding-factory.tistory.com/221
https://cloer.tistory.com/14?category=889693
CHAR & VARCHAR의 차이 : https://hack-cracker.tistory.com/165
VARCHAR & TEXT의 차이 : https://intrepidgeeks.com/tutorial/mysql-char-varchar-text-differences
GROUP BY : https://extbrain.tistory.com/56

백엔드 개발자를 꿈꾸는 학생입니다!