MySQL
MySQL은 Oracle에서 제공하는 오픈 소스 관계형 데이터베이스 관리 시스템으로, SQL 쿼리를 사용하는 관계형 데이터베이스 프로그램 중 가장 널리 사용되고 있다. 웹사이트와 애플리케이션의 데이터 저장소 역할을 한다. 트랜잭션, 보기, 저장 프로시저 및 트리거를 비롯한 다양한 기능과 다양한 스토리지 엔진을 지원하며 다양한 운영체제와 프로그래밍 언어에 통합될 수 있다는 장점이 있다.
MySQL 구성도와 query 실행 과정
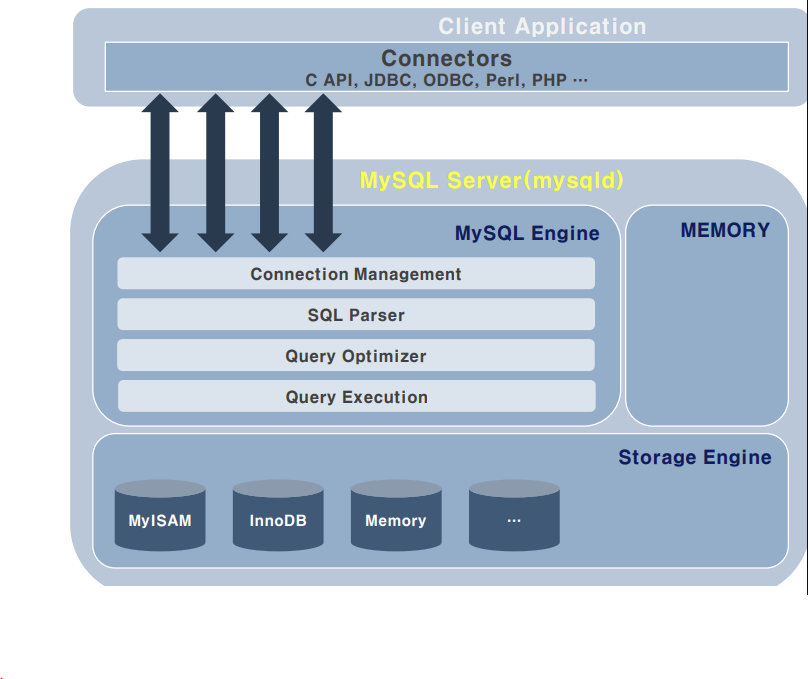
- SQL 파싱: SQL 파서라는 모듈이 SQL query 문장을 잘게 쪼개서 mysql 서버가 이해할 수 있는 수준으로 분리한다. 잘못된 문법을 가지고 있다면 여기서 걸러지며, 올바른 문장의 경우에 잘 처리되어 결과로 파싱 트리가 나온다.
- 최적화 및 실행계획 수립: mysql 서버의 옵티마이저가 SQL 파싱 트리를 확인하면서 어떤 테이블부터 읽고 어떤 인덱스를 이용해 읽을지 선택하여 실행계획을 수립한다.
- 스토리지 엔진으로부터 데이터 가져오기: 앞의 실행계획을 기반으로 스토리지 엔진으로부터 데이터를 로드해온다. 또한 mysql 엔진에서도 받은 레코드를 조인하거나 정렬하는 작업을 수행한다.
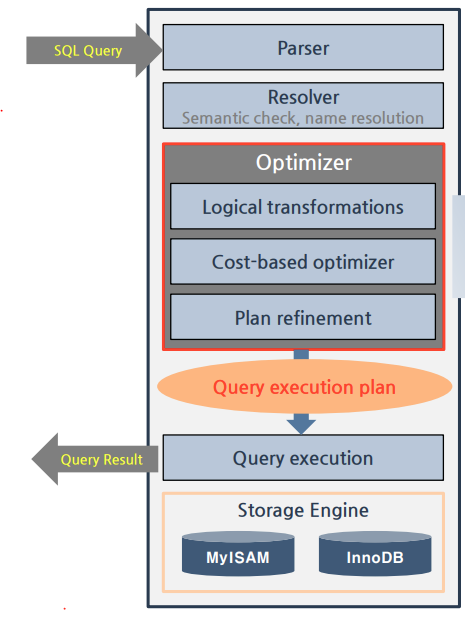
옵티마이저와 실행 계획
옵티마이저란 최적화 장치로, 쿼리의 실행계획을 수립하는 mysql 엔진의 모듈이다. 아래의 3단계가 있다.
