데이터 마이닝 예시를 통해 실습해보자
Basket Data
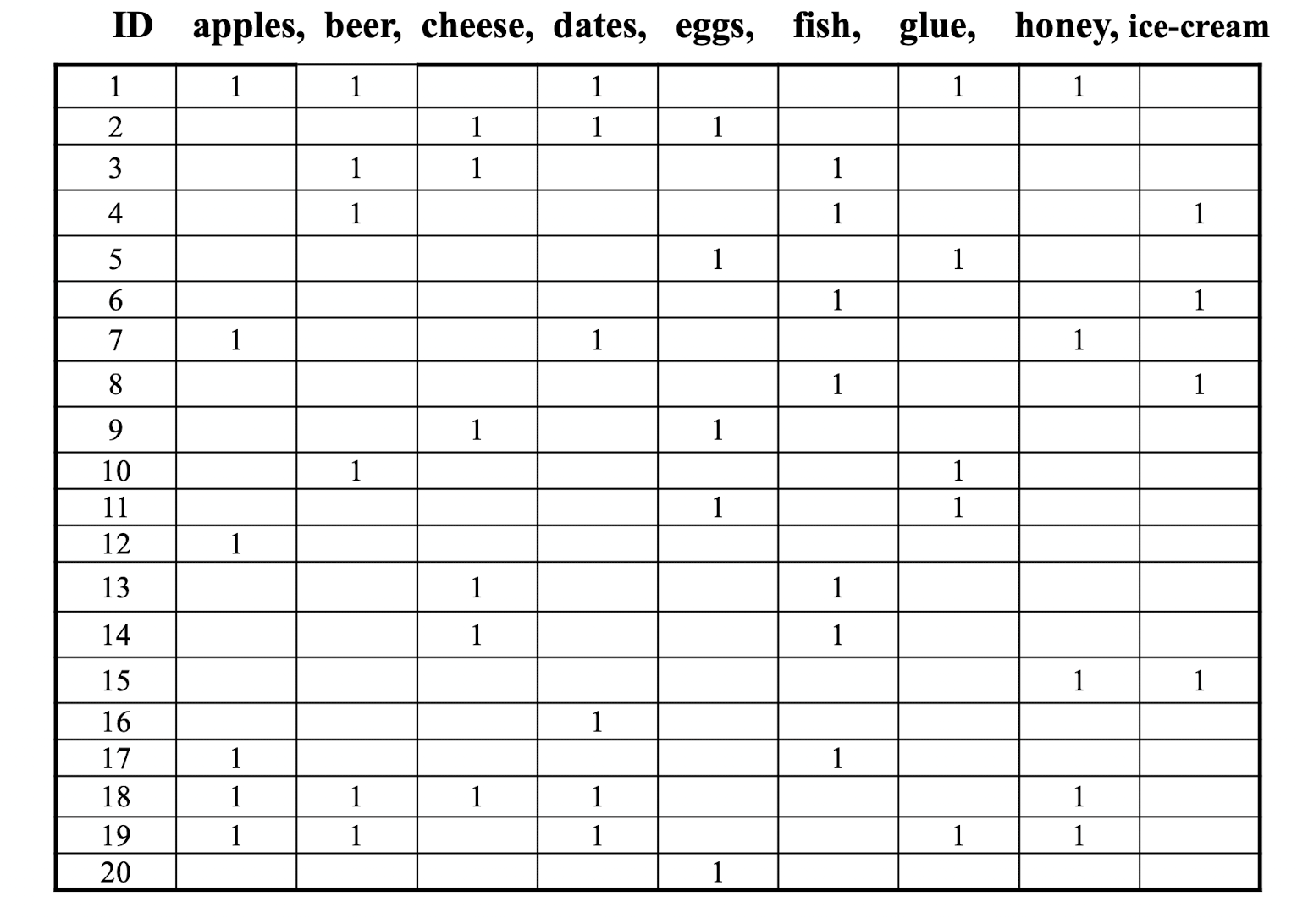
각 레코드는 소비자와 shop 사이의 transaction을 나타내고 있다.
20개의 레코드가 존재하며 shop은 9 개의 상품을 판매하고 있다.
Discovering Rules
여기서 의미하는 'rule'은 다음과 같다
만일(if) basket이 apple과 cheese를 포함하고 있다. 그렇다면(then) 해당 basket은 beer를 포함하고 있다.
이와 같은 연산을 위한 두개의 measure가 존재한다
- Confidence
'만일' 이 true일 경우, '그렇다면'이 true일 확률 - Coverage
DB가 얼마나 많은 '만일'을 소유하고 있는가
적용 예시
만일 basket이 beer와 cheese를 포함하고 있다. 그렇다면 honey도 포함하고 있다.
20개의 레코드 중 2개의 레코드가 beer와 cheese를 포함하고 있다.
Coverage는 10% 이다.
해당 Coverage 중 honey를 포함하고 있는 레코드는 한 개이다.
Confidence는 50%이다.
용어
- k-itemset : k 개의 아이템을 가지고 있는 set
- support : 해당 itemset이 support S% 라는 것은 해당 itemset을 포함하고 있는 tuple이 전체 tuple 중 S%
연관규칙 분석 알고리즘 (Apriori)
특정 사건이 발생하였을 때 함께 (빈번하게) 발생하는 또 다른 사건의 규칙을 구하는 알고리즘. 가지치기를 통해, 경우의 수를 획기적으로 줄일 수 있다.
- 최소한의 coverage를 가진, 모든 itemset을 찾는다.
- 해당 Itemset을 통해, 관심있는 rule을 생성한다.


사용 예시
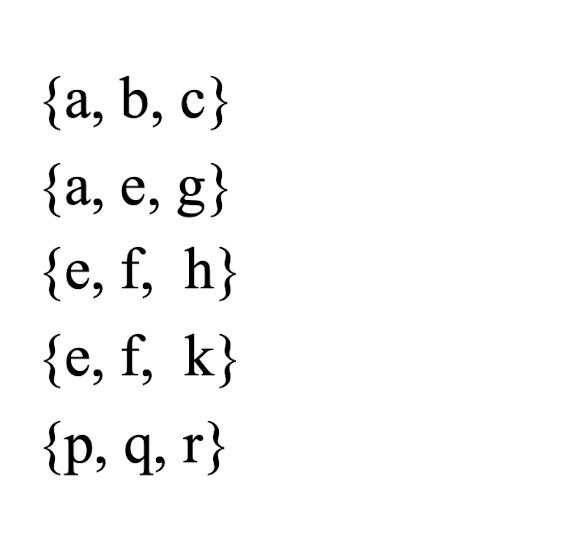
위의 itemset들만이 table에서 10% 초과의 support를 가지고 있을 때 , 10%의 support를 가지고 있는 4-itemset을 어떻게 생성할 수 있을까?

- 우선 모든 itemset의 원소들이 모인 set을 생성해준다.
- 여기서 4개를 골라서 비교하기에는 10C4라는 어마무시한 경우의수가 발생!

- 모든 10C4의 itemset중에서 {a,b,e} subset이 포함된 itemset은 pruning을 할 수 있다. {a,b,e}는 10% support를 넘지 않기때문이다. subset보다 parentset의 support가 커질수 없다는점을 이용하는 것이다.

- {e,f,h}와 {e,f,k} 모두 10% 초과의 support를 소유하고 있다. {e,f}라는 동일한 K-1개의 subset을 각자 소유하고 있으므로 {e,f,h,k}는 candidate가 될 수 있다.

CS 박제