이번 포스팅에서는 파이썬을 활용하여 영화 API를 사용하는 방법에 대해 적어볼 예정이다.
TMDB에는 현재 상영중인 영화, 평점이 높은 영화 등 영화 상세정보에 대한 데이터를 API를 통해 얻을 수 있다.
API 키 발급
- 회원가입을 한 후
설정->API에서 API 키를 요청해야 한다.- 공공데이터에서 제공받는 경우 키 없이 사용 가능한 경우도 있지만, 대부분 오래전에 데이터들이 많다.
- 보통 실질적으로 필요한 데이터를 얻기 위해서는 사이트에서 제공하는 키를 요청하고 받아야한다. 아무래도 계속해서 많은 데이터를 요청하면 서버에도 부담(?) 혹은 해킹(?)이라고 생각될 수 있기 때문에 키를 발급 받는 것 같다.
Developer선택 및 약관 동의 후 키 발급 요청을 진행한다.- 이용형태 : 웹사이트
- 어플리케이션 이름 : 자유롭게
- 어플리케이션 URL : http://localhost:8080
- 어플리케이션 개요 : 점만 찍거나 간략하게 작성하면 신청이 반려되기 때문에 자세하게!
- 나머지: 주소, 이름 등 자유롭게 작성해야 하지만, 거짓 없이 잘 작성해야 이용 가능한 것 같다.
- 위 과정을 완료하면 API 키를 발급 받을 수 있고, 이후 데이터를 요청하기 위해 TMDB API 를 들어가면 TBDM에서 제공하는 여러 데이터들과 데이터를 요청하는 방법에 대해 상세하게 나와 있다. 따라서 원하는 데이터 항목에 들어가서 필요한 요소들과 URL을 체크하면 된다.
ex) 추천 영화 데이터 요청
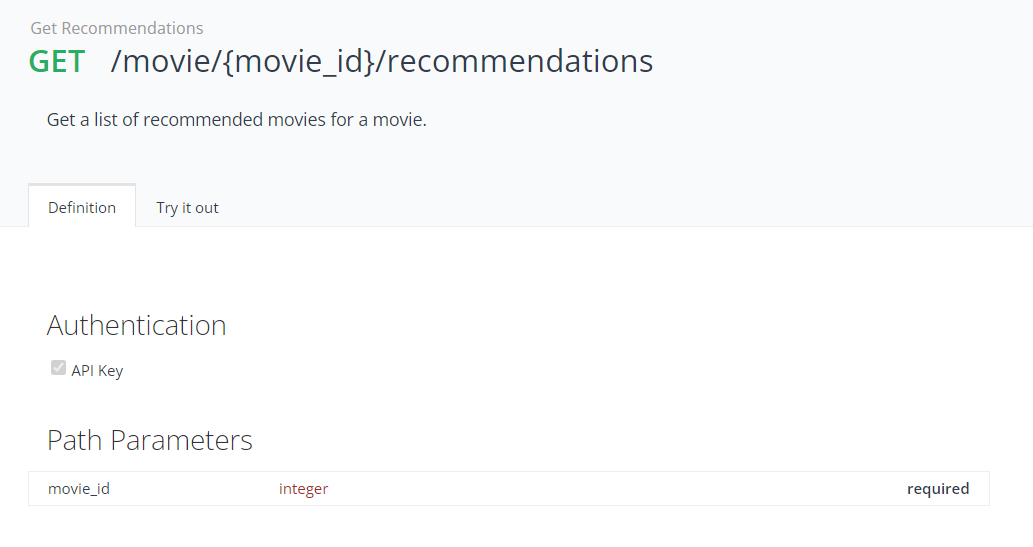
- 해당 API는 GET 방식을 통해 데이터를 요청하는 것을 알 수 있다.
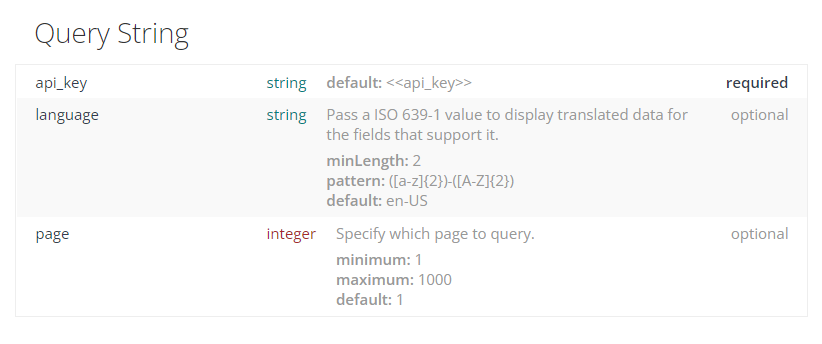
- GET 방식으로 HTTP 요청을 할 때는 쿼리 스트링(query string)을 통해 응답받을 데이터를 필터링 하는 경우가 많기 때문에
params옵션을 사용하여 쿼리 스트링을 딕셔너리 형태로 넘겨야 한다.
