최근 기존 RDBMS 프로그램인 데이터 웨어하우스를 넘어서는 데이터들의 저장과 활용이 요구되는 상황에서 데이터레이크라는 새로운 저장 방식이 각광받고 있다고 하여 찾아본 자료를 정리해보고자 한다.
데이터 레이크(Data Lake)란?
모든 정형, 반정형, 비정형 및 이진 데이터를 순수한 형태로 저장할 수 있는 시스템을 말한다.
한마디로 "무엇이든 저장할 수 있는 중앙 집중식 데이터 저장소"
데이터를 먼제 정제, 구조화할 필요 없이! 그대로 저장한 뒤에, 필요할 때 필요에 맞게 추가적인 정제과정을 거쳐 머신러닝, 실시간 분석, 데이터 보드나 시각화 등을 하는 것이다.
즉 데이터레이크의 존재 이유는 데이터레이크 기반 분석 플랫폼이라고 할 수 있다.
Data Lake 최종 목적
1. 머신러닝(Machine Learning)
2. 실시간 분석(real-time assay)
3. 시각화(Visualization)
그렇다면 왜 데이터레이크 기반 분석 플랫폼인가?
기존에 익숙했던 데이터 웨어하우스라고 하는 MySQL, PostgreSQL 같은 RDBMS 프로그램들은 미리 짜여진 구조를 통해 데이터를 가공해서 저장했기에 좀 더 접근하기 쉬었다. 하지만 최근에는 다양한 산업군에서 데이터 활용도가 점점 커지고 있고 실시간으로 발생되는 다양한 형태의 데이터를 통해 자동화 업무 개선, 위협 탐지, 미래 예측 등의 비즈니스 가치 창출이 가능하게 되었다.
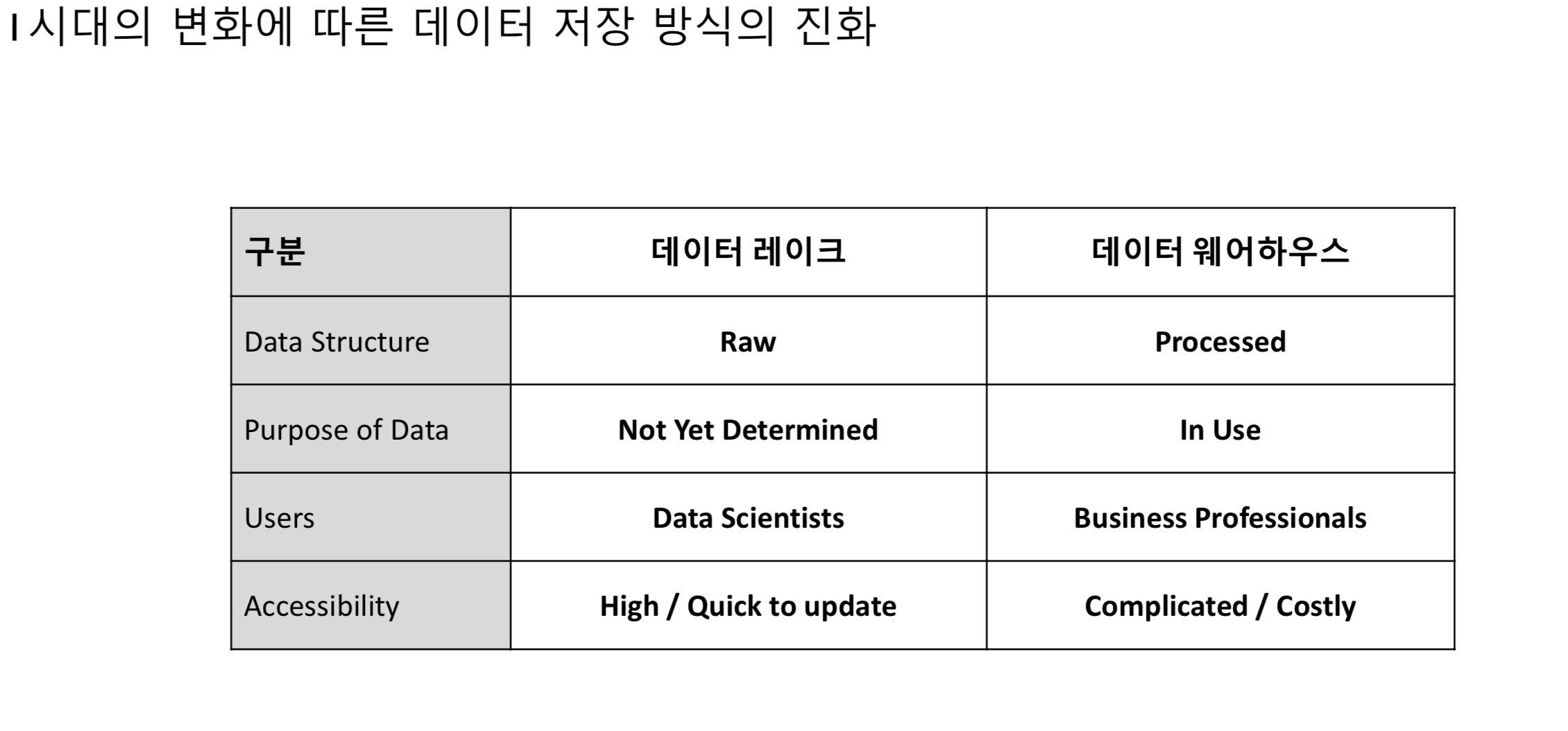
데이터 레이크는 데이터가 너무 방대하기 때문에 어떤 데이터를 어떻게 사용할지 모르므로 Raw 데이터를 저장한다. 그렇기 때문에 데이터에 대한 접근성이 조금 떨어지는 면이 있었지만 Hadoop이나 Spark 같은 다양한 서비스들을 통해 그런 단점을 보완하여 처리할 수 있게 되었다.
