
1. ElasticSearch 란 ?
💬
- Elasticsearch는 텍스트, 숫자, 위치 기반 정보, 정형 및
비정형 데이터 등 모든 유형의 데이터를 위한 무료 검색 및 분석 엔진 - Apache Lucene을 기반으로 구축되었으며, Elasticsearch N.V.(현재 명칭 Elastic)가 2010년에 최초로 출시
2. 사용하는 이유
❓
-
빠른 환경 구성 속도
- Elasticsearch는 Lucene을 기반으로 구축되기 때문에, 풀텍스트 검색에 뛰어나다.
- Elasticsearch는 또한 거의
실시간 검색 플랫폼입니다. 이것은 문서가 색인될 때부터 검색 가능해질 때까지의대기 시간이 아주 짧다. 이 대기 시간은 보통1초 - 결과적으로, Elasticsearch는
보안 분석,인프라 모니터링같은 시간이 중요한 사용 사례에 이상적
-
분산적
- Elasticsearch에 저장된 문서는
샤드라고 하는 여러 다른 컨테이너에 걸쳐 분산 - 샤드는 복제되어
하드웨어 장애 시에 중복되는 데이터 사본을 제공 - Elasticsearch의 분산적인 특징은 수백 개(심지어 수천 개)의 서버까지 확장하고
페타바이트의 데이터를 처리할 수 있게 해준다.
- Elasticsearch에 저장된 문서는
-
광범위한 기능 세트와 함께 제공
- 속도, 확장성, 복원력뿐 아니라, Elasticsearch에는
데이터 롤업,인덱스 수명 주기 관리등과 같이 데이터를 훨씬 더 효율적으로 저장하고 검색할 수 있게 해주는 강력한 기본 기능이 다수 탑재
- 속도, 확장성, 복원력뿐 아니라, Elasticsearch에는
-
데이터 수집, 시각화, 보고를 간소화
- Beats와 Logstash의 통합은 Elasticsearch로 색인하기 전에 데이터를 훨씬 더 쉽게 처리할 수 있게 해줍니다.
Kibana는 Elasticsearch데이터의 실시간 시각화를 제공하며, UI를 통해 애플리케이션 성능 모니터링(APM), 로그, 인프라 메트릭 데이터에 신속하게 접근 가능
- Beats와 Logstash의 통합은 Elasticsearch로 색인하기 전에 데이터를 훨씬 더 쉽게 처리할 수 있게 해줍니다.
3. 어디에 사용 ?
❓
- 애플리케이션 검색
- 웹사이트 검색
- 엔터프라이즈 검색
로깅과 로그 분석- 인프라 메트릭과 컨테이너 모니터링
- 애플리케이션 성능 모니터링
- 위치 기반 정보 데이터 분석 및 시각화
- 보안 분석
- 비즈니스 분석
4. ES 특징
💡
- 실시간 분석 시스템
- ES가 실행되고 있는 동안 계속해서 데이터가 입력되고
동시에 실시간에 가까운 속도로 검색 및 집계 수행 가능
- ES가 실행되고 있는 동안 계속해서 데이터가 입력되고
- 전문 검색 엔진
내용 전체를색인해서특정 단어가 포함된 문서를 검색- 내부적으로는 역파일 색인 구조로 데이터를 저장, 사용자에게는 JSON형식으로 데이터를 전달
- 역 인덱스(Inverted Index)
키워드를 통해 문서를 찾아내는 방법
- 역 인덱스(Inverted Index)
- Scale out
- 샤드를 통해
규모가수평적으로늘어날 수 있음
- 샤드를 통해
- 고가용성
Replica를 통해 데이터의안정성을 보장
- Schema Free
- Json 문서를 통해 데이터 검색을 수행하므로 스키마 개념이 없음
- Restful
- 데이터 CURD 작업은 HTTP
Restful API를 통해 수행Data CRUD Elasticsearch Restful SELECT GET INSERT PUT UPDATE POST DELETE DELETE
- 데이터 CURD 작업은 HTTP
5. ES 흐름도
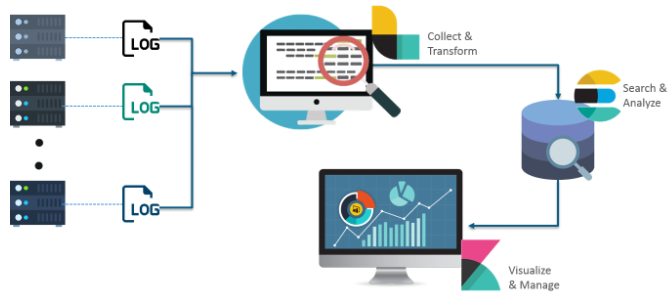
❓ ELK ?
