빅데이터 분산처리 플랫폼
Apache Spark는 오픈소스이며, 범용적인 목적을 지닌 분산 클러스터 컴퓨팅 프레임워크으로 Fault Tolerance & Data Parallelism을 가지고 클러스터들을 프로그래밍할 수 있게 도와준다. Apache Spark에서는 RDD, Data Frame, Data Set의 3가지 API를 제공하는데, 이러한 데이터를 바탕으로 In-memory 연산을 가능하도록 하여 디스크 기반의 Hadoop에 비해 성능을 약 100배 정도 끌어올렸다.
기존에는 정형 데이터를 RDBMS를 사용하여
큐잉, 샤딩(Hash를 사용한 DB 분산 등의 방법으로 처리하였는데,
데이터가 급격하게 증대함에 따라 사진, 동영상 등을 포함하여
N TB/s 이상의 대용량의 다양한 데이터를 고속으로 처리해야 되는 환경에 직면하였다.
이를 효율적으로 처리하기위해 등장한 것이 "빅데이터 분산처리 플랫폼"이다.
빅데이터 처리 종류
- 초고속 병렬 처리
- 데이터 가공, 추출
- 데이터 분석 전처리
하둡(Hadoop)
빅데이터의 개념이 등장하였을 당시, 하둡 에코시스템이 시장을 지배하였다.
하둡은 HDFS(Hadoop Distributed File System)라고 불리는, 분산형 파일 시스템이다.
또한 데이터 처리 시, HDFS와 '맵리듀스'라고 불리는 대형 데이터셋 병렬 처리 방식으로 동작하는데,
하둡의 HDFS는 파일 기반의 디스크 입출력을 기반으로 하기 때문에, 실시간성 데이터 처리에는 속도 측면에서 문제가 발생했다.
스파크와 하둡
아파치 스파크는 인메모리상에서 동작하기 때문에,
반복적인 처리가 필요한 작업에서 속도가 하둡보다 최소 1000배 이상 빠르다.
이를 통해 데이터 실시간 스트리밍 처리라는 니즈를 충족함으로써, 빅데이터 프레임워크 시장을 차지하게 되었고,
많은 기업과 연구단체에서
하둡의 YARN 위에 스파크를 얻어서 실시간성이 필요한 데이터는 스파크로 처리하는 방식의 아키텍처를 선택하고 있다.
스파크의 구조
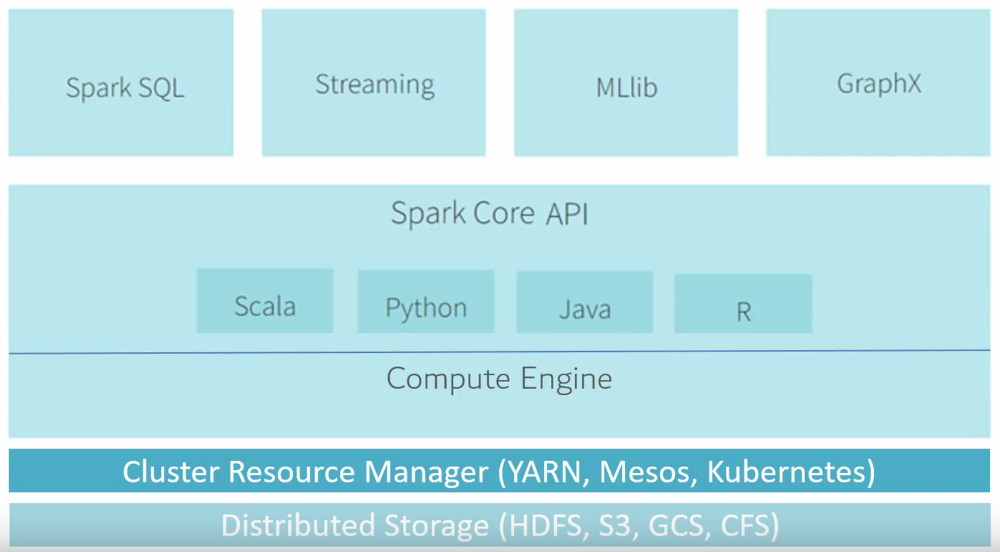
아파치 스파크는 기본적으로 Scala, JAVA, Python 등 다양한 언어 기반의 고수준 API를 지원한다.
또한 SQL 기능의 Spark SQL, 실시간 데이터 처리 기능의 Spark Streaming, 여러 머신러닝 기능을 지원하는 MLlib 등 다양한 라이브러리를 가지고 있다.
