DLRM은 추천 시스템을 위한 대표적인 딥 뉴럴 네트워크 모델 중 하나이다.
DLRM에서는 categorical feature을 dense 표현으로 매핑하기 위해 임베딩을 사용한다.
추천 시스템에서 임베딩을 사용하는 이유에 대해
NLP에서 워드 임베딩을 사용하는 이유는 각 단어의 의미를 표현하기 위해 주변 단어들과 그 단어의 의미를 파악하기 위함이다.
추천 시스템에서도 동일한 이유다. 사용자의 선호 정보를 원-핫 벡터로 표현하다면 의미를 가지기 어렵다. 그러므로 dense 표현으로 임베딩할 필요가 있다.
뉴럴 네트워크에서 spare 표현 대신 dense 표현인 임베딩을 사용하는 이유에 대해
- categorical 값의 차원을 줄이고 추상 공간에 categorical 값을 표현한다.
- 임베딩 사이 간의 거리를 의미를 관련하여 측정 가능하다.
- 임베딩 벡터는 n 차원의 item 공간을 더 작은 차원의 임베딩 벡터로 투영시킨다.
용어 정리
1- Item (or document): 시스템이 추천하는 엔티티(Entities)이다
2- Query (or context): 시스템이 추천을 생성할 때 사용되는 정보로 사용자 정보와 추가 컨텍스트가 포함될 수 있다.
3- Numerical data(수치형 데이터): 속성을 해당 컬럼에 수치 값으로 표현한 데이터이다.
4- Categorical data(범주형 데이터): 수치로 표현할 수 없어 각 속성을 고유한 컬럼으로 부여한 matrix 데이터이다.
예를 들어 사용자가 본 영화를 matrix로 표현한다면 각 영화명을 각 column으로 표현하고, 각 사용자는 row로 표현할 수 있다. 이때 사용자가 해당 영화를 봤을 때 ‘1’로 해당 영화를 보지 않았을 때 ‘0’으로 표현할 수 있다.(one-hot encoding 방식) Categorical data는 수치로 표현될 수 없고 주로 sparse matrix 형태로 표현된다.
임베딩이란?
추천에서 임베딩은 categorical 데이터를 연속된 숫자의 벡터 공간에 매핑하는 것이다.
먼저 텍스트를 숫자로 표현하는 방법을 이해해보자.
자연어는 수치화되지 않는 데이터이기 때문에 머신러닝에 활용하기 위해서는 수치화 작업이 필요하다.
따라서 자연어 처리 'feature extraction'을 통해 수치화를 해야 하고 여기서 언어의 벡터화에 word embedding을 하게 된다.
3가지 전략을 살펴보자.
첫번째 전략. one-hot 인코딩
Vocabulary(단어 집합) 중에 문장에 나타난 단어를 ‘1’로 인코딩하는 것이다.
예를 들어 1만개의 단어의 index를 만든 후 해당 단어와 매핑관계를 벡터로 표현한 것으로 “The cat sat on the mat” 문장은 다음과 같이 one-hot 인코딩으로 표현한다.
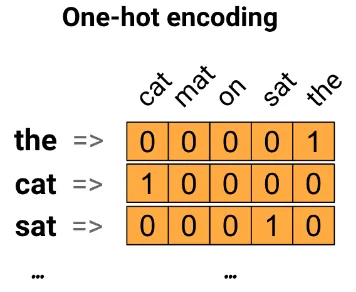
one-hot 인코딩의 문제점은 대부분의 index가 ‘0’으로 sparse하기 때문에 비효율적이다는 점이다.
위의 “The cat sat on the mat”와 5개의 단어를 포함한 1문장을 표현하기 위해 (10000, 5) matrix가 필요하다.
두번째 전략. 각 단어를 고유 번호로 인코딩
“The cat sit on the mat”를 단어별 고유번호를 이용하여 [5,1,4,3,5,2]와 같이 코딩할 수 있다. one-hot 인코딩이 sparse인 단점을 dense하게 표현하여 해결하였다 . 하지만 이 방법도 단어간의 유사성(단어간의 관계)을 반영할 수 없는 단점이 있다.
세번째 전략. Word Embedding (단어 임베딩)
Word 임베딩은 유사한 단어끼리 유사한 인코딩을 갖도록 하며 효율적이고 dense한 표현을 제공한다.
이 때 임베딩은 floating point값의 dense 벡터로 표현된다.
벡터의 길이인 차원(dimension)은 사용자가 지정하는 파라미터이며 dimension의 크기는 8~1024 사이로 하는 것이 일반적이다.
더 높은 dimension의 임베딩은 단어간의 세부 관계를 캡처할 수 있지만 학습에 더 많은 데이터가 필요하다.
임베딩 값은 수동으로 지정하는 것이 아니라 뉴럴네트워크의 weights를 학습하는 것과 같이 임베딩도 학습을 시킨다.
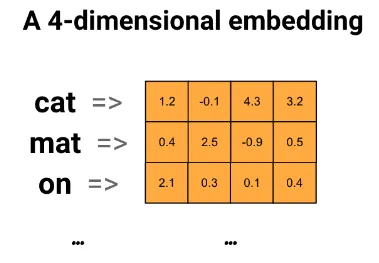
위는 “The cat sat on the mat”문장을 word 임베딩으로 표현한 그림이다.
예를 들어 단어 “cat”는 float point 값의 4 dimension, 벡터([1.2, -0.1, 4.3, 3.2])로 표시된다.
레퍼런스
[1] Google Recommendation 고급과정
링크텍스트
[2] Tensorflow — word embedding
링크텍스트
[3] Deep Learning Recommendation Models(DLRM): A Deep Dive
링크텍스트
