Learning Discriminative Features with Multiple Granularities for Person Re-Identification
Abstract
전역적인 특성과 지역적인 특성을 합치는 것은 식별 모델을 학습시키는 방법으로 좋다. 기존의 part-based 방법은 미리 정의된 의미론적인 부분을 찾아 지역적 특성 학습시키는 식으로 진행하였지만, 이는 학습의 난이도가 높고 비효율적이었다. 따라서 본 연구에서는 다양한 정도의 세분화된 정보를 통합하여 학습하는 모델, Multiple Granularity Network(MGN)을 제안한다. MGN은 전역적 특성을 얻을 수 있는 하나의 branch와 지역적 특성을 얻을 수 있는 두개의 branch들로 구성되어있다. 전역적 특성을 얻는 branch는 여러개의 branch 들의 합으로 나누어 구현하였다. 본 연구에서는 의미론적인 영역을 학습하는 것이 아니라, 입력을 여러개의 부분으로 나눈 뒤 각기 다른 개수의 부분을 각 branch들에게 입력하여 다양한 세밀도의 지역적 정보를 얻어 학습한다.
Introduction
Person re-identification(Re-ID)는 보안 카메라에의해 저장된 보행자 이미지들에서 주어진 사람을 찾는 작업으로, 사람들이 자세, 옷, 배경 등에 의해 달라질 수 있다는 점 때문에 어려운 작업으로 여겨진다. Deep convolution network의 발달은 Re-ID의 성능을 한층 높였다.
Re-ID를 하기 위해선 보행자의 전체적인 이미지로부터 구별할 만한 특성을 찾아내야 한다. 전역 정보 학습의 목표는 이미지들에서 가장 두드러지는 특성을 찾아낸 데 있다. 이를 효과적으로 수행해 내기 위해선 대규모 정보를 학습해 보행자를 식별해야 하지만 보안 카메라 이미지의 복잡성 때문에 전역적인 Re-ID의 정확도가 낮다. 이는 Dataset의 크기와 다양성이 제한적이기 때문으로 세부정보에 대한 학습이 제대로 이루어 지지않게 되는 것에서 기인한다. 세부정보 없이는 비슷한 군에서의 구별이 쉽지 않게 된다.
이러한 문제를 해결하기 위한 방법으로 몸의 특정 부위를 찾아 지역 정보를 얻어내는 방법이 주로 사용되어 왔다. 각 부위들은 극소량의 지역 정보를 포함하기 때문에 불필요한 정보를 걸러내는 추가적인 연산을 수행해야 한다. 이러한 part-based 학습 방법은 다음과 같은 순서로 진행된다.
- 미리 입력된 구조적 지식을 이용해 중요 부위의 위치를 찾는다.
- 다른 학습 방법을 통해, 구조직 지식을 이용하는 방법 외에 별도의 학습 방법, 중요 부위의 위치를 찾는다.
- 두 위치를 배합해 지역적으로 중요한 특성을 찾아낸다.
그러나 이 방법은 다음과 같은 문제점으로 인해 성능을 높이는 데에 제한이 있다.
- 자세나 가려짐의 변화는 지역 정보 신뢰성에 영향을 줄 수 있다.
- 이러한 방법들은 거의 고정된 의미론적 부분에만 초점을 맞추며, 모든 판별 정보를 다룰 수 없다.
본 연구에서는 전역 정보와 다양한 세밀도의 지역 정보를 배합함으로써 위 문제점을 해결하고자 한다. 미리 정의된 의미론적 영역에 따라 입력을 분할하지 않고, 그저 여러 개의 동일한 간격으로 입력을 분할해 각기 다른 입력을 만들어 입력한다. 넓은 간격으로 분할할수록 더 전역적인 정보를 표현하는 출력이 나오고 좁은 간격으로 분할할수록 더 지역적인 정보를 표현하는 출력이 나온다. 이러한 특성을 고려하여 MGN은 backbone의 4번째 stage부터 전역적인 정보를 학습하는 branch 1개, 지역적인 정보를 학습하는 branch 2개로 나누어 학습을 진행한다. 후자의 경우 전역적인 정보가 담긴 feature map들을 분할한 입력이 입력되어 다른 branch들과 독립적으로 학습된다.
앞서 언급한 바와 같이, MGN은 part-based 방법과 다르게 동일한 간격으로 분할된 입력을 사용한다. 또한, end-to-end 학습으로서 학습과 추론에 용이하다.