- Logical transformations: 쿼리의 논리적 구조를 분석하고 효율적으로 처리하기 위해 쿼리를 변환한다. 여기서 쿼리의 조건을 단순화하고 필요한 연산의 순서를 최적화하게 된다.
- where절 변환: 부정 조건을 변환, 상수/동일값 대입, 상수 조건 평가, trivial(항상 true) 조건 제거
- outer join을 가능하면 inner join으로 변환
- view/derived table 병합
- subquery 변환
- cost-based optimizer: 가능한 모든 실행계획을 생성하고 쿼리의 논리적 구조와 테이블 및 인덱스의 통계정보를 기반으로 해서 각 계획의 비용을 추정한다.
- 인덱스 및 access 방법과 조인 순서를 결정한다.
- 조인버퍼 전략, 서브쿼리 전략을 결정한다.
- 통계정보: cost base optimizer가 실행 계획을 세울 때 참조하는 스키마 관련 정보로, 테이블 예상 건수, 테이블/인덱스 공간의 크기, 칼럼의 distinct value 개수(카디널리티) 및 컬럼 분포도 등을 포함한다.
- Plan refinement: 조인 순서, 실행계획 중 비용을 최소화하는 최적의 계획을 선택한다.
- 조인순서에서 가능한 빠르게 조인조건을 할당한다.
- ORDER By optimizer
- access 방법 변경
- index condition pushdown
key
데이터베이스에서 key의 의미는 테이블에서 각 데이터를 분류하는 기준의 역할을 한다. 키의 종류를 하나씩 살펴보겠다.
1. key(Index)
가장 일반적인 key는 index로 데이터베이스의 각 데이터 색인을 의미한다. 중복과 null 모두 허용하지만 null은 비약적인 성능 저하를 가져오므로 인덱싱하지 않도록 한다.
2. Primary key
일반적인 key는 인덱스를 지칭하지만 DB 설계에서의 key는 보통 pk를 의미한다. NOT NULL & UNIQUE 옵션이 포함되며 하나 이상의 칼럼이 될수 있다. 만약 한 개의 칼럼으로 지정되어 있다면 그 칼럼의 데이터는 유일성이 보장되고, 여러개가 Pk로 지정되어 있다면, 그 key들의 조합에 대해 유일성이 보장된다. 검색 시에 색인 key가 되고 다른 테이블과 조인할 때도 기준 값으로 사용된다.
3. Unique key
pk와 마찬가지로 중복성이 허용되지 않는 Uniqueness한 인덱스를 말하며, null에 대한 허용이 가능하다.
4. Foreign key
Foreign Key 란 JOIN 등으로 다른 DB 와의 Relation 을 맺는 경우, 다른 테이블의 PK를 참조하는 Column 을 FK 라고 한다. 여기서 Foreign Key Relation 을 맺는 다는 의미는 논리적 뿐 아니라 물리적으로 다른 테이블과의 연결까지 맺는 경우를 말하며, 이 때 FK 는 제약조건(Constraint)으로의 역할을 한다. Foreign Key Restrict 옵션을 줄 수 있고 다음과 같은 옵션들이 있다.
- RESTRICT : FK 관계를 맺고 있는 데이터 ROW 의 변경(UPDATE) 또는 삭제(DELETE) 를 막는다.
- CASCADE : FK 관계를 맺을 때 가장 흔하게 접할 수 있는 옵션으로, FK 와 관계를 맺은 상대 PK 를 직접 연결해서 DELETE 또는 UPDATE 시, 상대 Key 값도 삭제 또는 갱신시킨다. 이 때에는 Trigger 가 발생하지 않으니 주의하자.
- SET NULL : 논리적 관계상 부모의 테이블, 즉 참조되는 테이블의 값이 변경 또는 삭제될 때 자식 테이블의 값을 NULL 로 만든다. UPDATE 쿼리로 인해 SET NULL 이 허용된 경우에만 동작한다.
- NO ACTION : RESTRICT 옵션과 동작이 같지만, 체크를 뒤로 미룬다.
