사이드 프로젝트로 크롤링을 해본적은 있다. 그냥 단순한 웹사이트 하나를 크롤링하는 로직이였는데 이걸 처음 만들때는 참 애를 많이 먹었다.
여기서 다루는 크롤러는 당연히 저렇게 단순한게 아니고 검색엔진을 만들기 위해 전세계 모든 웹사이트를 돌아다니며 정보를 수집하는 크롤러를 만드는 예시를 보여준다.
일단 크롤링은 어디에 사용할 수 있을까.
- 검색 엔진 인덱싱: 크롤러가 가장 많이 사용되는 부분일 것이다. 크롤러는 웹 페이지를 모아서 검색 엔진에서 활용할 로컬 인덱스를 만든다. 일례로 google bot은 구글이 사용하는 웹 크롤러다.
- 웹 아카이빙 : 나중에 사용할 목적으로 장기보관하기 위해 웹에서 정보를 모으는 절차를 말한다.
- 웹 마이닝 : 웹의 폭발적인 성장세는 데이터 마이닝 업계에 전례 없는 기회다. 웹 마이닝을 통해 인터넷에 유용한 지식을 도출할 수 있을 것이다. 일례로 유명 금융 기업들은 크롤러를 사용해 주주 총회 자료나 연차 보고서를 다운받아 기업의 핵심 사업 방향을 알아내기도 한다.
- 웹 모니터링 : 크롤러를 사용하면 인터넷에서 저작권이나 상표권이 침해되는 사례를 모니터링할 수 있다. 일례로 디지마크(Digimarc)사는 웹 크롤러를 사용해 해적판 저작물을 찾아내서 보고한다.
챙겨야할 부분
- 규모 확장성 :
웹은 거의 수십억 개의 페이지가 존재하는 것으로 알려져 있다. 따라서 병행성(parallelism)을 활용하다 보면 효과적으로 웹 크롤링을 할 수 있을 것이다. - 안정성 :
웹은 함정으로 가득하다. 잘못 작성된 HTML, 바이러스, 악성코드, 반응 없는 서버, 장애 등등.. 크롤러는 이러한 비정상적인 입력이나 환경에 대응할 수 있어야 한다. - 예절(politeness):
크롤러는 수집 대상 웹 사이트에 짧은 시간 동안 너무 많은 요청을 보내서는 안된다. - 확정성: 새로운 형태의 콘텐츠에 대응하기 쉬워야 한다. 이미지 파일이나 동영상도 크롤링하고 싶다면 일ㄹ 위해 전체 시스템을 새로 설계해야 한다면 당신의 머리가 터져나가기 시작할 것이다.
대략적 설계
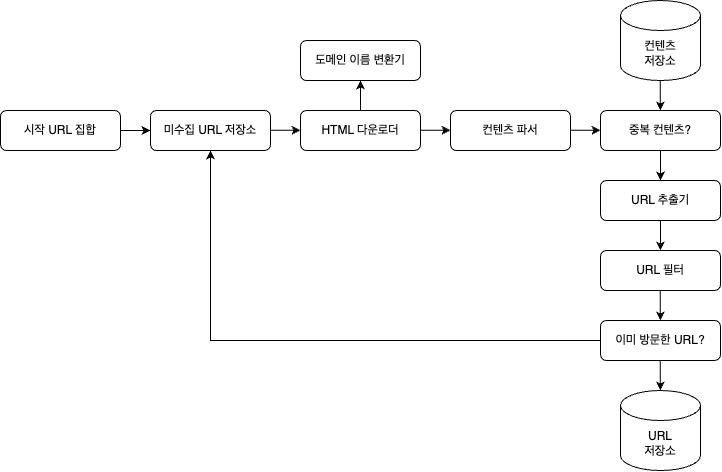
뭐 다이어그램적인 설계는 이해하기 쉬운 편이다. 그럼 일단 각 요소에 대해 어떤 기능을 수행하는지 알아보고 크롤러의 작업 흐름을 한번 살펴 보자.
시작 URL 집합
크롤링의 시작점이다. 어떤 대학 웹사이트로 부터 시작하면 이 사이트에 붙어있는 여러 하이퍼링크의 웹사이트를 크롤링하는 방식이다. 일반적으로 해당 대학의 도메인 이름이 붙은 모든 페이지의 url을 시작 url로 사용한다.
미수집 url 저장소
대부분의 현대적 웹 크롤러는 크롤링 상태를 다운로드할 url,다운로드된 url의 두가지 상태로 나눠 관리한다. 이 중 '다운로드할 url'을 저장 관리하는 컴포넌트를 미수집 url 저장소라고 부른다. FIFO큐라고 생각하면 된다.
