📌 대량 데이터 발생에 따른 테이블 분할 개요
♦ 대량의 데이터 발생에 따른 문제점들 ♦
-
대량의 데이터가 하나의 테이블에 집약되어있고, 하나의 하드웨어 공간에 저장되어 있으면 성능저하가 생긴다.
-
하나의 테이블에 매우 많은 컬럼이 존재하여 디스크의 많은 블록을 점유하는 경우에도 성능이 저하될 수 있음
-
대량의 데이터가 저장된 테이블의 인덱스의 경우에도 인덱스의 트리구조가 너무 커져 DML처리를 할 때 성능이 저하되는 경우가 발생함
-
칼럼이 많아지면 물리적인 디스크의 여러 블록에 걸쳐 저장되므로 Row 길이가 길어 로우체닝과 로우 마이그레이션이 많아 짐 -> 성능저하
💡 로우체닝과 로우 마이그레이션이란? 💡
- 로우체이닝(Row Chaining) : 로우 길이가 너무 길어서 데이터 블록 하나에 데이터가 모두 저장되지 않고 두 개 이상의 블록에 걸쳐 하나의 로우가 저장되어 있는 형태
- 로우마이그레이션(Row Migration) : 데이터 블록에서 수정이 발생하면 수정된 데이터를 해당 데이터 블록에서 저장하지 못하고 다른 블록의 빈 공간을 찾아 저장하는 방식
🔥 따라서 테이블단위에서 분할의 방법을 적용할 필요가 있다!
📌 대량 데이터 저장 및 처리로 인해 성능
-
대량 데이터가 예상될때, 파티셔닝 및 PK 에 의해 테이블 분할 하는 방법을 적용할 수 있다.
-
파티셔닝 방법으로는 아래와 같다.
- LIST PARTITION(특정값 지정)
- RANGE PARTITION(범위)
- HASH PARTITION(해쉬적용)
- COMPOSITE PARTITION(범위와 해쉬가 복합)
데이터가 대량으로 많이 있을 때 논리적으로는 하나의 테이블로 보이지만 물리적으로는 여러 개의 테이블 스페이스에 쪼개어 저장될 수 있는 구조의 파티셔닝을 사용하면 성능을 개선 할 수 있다.