AWS 기반 데이터레이크
데이터레이크 기반 분석 플랫폼을 구현하기 위해서는 AWS 제공 Native 서비스나 상용 솔루션을 활용하면 된다.
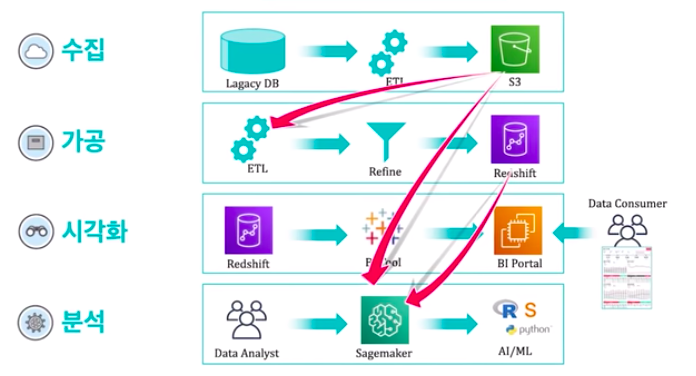
AWS는 데이터가 수집되는 시점부터 동작시킬 수 있는 수집, 저장, 처리, 모델링, 분석, 시각화로 이어지는 데이터 파이프라인을 구축할 수 있는 다양한 서비스들이 존재한다.
AWS 네트워크 기반 인프라 위에 데이터 흐름을 이어줄 수 있는 파이프라인을 만들고, 최종적으로 데이터 소비자가 시각화 서비스로 구성된 화면으로 데이터를 보거나 분석가들이 머신러닝으로 데이터를 분석해볼 수 있는 플랫폼을 의미한다.
AWS 기반 데이터레이크의 장/단점은?
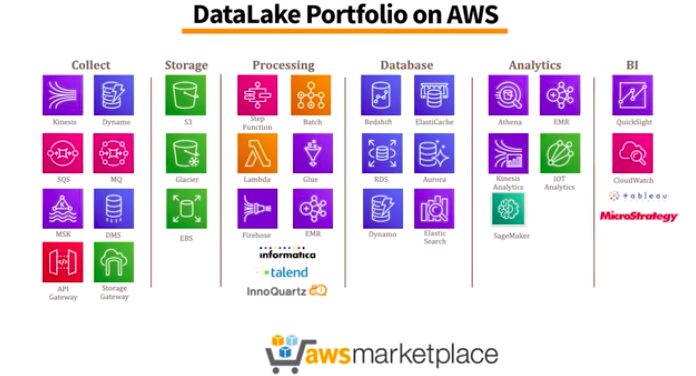
aws에서 데이터 관련 서비스를 다양하게 출시하고 있기 때문에, 활용 가능한지 기술 검증 밎 기존 시스템과의 조합을 고려해야 한다.
매년 새로운 서비스가 출시되면 그에 따른 학습도 필요하고, 적용 가능 여부를 판단하는 데에도 시간이 소요된다. 빠른 시간 안에 주어진 도큐먼트를 보면서 데이터레이크에 필요한 인프라는 빠르게 갖출 수는 있으나 데이터 연동, 권한 작업, 파이프라인 관리 등의 신경써야 하는 부분들이 있기 때문에 AWS cloud 시스템에 대한 이해와 숙련이 필요하다.
다음에는 아래 포스팅을 보면서 간단하게 직접 구현해보도록 하겠다.
참고 - https://heung-bae-lee.github.io/2020/02/22/data_engineering_07/