도메인 이름 변환기
url을 ip 주소로 변환하는 절차가 필요하다.html 다운로더는 도메인 이름 변환기를 사용해 url에 대응하는 ip주소를 알아낸다. 쉽게 말해서 url을 통해 연결되있는 dns를 한번 타고 여기에 연결되어 있는 ip주소를 따오는 방식이다.
콘텐츠 파서
일단 웹 페이지를 다운로드하면 파싱과 검증을 거쳐야 한다. 이상한 웹페이지라면 걸러야하기 때문이다. 따라서 일종의 로직을 작성해 콘텐츠가 정상적인지 확인하고 파싱을 해야한다.
그리고 크롤링 서버 안에 콘텐츠 파서를 만들만 좋지 않다. 콘텐츠 파싱이라는 작업 자체가 좀 무거운 작업이될 가능성이 높기 때문에 이는 별도의 컴포넌트로 만드는 것이 바람직하다.
중복인가?
웹에 공개된 연구 결과에 따르면,29% 가량의 웹페이지 콘텐츠는 중복이다.
날로먹는 애들이 많다는 뜻이다. 고로 우리는 같은 콘텐츠를 여러번 저장하게 될 가능성이 크다. 따라서 이를 잘 걸러내는 로직이 필요하다. 가장 간단한 방법은 두 html 문서를 열로 보고 비교하는 것이지만 이는 너무 무거운 작업이 된다. 효과적인 방법은 웹페이지의 해시 값을 비교하는 것이라고 한다.
콘텐츠 저장소
크롤링을 잘 했다면 잘 저장해야 한다. 요구 사항에 맞는 저장소를 사용하고 필요한 구조로 잘 저장하면 될 것이다. 대략적으로 아래의 두가지만 신경 쓰면 될듯 하다.
- 데이터가 분명 엄청 많을 것으로 디스트에 저장한다.
- 인기 있는 콘텐츠를 메모리에 두어 캐시한다.
URL 추출기
URL추출기는 html페이지를 파싱해서 안에 있는 다른 페이지로 향하는 url들을 골라내는 역할을 한다. 일반적으로 상대링크로 되어 있는 링크들을 절대 링크로 바꾸어 추출한다. 예를들어 www.naver.com의 하위 링크인 /user1 이라는 링크가 있다고 치면 www.naver.com/user1로 변환한다.
URL 필터
특정 콘텐츠 타입이나 파일 확장자를 갖는 url. 접속시 오류가 발생하는 url, 접근 제외 목록에 포함된 url등을 크롤링 대상에서 배제하는 역할을 한다.
이미 방문한 URL?
이를 구현하기 위해서는 이미 방문한 url이나 미수집 url 저장소에 보관된 url을 추적할 수 있도록 자료 구조를 사용하면 된다. 이미 방문한 적 있는 url인지 추적하면 같은 url을 여러번 처리하는 일을 방지할 수 있으므로 서버 부하를 줄이고 같은 url을 여러번 처리하는 일을 방지할 수 있다.
URL 저장소
이미 방문한 url을 보관하는 저장소다.
웹 크롤러 작업 흐름
위에 그림을 다시 봐보자.
대략적인 흐름은 이 그림의 흐름과 같다.
- 시작 url들은 미수집 URL 저장소에 저장한다.
- HTML 다운로더는 미수집 URL 저장소에서 URL 목록을 가져온다.
- HTML 다운로더는 도메인 이름 변환기를 사용해 URL의 ip 주소를 알오고, 그 ip 주소로 접속해 웹페이지를 다운받는다.
- 콘텐츠 파서는 다운된 html 페이지를 파싱하여 올바른 형식을 갖춘 페이지인지 검증한다.
- 콘텐츠 파싱과 검증이 끝나면 중복 콘텐츠인지 확인하는 절차를 진행한다.
- 중복 콘텐츠인지 확인하기 위해서, 해당 페이지가 이미 저장소에 있는지 본다.
- url 추출기는 해당 html 페이지에서 링크를 골라낸다.
- 골라낸 링크를 url 필터로 전달한다.
- 필터링이 끝나고 남은 url만 중복 url 판별을 진행한다.
- 이미 처리한 url인지 확인하기 위해서 URL 저장소에 보관된 URL인지 살핀다. 만약 이미 있다면 해당 URL을 버린다.
- 저장소에 없는 url은 url 저장소에 저장할 뿐 아니라 미수집 url 저장소에도 전달한다.
위와 같은 방식으로 크롤러는 작동한다. 다음에는 좀 더 세부적으로 크롤러의 설계에 대해 알아보자