- SET DEFAULT : 변경 또는 삭제 시에 값을 DEFAULT 값으로 세팅한다.
뷰
가상 테이블로, 다양한 query로 만들어진 데이터를 편리하고 빠르게 보여주고 액세스할 수 있도록 한다. 실제로 데이터를 저장하는 테이블이 아닌, 보여주는 데에 중점을 둔 기능이지만 뷰의 데이터를 수정할 경우 실제 데이터도 바꿔며, 실제 데이터를 수정하는 경우에는 뷰에도 반영된다. 사용법은 아래와 같다.
CREATE VIEW name AS
SELECT column1, column2, ... FROM table_name 조건문;
CREATE VIEW seoul_members AS
SELECT LastName, FirstName, Address, City, Country FROM members where City = '서울';
DROP VIEW seoul_members;
트랜잭션
트랜잭션은 데이터베이스 상태를 바꾸는 일종의 작업 단위다. MySQL의 모든 명령어들은 각각 하나의 트랜잭션이라고 볼 수 있으며, INSERT, DELETE, UPDATE 등의 명령문을 통해 데이터 상태를 바굴 때마다 자동적으로 commit을 해서 변경된 내용을 데이터베이스에 반영하는 작업이 진행된다.
여기서 자동 commit이 아닌 수동으로 한 트랜잭션 안에 여러 개의 명령문을 넣어 동시에 처리될 수 있도록 할 수 있다. 먼저 아래 명령어를 통해 트랜잭션을 실행한다.
START TRANSACTION;그리고 원하는 기능의 명령어를 작성한 뒤에 아래의 commit 명령어를 통해 한번에 적용시킬 수 있다.
COMMIT;만약 트랜잭션의 내용을 실제 데이터베이스에 적용시키고 싶지 않다면 아래의 rollback 명령어를 사용하면 된다. 여기서 주의할 점은 drop, alter table 명령어는 롤백 기능을 지원하지 않는다는 것이다.
ROLLBACK;프로시저
프로시저는 MySQL에서 함수를 정의하는 것이라고 보면 된다. 함수처럼 매개변수를 받고 거기에 맞는 결과를 나타내는 것이 가능하다. 즉 sql의 명령의 묶음으로 복수의 쿼리를 실행하는데 있어서 중간 쿼리들의 오류를 방지하기 위해 일괄 처리하도록 하는 기능이다. 프로시저는 하나의 쿼리로 해석하기 떄문에 처리 속도가 빠르고 네트워크 부하도 줄일 수 있다. 기본적인 프로시저 등록의 방식은 아래와 같다.
DELIMITER //
CREATE PROCEDURE mem()
BEGIN
select * from members;
END
//
DELIMITER;여기서 delimiter는 구분문자를 바꿔주는 것으로 함수 선언 전에 ;에서 //로 바꿔준 뒤, 함수 선언 이후 다시 ;로 바꿔줘야 프로시저 등록하는 과정에서 에러가 발생하지 않는다. 프로시저 사용법과 삭제법은 다음과 같다.
call mem;
DROP PROCEDURE mem;트리거(Trigger)
트리거란 특정 조건이 만족하면 저절로 실행되는 일종의 장치로 한번 설정해놓으면 계속 동작을 감시하고 있다가, 조건에 해당하는 동작이 수행되는 순간 실행된다. 기본 구조는 다음과 같다.
DELIMITER //
CREATE TRIGGER trigger_name
{BEFORE|AFTER} {INSERT|UPDATE|DELETE}
ON table_name FOR EACH ROW
BEGIN
--- 트리거 내용
END
DELIMITER ;여기서 BEFORE 혹은 AFTER는 트리거 작동 시점을 의미하며, 그 뒤에 조건 이벤트가 들어간다. 아래의 예시에서는 members 테이블이 있고, 그 테이블에서 데이터를 지울 때, 백업 테이블인 members_backup에 저장하는 트리거를 만든 것이다.
DELIMITER //
CREATE TRIGGER backup_memger BEFORE DELETE
ON members FOR EACH ROW
BEGIN
INSERT INTO members_backup (columns)
VALUES (value1, value2, ..);
END;
//
DELIMITER ;트리거 목록을 출력해서 확인하거나 삭제하는 방법은 아래와 같다.
SHOW TRIGGERS;
DROP TRIGGER trigger_name;