- es는 검색을 위해
단독으로 사용될 수 있지만간단한 작동 원리를 그림으로 표현하기 위해 ELK먼저 설명합니다. - 흔히 말하는 ELK는 elasticsearch, logstash, kibana를 말합니다.
elsaticsearch는 위에 말했던 것 처럼 데이터를 저장하는저장소라고 이해하시면 됩니다.logstash는 실시간 파이프라인 기능을가진 오픈소스데이터 수집 엔진kibana는시각적으로 es의 색인된 데이터와 es의관리를 도와주는 오픈소스
💡 흐름
- 로그, 시스템 메트릭, 웹 애플리케이션 등 다양한 소스로부터
원시 데이터가 Elasticsearch에저장된다. - Elasticsearch에
색인된 데이터에 대해쿼리를 실행하며데이터를 분석 및 검색한다. Kibana로 es의 데이터를시각화하고 대시보드로 확인 할 수 있다.
6. ES 기본 구성
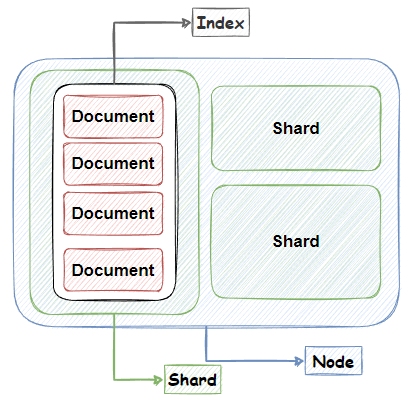
❓ Node
- Elasticsearch를 구성하는 하나의 단위 프로세스를 의미
🥊 노드 종류의 자세한 종류 링크
✒️ Node 종류
- Master-eligible node
- 인덱스 생성 또는 삭제, 클러스터의 일부인 노드 추적, 어떤 노드에 할당할 샤드 결정과 같은 가벼운 클러스터
전체 작업을 담당
- 인덱스 생성 또는 삭제, 클러스터의 일부인 노드 추적, 어떤 노드에 할당할 샤드 결정과 같은 가벼운 클러스터
- Data node
인덱싱한 문서가 포함된 샤드를 보유합니다. 데이터 노드는 CRUD, 검색 및 집계와 같은 데이터 관련 작업을 처리- 이 노드는 CPU, 메모리 등 자원을 많이 소모하므로 모니터링이 필요하며,
master 노드와 분리되는 것이 좋음
- Coordinatiog only nonde
- data node와 master-eligible node의
일을 대신하는 노드
- data node와 master-eligible node의
- Ingest node
- 하나 이상의 수집 프로세서로 구성된
전처리 파이프라인을 실행할 수 있다.
- 하나 이상의 수집 프로세서로 구성된
- Remote-eligible node
클러스터 간 클라이언트 역할을 하며 원격 클러스터 에 연결- 연결되면 클러스터 간 검색 을 사용하여 원격 클러스터를 검색
- 클러스터 간 복제 를 사용하여 클러스터 간에 데이터를 동기화할 수도 있다.
- Machine learning node
기계 학습 API 요청을 처리
- Transform node
- 변환을 실행하고
변환 API 요청을 처리
- 변환을 실행하고
❓ Shard
- 데이터를
분산해서저장하는 방법 - Elasticsearch에서 스케일 아웃을 위해
index를 여러 shard로 쪼갠 것 - 기본적으로 1개 존재
- 데이터가 많은 경우 검색
성능 향상을 위해인덱스의 샤드 갯수를 조정하여 튜닝
✒️ Shard 종류
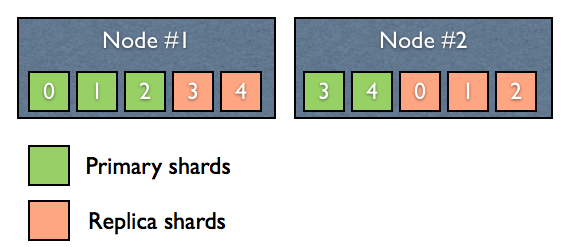
- primary shard
각 인덱스 별로 최소 1개 이상 존재- 인덱스에 다수의 문서를 색인하게 되면 문서는 설정된 샤드 수만큼 골고루 분산 저장
- replica shard
primary shard 의 복제본
❓ Index
- 서로 관련되어 있는 도큐먼트들의 모음
JSON 형색으로 데이터가 저장됨- 각 문서는 일련의 키(필드나 속성의 이름)와 그에 해당하는 값(문자열, 숫자, 부울, 날짜, 값의 배열, 지리적 위치 또는 기타 데이터 유형)을
서로 연결
📌 여담
- 드디어 ES를 정리하게 되다니 ㅜㅜ
📚 참고

나도 보기 위해 정리해 놓은 벨로그
안녕하세요 현 IT 보안 회사에서 재직 중입니다
로그분석 및 검색, 수집 하는데 ES 사용하고 있습니다!