요약은 크게 두 가지로 분류된다. 하나는 추출적 요약이고 하나는 추상적 요약이다. 추출적 요약은 원문 텍스트에서 주요 문장을 그대로 가져오는 방식이라면, 추상적 요약은 원문 텍스트를 보고 한 줄로 요약하듯이 표현하는 방식이다.
PEGASUS에서는 추상적 요약 모델로써 긴 문단들에 대한 이해, 정보 압축, 언어 생성을 통해 요약을 한다. 이러한 목적으로 머신 러닝 모델을 훈련시킬 때 가장 많이 사용되는 패러다임은 신경망이 인풋 시퀀스와 아웃풋 시퀀스를 연결하는 시퀀스-투-시퀀스(seq2seq) 방식이다. 최근에는 트랜트포머 인코더-디코더 모델들이 많이 사용되고 있다.
자기지도학습 사전 훈련과 결합된 트랜스포머 모델들(BERT, GPT-2, ELECTRA 등등)은 언어 학습 전반에서 좋은 성능을 보여줬고, 파인 튜닝될 경우 sota의 성능을 보여 주고 있다. PEGASUS에서는 사전 훈련이 전반적인 학습에 중점을 두었기 때문에, 태스크에 대해 적용할 때 연관이 어렵다고 생각하여 최종적인 태스크와 더 가까운 목적으로 자기지도학습을 진행하는 것이 더 좋은 성능을 가져오지 않을까라는 생각을 통해 탄생했다.
“PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization” 에서는 트랜스포머 인코더-디코더 모델을 위한 자기지도학습 사전 훈련을 빈 문장 생성(gap-sentence generation)을 통해 학습하였다.
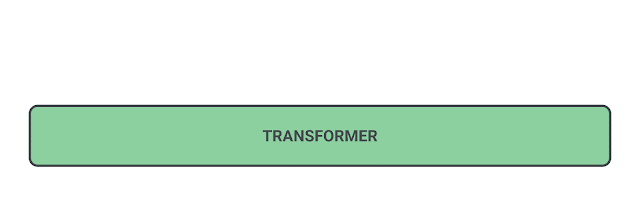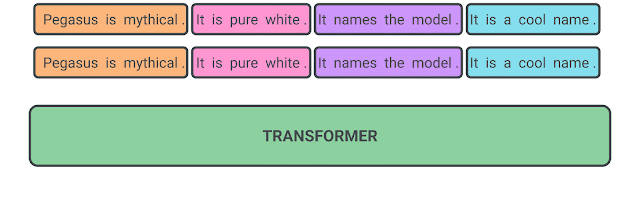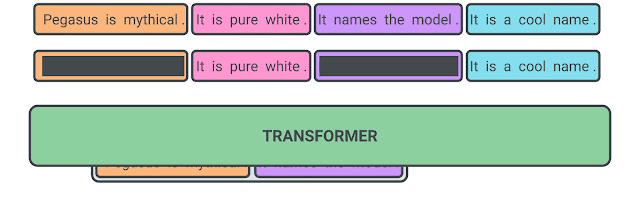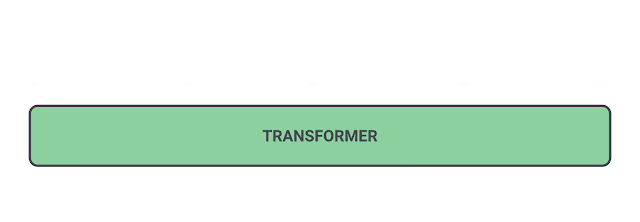
PEGASUS의 사전학습은 문장들 중에서 몇 개를 제거하고 모델은 제거된 문장을 예측하는 태스크이다. 몇 개의 문장을 마스킹한 입력을 넣어 출력에는 마스킹된 문장들이 합쳐진 형태로 나와야 한다. 이때 마스킹된 문장들이 전체 문맥에서 중요한 문장일수록 출력이 요약에 가까워지며 모델의 성능도 향상된다.
reference