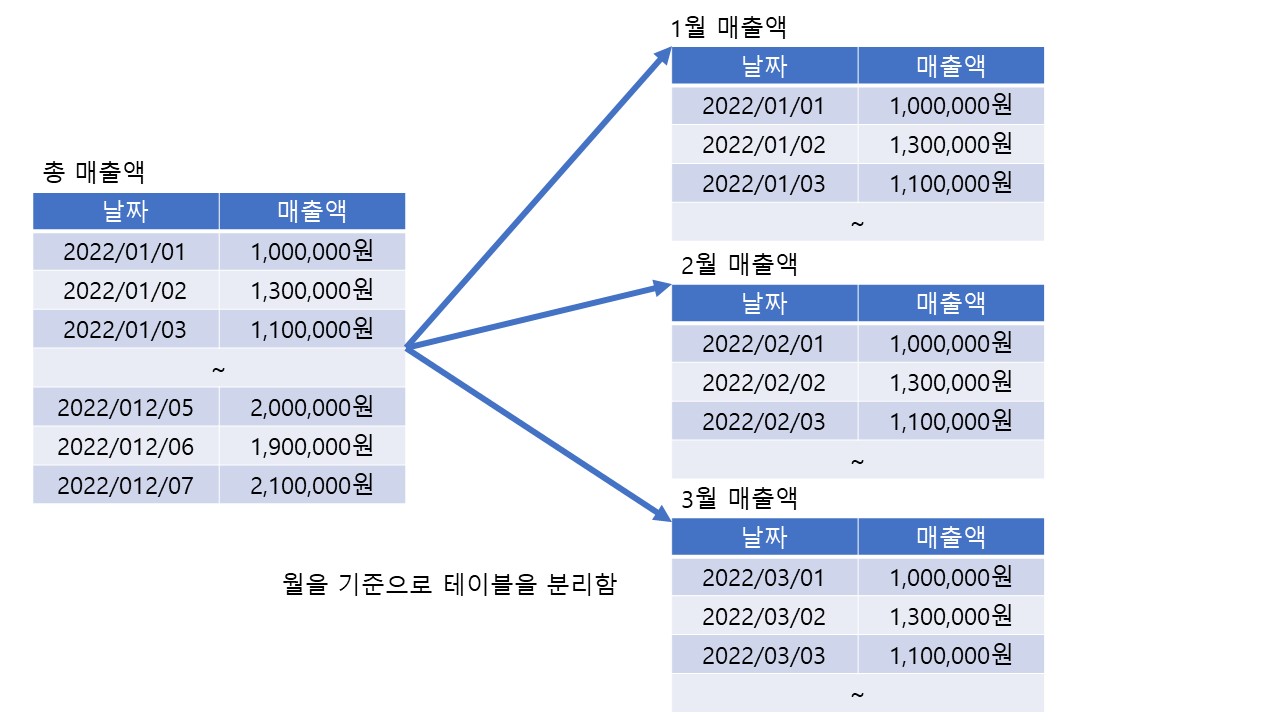
1. Range Partition(범위)
- 대상 테이블이 날짜 또는 숫자값으로 분리가 가능하고 각 영역별로 트랜잭션이 분리된다면 RANGE PARTITION을 적용한다.
- 가장많이 사용하는 파티셔닝 기법이다.
- 테이블에 데이터를 쉽게 지우는 것이 가능하다.
- 보관주기에 따른 테이블관리가 용이하다.
📝예시)
[날짜 + 매출액] 으로 구성되어 있는 대용량의 테이블의 경우
월 단위 또는 년 단위로 테이블을 나누어 저장한다.
2. LIST PARTITION(특정값 지정)
-
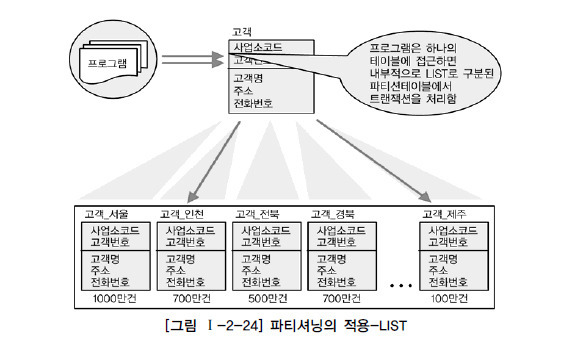
지점, 사업소, 사업장, 핵심적인 코드값 등으로 PK가 구성되어있고, 대량의 데이터가 있는 테이블이라면 값 각각에 의해 파티셔닝이 되는 LIST PARTITION을 적용할 수 있다.
-
대용량 데이터를 특정값에 따라 분리하여 저장할 수 는 있으나 RANGE PARTITION과 같이 데이터 보관주기에 따라 쉽게 삭제하는 기능은 제공될 수 없다.
📝예시)
대용량의 고객 테이블이 존재할때
지점, 사업소와 같은 핵심적인 PK를 기준으로 파티션을 나눈다
강남지점고객, 마포구지점고객 처럼....
3. HASH PARTITION(해쉬적용)
- 지정된 해쉬 알고리즘을 적용하여 테이블을 분리함
- 설계자는 어떤 파티션에 데이터가 저장되는지 알기 어려움
4. COMPOSITE PARTITION(범위와 해쉬가 복합)
- Main/ Sub 관계로 나누어 분할하는 파티셔닝 기법.
참고 블로그
https://eehoeskrap.tistory.com/56
https://antkdi.github.io/posts/post-license-sqld-bigdata/
https://earthconquest.tistory.com/46