파이썬(request)으로 API 요청
requests 라이브러리는 일반적으로 파이썬을 통해 HTTP 호출을 할 때 거의 표준으로 사용하는 라이브러리이다.
requests 패키지 설치 후 확인
# 내장 모듈이 아니기 때문에 설치해 주어야 한다.
$ pip install requests
# 설치 후 호출
import requests
# 예를 들어 https://www.google.co.kr/을 호출한다고 했을 때
url = 'https://www.google.co.kr/'
requests.get(url)
<Response [200]>
requests를 통해 구글을 호출했고 상태 코드인 200을 반환하면 응답이 되는 것으로 볼 수 있다. 요청 방식
requests는 HTTP 요청의 다양한 방식을 제공하고 있고 해당하는 이름의 함수를 사용하면 된다.
-
requests.get(): Get 방식 -
requests.post(): Post 방식 -
requests.delete(): Delete 방식 -
requests.put(): Put 방식
응답 상태
-
response.status_doe를 통해 HTTP 호출한 상태를 확인할 수 있다.
-
200번대: 우리가 요청한 동작을 서버에서 승낙했고 성공적으로 처리한 것
-
400번대: 우리가 잘못한 것
-
500번대: 서버가 유요한 요청을 수행하지 못한 서버 오류, 개발자 잘못
url = 'https://www.google.co.kr/'
response = requests.get(url)
response.text
=> UTF-8로 인코딩된 문자열을 반환
response.json()
=> 응답 데이터가 JSON 포멧일 때 json() 함수를 통해 딕셔너리 객체를 얻을 수 있음인기 영화 데이터 요청
간단하게 TMDB 에서 제공하는 인기 영화 데이터를 요청하고 받아보려고 한다.
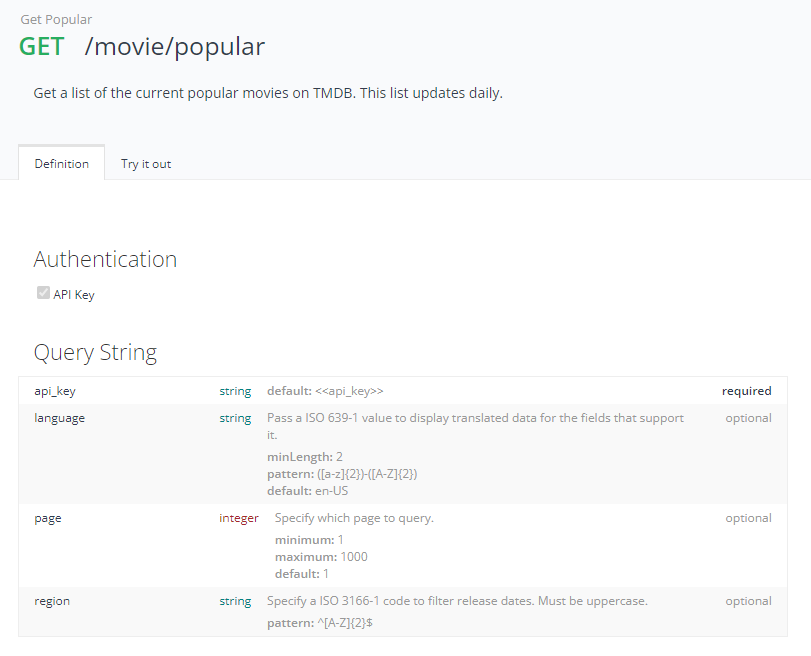
- 위의 설명을 보고 URL, 쿼리 스트링에 대한 정보를 먼저 확인해야 한다.
import requests
# requests.get(이 안에는 url이 들어가야 한다)
Base_Url = 'https://api.themoviedb.org/3'
path = '/movie/popular'
# 쿼리스트링을 입력 할 때 params를 이용한다.
params = {
'api_key': '각자 고유의 api 키', # required
'region': 'KR', # optional
'language': 'ko' # optional
}
response = requests.get(Base_Url+path, params=params)
response
<Response [200]>- 해당 데이터를 JSON 형식으로 제공하고 있기 때문에 json() 메소드를 사용하여 데이터를 json 형태로 확인할 수 있다.
