BERT 개념
1.BERT 개념
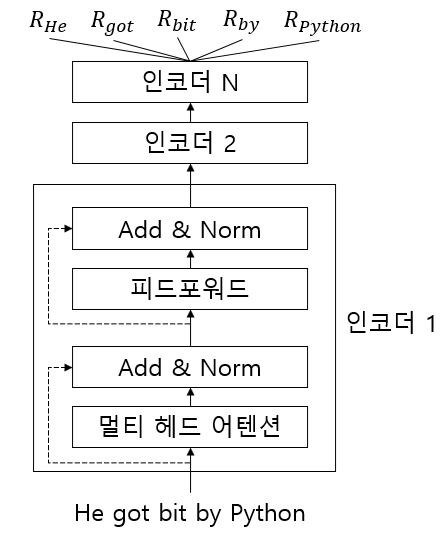
BERT(Bidirectional Encoder Representation from Transformer)는 구글에서 발표한 임베딩 모델이다. 질문에 대한 대답, 텍스트 생성, 문장 분류 등과 같은 태스크에서 가장 좋은 성능을 도출해 자연어 처리 분야에 크게 기여해왔다
2022년 4월 19일
2.ALBERT 개념

BERT의 문제점 중 하나는 수백만 개의 변수로 구성되어있다. BERT-base 같은 경우 약 1억개의 변수로 구성되어 있어 모델 학습이 어렵고 추론 시 시간이 많이 걸린다.ALBERT는 두 가지 방법을 사용해 BERT와 대비해 변수를 적게 사용한다.크로스 레이어 변수
2022년 4월 20일
3.RoBERTa 개념
RoBERTa는 기본적으로 BERT와 동일하고 사전 학습 시 다음의 항목을 변경하였다.MLM 태스크에서 정적 마스킹이 아닌 동적 마스킹 방법을 적용NSP 태스크를 제거하고 MLM 태스크만 학습에 사용배치 크기를 증가해 학습토크나이저로 BBPE(byte-level BPE
2022년 4월 20일
4.knowledge distillation

지식 증류의 개념을 공부해 보았다.
2022년 9월 2일