Introdution Summary
- Re-ID의 한계
Deep Convolution Network를 이용해 얻어낸 전역 정보는 Re-ID의 dataset특성 상 보행자 식별에 큰 도움이 안된다. 전역 정보를 보완할 세부정보가 필요하다. - 기존 방법
미리 입력해 둔 중요 신체 분위에 대한 정보를 바탕으로, 식별에 있어 중요한 부위를 찾아낸다. 이후 불필요한 정보를 걸러내는 작업을 거쳐 지역 정보를 얻어 낸다. 이는 end-to-end 학습이 아니고, 미리 입력해 둔 부위에 대한 정보만 활용할 수 있다는 문제점이 존재한다. - MGN
미리 입력해 둔 정보를 활용하여 입력을 분할하지 않고, 일정한 간격으로 입력을 분할하여 사용한다. 다양한 크기의 간격을 사용해 다양한 세밀도의 지역 정보를 얻어낸다. 댜양한 세밀도의 정보를 얻기 위해 branch를 분기시켜 독립적인 학습을 진행시킨다. 이는 다양한 부위의 정보를 활용할 수 있고, end-to-end 학습이기에 학습 및 추론 효율이 높다.
Related Works
Deep learning이 발전하며 Re-ID 분야에도 deep network가 많이 사용되었다. ID-discriminative Embedding(IDE)나 deep siamese network 구조 등이 제시되었다. 지역 정보간의 관계를 이용해 식별하는 모델, Domain Guided Dropout 등의 방법도 소개되었다.
최근에는 part-based 정렬를 사용해 성능 향상을 이루었다. 이외에도 입력이미지를 일정한 간격으로 나누어 학습하고 전역 정보와 합성해 학습하거나, 나누어진 입력 이미지들의 학습 결과를 바로 최종 출력으로 사용하는 등의 시도가 이루어졌다. 그러나 아직 개선해야할 점이 많다.
...
Multiple Granularity Network
Part-based 모델의 경우, 미리 정의된 의미론적 부위로 입력을 나누어 학습한다. 하지만 불필요한 정보를 지우기 위해 수행된 연산으로 인해 큼직한 부위만 활용하게 되고 세세한 부위의 정보는 활용할 수 없게 된다. 이러한 결과는 이미지의 양에 따라 특정 부위에 학습을 집중할 수 있는 능력이 결정되다는 것을 나타낸다. 이러한 현상은 주어진 부위에 대한 제한된 정보로 인해 생긴다고 생각한다. 지역적인 정보는 전역적인 정보와 비교하였을 때 식별능력이 떨어진다.
기존의 part-based 학습들은 학습에 있어 사전 지식의 여부와 상관 없이 기본적인 세밀도의 부위만 가지고 학습을 진행하였다. 세밀도의 다양성이 적절하다면 deep network은 적절한 세밀도를 찾아 집중하여 정확한 결과를 얻어낼 수 있을 것이다.
Network Architecture
MGN은 ResNet-50을 이용해 backbone을 구성했다. 기존의 모델과는 다르게 res_conv4_1 블럭을 세개의 branch로 분기하였다.
아래 표는 각 branch들의 설정을 나타낸다.
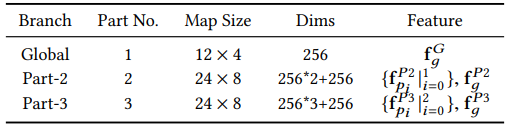
첫번째 branch에 대해서는 stride를 2로 설정한 convolution을 통해 down-sampling을 진행한다. 이후res_conv5_1 block에서 global-max-pooling과 batch normalization을 수반한 convolution, 마지막으로 ReLU를 진행한다. 이 branch는 전역적인 특성을 학습하므로 Gloabal Branch라 명명한다.
두번째, 세번째 branch는 Gobal Branch와 비슷한 구조를 가지고 있다. 차이점이라면 지역적인 정보 학습을 위한 입력의 크기를 유지하기 위해 down-sampling을 수행하지 않는 다는 점이다. 입력을 수평으로 여러 부분을 나누어 Global Branch와 같은 학습을 수행한다. 이러한 branch들을 Part-N Branch라 명명한다. N은 나누어진 부분의 개수를 의미한다.
Loss Function
...
Discussions
MGN은 다음과 같은 몇가지 문제점이 존재한다.
Muti-branch Achitecture
MGN은 초기 단계에서는 전역 정보와 지역 정보를 동일한 하나의 branch에서 학습을 진행하는 것이 합리적으로 보인다. res_conv5_3에서 추출된 동일한 feature map을 동일한 크기로 나누어 학습을 진행한다. 그러나 이러한 학습 설정은 비효율적인 것으로 보인다. 이는 분기된 branch들의 구조가 비슷하기 때문으로 생각된다. 하나의 혼합된 branch에 그저 다른 세밀도의 정보를 학습시키는 것은 세부정보를 얻어내기에 적합하지 않다. 따라서 기존의 분기 시점 이전 혹은 이후에도 분기를 진행하여 학습을 진행하였지만 나은 결과를 얻진 못했다.
Diversity of Granularity
