관계형 데이터베이스에서 각 레코드를 식별해야 한다. 일반적으로 새로운 레코드가 생성될 때 마다 +1이 되는 'auto_increment' 속성을 사용해서 자동생성되게 하면 되지 않나 라고 생각하는데 이는 대규모 서비스 설계에서는 그닥 좋은 방법이 아니다 왜냐
대규모 시스템 설계에서는 여러대의 데이터베이스 서버를 사용할 수 있기 때문이다.
일반적으로 그렇다. 데이터를 분산 저장하기 위함도 있고, 데이터 베이스가 죽었을 때 서비스를 계속 이어 나가려면 당연히 2대 이상의 데이터베이스 서버가 필요하겠지..
그럼 여기서 문제는 여러 서버에 분산되어 있는 데이터의 유일성을 어떻게 챙겨야할까 여기서 사용되는 개념이 유일 ID 생성기이다.
이를 구현하기 위한 방법은 크게 4가지가 있다.
1.다중 마스터 복제
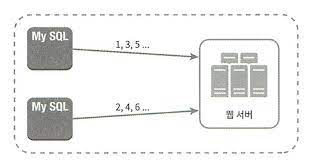
일반적으로 레코드 생성시 사용하는 auto_increment기능을 활용하는 것이다. 다만 다음 ID값을 구할 때 1만큼 증가 시키는게 아니다. 예를들어 사용하는 mysql 서버가 3대라고 하면,
- A 서버에서는 ID를 1,4,7.... 순으로 생성한다.
- B 서버에서는 ID를 2,5,8.... 순으로 생성한다.
- C 서버에서는 ID를 3,6,9.... 순으로 생성한다.
그럼 결과적으로 순차적으로 모든 중복되지 않는 유일한 ID값이 생성되게 된다.
하지만 얘는 아래의 이유로 구리다.
- 여러 데이터 센터에 걸쳐 규모를 늘리기 어렵다.데이터 서버를 여러대 늘리면그에 맞춰 기존의 서버의 ID값 생성로직을 모두 손봐야 한다.
- 또한 ID의 유일성은 보장되겠지만 시간의 흐름에 따라 맞추기는 어렵다.
위 예시에서 A서버에 빠르게 2개의 데이터가 들어와서 ID 1,4를 받았다, 그 후 B서버를 통해 데이터가 들어왔다면 2의 ID를 받으면 시간순으로 나열하기는 어려워진다.
2. UUID (Universally Unique Identifier)
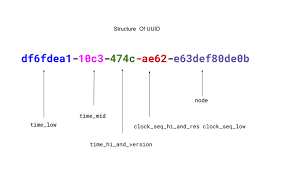
아마 어디선가 자주 봤던 방식일 것이다. 128비트짜리 랜덤한 수이다. UUID 중복 가능성이 매우매우매우 낮다. 위키피디아에서는
"중복 UUID가 1개 생길 확율을 50%까지 끌어 올리려면 초당 10억 개의 UUID를 100년 동안 계속해서 만들어야 한다."
라고 한다.
이 방식의 장점은 단순하다는 점이다. 라이브러리도 많아서 보편적으로 꽤 많이 사용하는 방식이다. 그리고 중복되지 않으니 자기가 쓸 ID를 알아서 만들기 때문에 서버 확장이니 축소에 용이하다.
하지만 단점도 존재한다.
일단 ID값이 128비트로 길며, 다중 마스터 복제 방식과 마찬가지로 시간순으로 정렬할 수 없다.
3. 티켓 서버

쉽게 생각하면 모든 데이터베이스 쓰기 요청이 하나의 서버로 들어가서 순차적으로 id를 발급 받는 것이다.
장점은 어떻게든 유일성이 보장되는 숫자로만 구성된 ID를 만들기 쉽다. 그리고 순차적으로 만들어지니 시간순으로 나열하기도 쉽겠다.
하지만 티켓 서버가 SPOF(Single-Point-of-failure)가 될 가능성이 크다. 쉽게 말해서 이 티켓 서버가 다운되면 모든 시스템에 영향을 줄 가능성이 크다. 따라서 여러대의 티켓서버를 준비해야 한다.
4. 트위터 스노플레이크 접근법
각재 격파 전략(divide and conquer)를 사용해보자. 생성해야 하는 ID의 구조를 여러 절(section)으로 나누는 것이다. 각 절 마다 가지고 있는 정보를 달리한 후 하나로 뭉쳐 ID로 사용하는 것이다. 아래 그림을 보자.
이런 방식으로 아이디에서 사용할 절 들을 독립적으로 나누어 사용하면된다. UUID와 비슷하다.
이렇게 하면 앞 단의 타임 스템프로 시간순으로 정렬할 수 있다. 그리고 1/1000초까지 체크하기 때문에 정확하게 같은 시점에 들어와서 생성되는 ID는 "거의" 없을 것이다. 설사 있더라도 생성하는 데이터센터ID, 서버ID등이 다르고 일련번호를 랜덤하게 생성하게 된다면. 정확히 같은 아이디의 생성은 자연적으로 불가능하게 된다.