# key를 확인했을 때 page, results, total_pages, total_results 4가지 키가 존재한다.
response.json().keys()
=> dict_keys(['page', 'results', 'total_pages', 'total_results'])
# 첫번째 인기 영화를 확인하면 아래와 같은 데이터를 받을 수 있다.
response.json()['results'][0]
{'adult': False,
'backdrop_path': '/iQFcwSGbZXMkeyKrxbPnwnRo5fl.jpg',
'genre_ids': [28, 12, 878],
'id': 634649,
'original_language': 'en',
'original_title': 'Spider-Man: No Way Home',
'overview': '정체가 탄로난 스파이더맨 피터 파커가 시간을 되돌리기 위해 닥터 스트레인지의 도움을 받던 중 뜻하지 않게 멀티버스가 열리게 되고, 이를 통해 자신의 숙적 닥터 옥토퍼스가 나타나며 사상 최악의 위기를 맞게 되는데...',
'popularity': 15424.687,
'poster_path': '/voddFVdjUoAtfoZZp2RUmuZILDI.jpg',
'release_date': '2021-12-15',
'title': '스파이더맨: 노 웨이 홈',
'video': False,
'vote_average': 8.4,
'vote_count': 7014}영화 탐색
- 이어서 내가 찾고 싶은 영화를 입력했을 때 해당 영화에 대한 정보를 받아보려 한다.
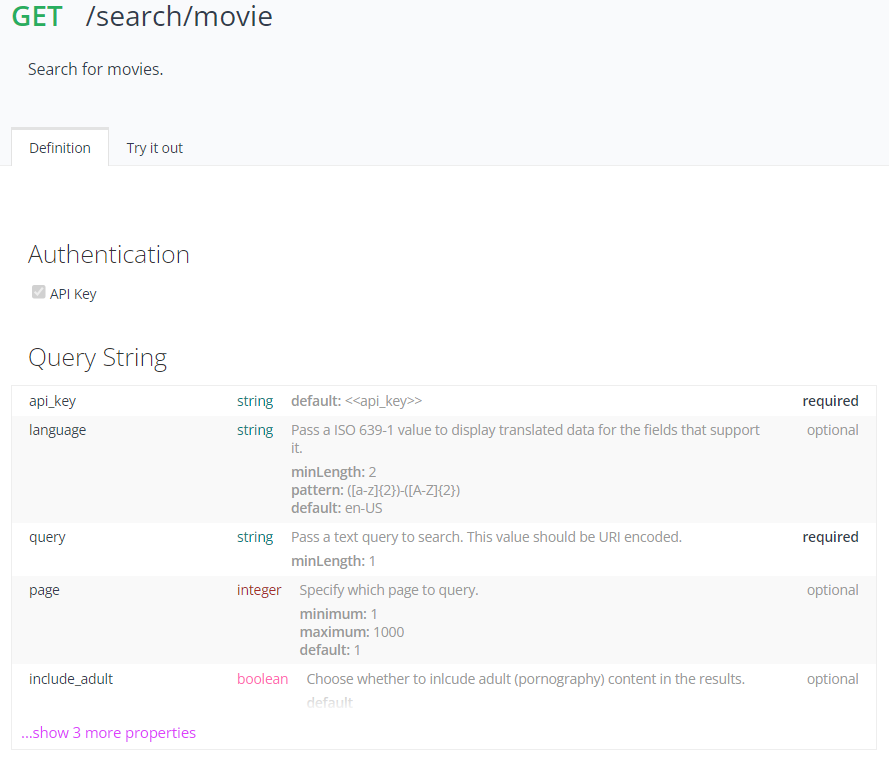
- 여기서는 찾고 싶은 영화를 쿼리 스트링의
query값으로 필수적으로 입력해주어야 한다.
import requests
# requests.get(이 안에는 url이 들어가야 한다)
Base_Url = 'https://api.themoviedb.org/3'
path = '/search/movie'
# 쿼리스트링을 입력 할 때 params를 이용한다.
params = {
'api_key': '각자 고유의 api 키', # required
'region': 'KR', # optional
'language': 'ko', # optional
'query' : '기생충' # required
}
response = requests.get(Base_Url + path, params = params).json()
response- 이 코드를 실행하면 params의
query의 값으로 입력했던 기생충 영화에 대한 정보를 가져올 수 있다.
{'page': 1,
'results': [{'adult': False,
'backdrop_path': '/TU9NIjwzjoKPwQHoHshkFcQUCG.jpg',
'genre_ids': [35, 53, 18],
'id': 496243,
'original_language': 'ko',
'original_title': '기생충',
'overview': '전원 백수로 살 길 막막하지만 사이는 좋은 기택 가족. 장남 기우에게 명문대생 친구가 연결시켜 준 고액 과외 자리는 모처럼 싹튼 고정수입의 희망이다. 온 가족의 도움과 기대 속에 박 사장 집으로 향하는 기우. 글로벌 IT기업의 CEO인 박 사장의 저택에 도착하자 젊고 아름다운 사모님 연교와 가정부 문광이 기우를 맞이한다. 큰 문제 없이 박 사장의 딸 다혜의 과외를 시작한 기우. 그러나 이렇게 시작된 두 가족의 만남 뒤로, 걷잡을 수 없는 사건이 기다리고 있는데.....',
'popularity': 116.346,
'poster_path': '/jjHccoFjbqlfr4VGLVLT7yek0Xn.jpg',
'release_date': '2019-05-30',
'title': '기생충',
'video': False,
'vote_average': 8.5,
'vote_count': 13061}],
'total_pages': 1,
'total_results': 1}