특히 MLlib는 최근 크게 각광받고 있어, 금융권 등 국내의 데이터 실시간 분석에서 스파크 비율이 압도적으로 높은 추세이다. 물론, Tensorflow/Pytorch 등을 활용한 딥러닝 정도의 퍼포먼스까지는 아니지만, 그래도 기계학습 분야에서는 충분한 퍼포먼스를 발휘하고 있다.
Apache Spark의 3가지 API
Apache Spark 1.x는 RDD를 아키텍처의 기반으로 하는데, RDD란 여러 클러스터에 distributed되어 있으며 fault-tolerant한 방식으로 유지되는 변경불가능한(read-only) 형태의 데이터 모음으로 low-level transformation and control을 원하는 경우에 사용한다. 또한 schema를 포함하지 않아도 무관한 경우에 사용하면 좋다.
[ Data Frame ]
Spark 1.3.x 부터는 named column으로 구성된 데이터의 분산 집합인 DataFrame이 등장하게 되었다. named column이라는 것은 스키마를 가진 RDD로, 관계형 데이터베이스의 테이블과 비슷하다. Data Frame부터는 Spark 내부에서 최적화를 할 수 있는 기능들이 추가되었다. 또한 기존 RDD에 스키마를 부여하고 질의나 API를 통해 데이터를 쉽게 처리할 수 있다.
[ DataSet ]
Spark 2.0부터는 DataFrame과 DataSet가 Dataset으로 병합되어 데이터 처리를 통합하고 있다. 내부 동작 방식에는 Catalyst Optimizer를 통해 실행 시점에 최적화된 코드를 제공하여, 언어에 무관하게 동일한 성능을 보장한다. 개념적으로 DataFrame은 DataSet[Row]로 간주되며, DataSet의 부분집합으로 불 수 있다.
DataSets는 strongly-typed API와 untyped API라는 2가지의 특성을 모두 사용한다. DataSet[Row] 에서 Row는 Generic이 사용된 Untyped 형태의 JVM 객체이며, DataFrame은 DataSet에서 Row를 기반으로 추출한 데이터들을 의미한다.
이러한 DataSet을 이용하면 다음과 같은 다양한 장점들을 누릴 수 있다.
1. Static-typing and runtime type-safety
Spark SQL을 통해 작성한 쿼리문의 경우에는 실행 전까지 syntax error를 잡아낼 수 없지만, Data Frame이나 DataSet을 사용하는 경우에는 complie-time에 이를 잡아낼 수 있다. 만약 우리가 DataFrame 또는 DataSet API의 일부가 아닌 함수를 호출한 경우에 컴파일 시점에 에러가 발생하만, 존재하지 않는 column name을 호출하는 것은 runtime 이전까지 감지할 수 없다.
또한 DataSet API는 모두 lambda 함수와 JVM 형태의 객체로 표현되기 때문에 지정된 매개변수가 불일치한 경우, 컴파일 시점에 잘못된 JVM Typed Object를 잡아낼 수 있으며 Analysis Error역시 발견될 수 있다. 이러한 DataSet의 경우 개발자에게는 제약이 많지만 생산성이 높다.
2. High-level abstraction and custom view into structured and semi-structured data
Datasets[Row]의 집합인 Dataset은 구조화된 custom view를 반구조화된 데이터 형태로 보여준다. 예를 들어, Json 형태의 경우 스키마를 포함하고 있어서, DataFrame으로 스키마 정보가 Binding된다. 아래와 같은 Iot deive의 event에 대한 json 형태의 dataset이 있다고 할 때, 이를 DeviceIotData라는 Custom-Object로 만들 수 있다.
{"device_id": 198164, "device_name": "sensor-pad-198164owomcJZ", "ip": "80.55.20.25", "cca2": "PL",
"cca3": "POL", "cn": "Poland", "latitude": 53.080000, "longitude": 18.620000, "scale": "Celsius",
"temp": 21, "humidity": 65, "battery_level": 8, "c02_level": 1408, "lcd": "red", "timestamp" :1458081226051}
case class DeviceIoTData (battery_level: Long, c02_level: Long, cca2: String, cca3: String, cn: String, device_id: Long, device_name: String, humidity: Long, ip: String, latitude: Double, lcd: String, longitude: Double, scale:String, temp: Long, timestamp: Long)3. Ease-of-use of APIs with Structure
Dataset은 높은 수준의 API로 사용가능하며, Dataset의 유형 객체에 직접 엑세스하여 agg, select, sum, avg, map, filter, groupby 등의 작업을 수행할 수 있다.
4. Performance and Optimization
DataSet API를 사용하는 모든 이점중에서도 Performance 와 Space Efficiency를 고려하지 않을 수 없다. Dataset도 DataFrame과 마찬가지로 Spark SQL Engine위에서 만들어졌는데, Catalyst Optimizer를 통해 실행 시점에 코드 최적화를 하여 성능을 향상시켜준다.
