카운팅 정렬 (Counting Sort)
배열 내 항목들의 순서를 결정하기 위해 각 항목이 몇 개씩 있는지 세는 작업을 하여 선형 시간에 정렬하는 효율적인 알고리즘
제한 사항
- 정수나 정수로 표현할 수 있는 자료에 대해서만 적용 가능, 각 항목의 발생 회수를 기록하기 위해 정수 항목으로 인덱싱 되는 배열을 사용하기 때문
- 각 항목을 카운트 하기 위한 충분한 공간을 할당하려면 배열 내 가장 큰 정수를 알아야 한다.
- 시간 복잡도
- O(n+k) : n은 배열의 크기, k는 배열 내 정수의 최대값
예시
# 오름차순으로 정렬
[0, 4, 1, 3, 1, 2, 4, 1]- 0부터 Data의 최대값의 길이를 크기로 하는 counts 배열을 만드는데, counts의 각 원소의 값은 인덱스에 해당하는 원소가 Data에 얼마나 존재하는지 나타내준다.
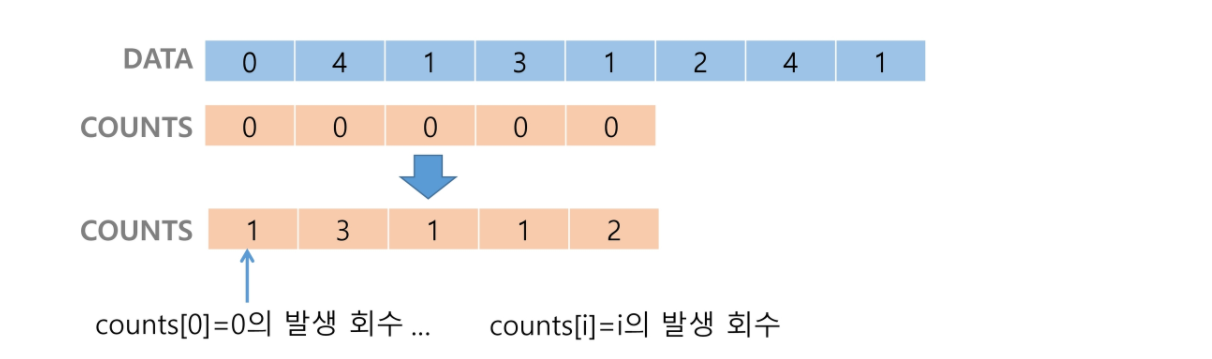
- 정렬된 집합에서 각 항목의 앞에 위치할 항목의 개수를 반영하기 위해 counts의 원소를 누적합으로 조정한다.
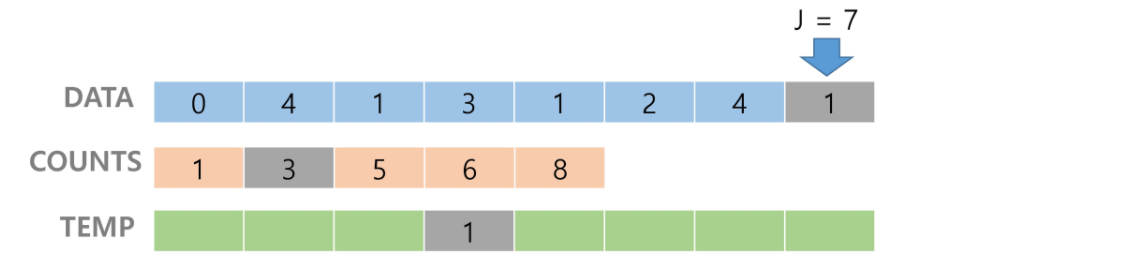
- 숫자를 정렬시켜 놓을 리스트 tmp를 만들고 Data의 맨 오른쪽부터 값을 하나씩 뽑은 후 이를 인덱스로 하는 counts의 값을 다시 tmp 인덱스에 넣고, 해당 값을 Data에서 뽑은 값으로 준다.
코드로 구현
Data = [0, 4, 1, 3, 1, 2, 4, 1]
counts = [0] * (max(Data)+1)
tmp = [0] * len(Data) # Data를 오름차순 시킨 배열
# Data 내 원소들의 출현 회수를 counts에 담고, 인덱스로 확인
for num in Data:
counts[num] += 1
# counts의 원소는 각 인덱스의 횟수를 담고 있는데, 이를 누적합으로 바꿈
for i in range(1, len(counts)):
counts[i] += counts[i-1]
# 1. Data의 맨 오른쪽부터 값을 뽑고(Data[i]),
# 2. 이를 인덱스로 하는 counts의 값을 다시 tmp의 인덱스로 넣고 tmp[counts[Data[i]]]
# 3. 해당 값을 Data[i]로 준다. tmp[counts[Data[i]]] = Data[i]
for i in range(len(Data)-1, -1, -1):
tmp[counts[Data[i]]-1] = Data[i]
counts[Data[i]] -= 1
print(tmp)