요약
이 논문에서는 요약에 중점을 둔 다중 문서 표현을 위해 사전 학습된 훈련모델인 PRIMERA를 소개한다. PRIMERA는 문서의 정보를 연결하고 집계하여 인코더-디코더 트랜스포머를 사용하여 문서들의 입력 처리를 단순화하였다.
LED 모델
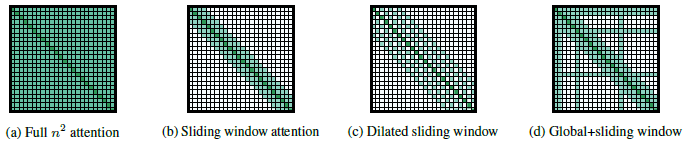
self-attention에서 인풋 시퀀스 길이가 길어지면 (a)와 같이 제곱에 비례해서 메모리와 계산량이 늘어나게된다. LED 모델은 이러한 부분을 줄이기 위해 (b), (c), (d) 와 같은 형태로 계산하는 방법을 제안함으로써 입력 시퀀스 길이를 길게 하면서 일반 self-attention의 메모리와 계산량 문제점을 어느정도 해소했다.
모델 아키텍처

위 사진은 논문에서 제안한 모델로써 기본적으로 LED(Longformer Encoder Decoder) 모델 기반으로 구성되어있다. 각 documents는 토큰 기준으로 나뉘며 글로벌 어텐션과 로컬 어텐션으로 document 의 내용과 각 documents의 내용을 학습한다.
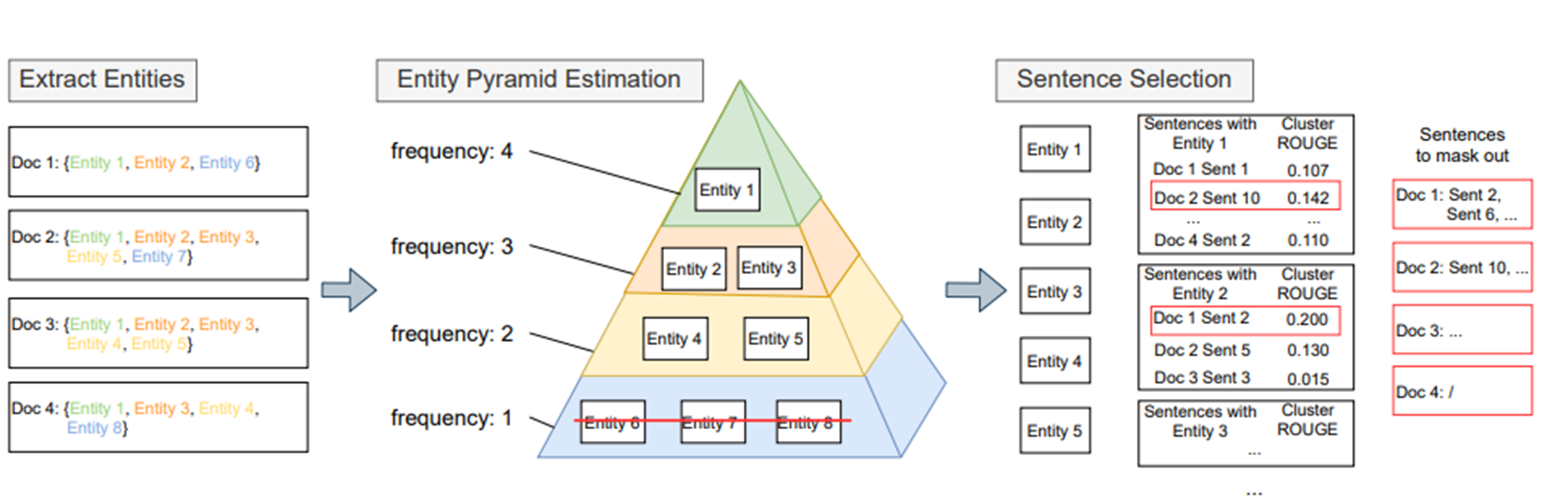
위 그림은 입력 시퀀스에서 [sent mask]를 뽑는 기준을 보여준다. 각 document 별로 Named entity를 뽑아 빈번도를 정리한다. 각 Named entity 별로 모든 documents 기준으로 ROUGE-1, ROUGE-2, ROUGE-L 점수를 계산하여 평균을 내어 CLUSTER ROUGE 점수를 계산한다. 각 계산된 점수를 기준으로 Named Entity의 빈번도가 가장 높은 순으로 Document 안에 해당 Named Entity의 CLUSTER ROUGE 점수가 높은 문장을 마스킹한다.
성능

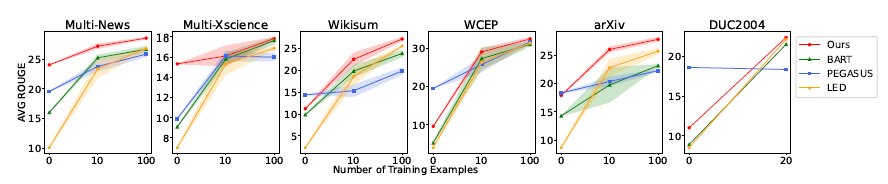
위 사진과 같이 뛰어난 성능이 높게 나오는것을 볼 수 있다.
느낀점
다중 문서 요약 부분에서 한글 데이터셋을 찾을 수 없어서 직접 만들어야하는대 같은 문서를 일일히 찾는게 쉽지 않았다. 문서 데이터셋을 클러스터링하여 Named Entity를 추출하여 마스킹하는 기법을 적용하면 쉽게 데이터셋을 만들 수 있다고 생각했다. 실제로 뉴스 데이터를 크롤링하여 테스트한 결과 핵심적인 내용이 마스킹된 것 을 확인할 수 있었다. 추후 실제 모델로 학습을 해볼 예정이다.
