자료구조 중에 하나인 List중에서 ArrayList를 직접 구현해보려고 한다.
간단하게 개념만 짚고 넘어가자
List는 기존의 배열의 문제점을 해결하기 위한 자료구조이다.
기존의 배열은 메모리에 공간을 얼마나 차지할 지 선언을 해줘야 사용이 가능하다.
public static void main(String[] args) {
Object[] object = new Object[]; // 배열의 크기를 선언 안했기 때문에 오류
Object[] object = new Object[6]; // 배열의 크기를 직접 선언
}
근데 예를 들어서 크기가 6인 배열에 데이터 3개를 넣는다고 하자.
public static void main(String[] args) {
Object[] object = new Object[6];
object[0] = 10; // 인덱스 0번째 자리에 10 추가
object[1] = 20; // 인덱스 1번째 자리에 20 추가
object[2] = 30; // 인덱스 2번째 자리에 30 추가
}그러면 선언한 배열의 크기는 6인데 데이터를 3개 넣었으면 그 배열은 메모리를 3개만 사용하는 걸까? 아니다. 다음 그림과 같이 데이터가 담긴다.

나머지 공간에 데이터가 안담긴다고 해서 메모리 사용까지 안하는건 아니고, 처음부터 크기를 6으로 선언했기에 메모리상에는 데이터크기가 6인 배열이 생성된 것이다.
그렇다면 데이터가 안담긴 나머지 공간은 낭비가 되지 않는가? 그걸 보완하기 위해 나온게 List 자료구조형이다. List자료형에는 ArrayList형이랑 LinkedList가 있는데 그 중에서 ArrayList를 알아보기 위해 자바의 Collection 중에 ArrayList를 사용해서 데이터를 넣어보자.
public static void main(String[] args) {
ArrayList object = new ArrayList();
//크기를 선언 안해줘도 괜찮음, 데이터가 하나 들어갈때 마다 데이터 크기가 늘어나는 구조
object.add(10);
object.add(20);
object.add(30);
}이러면 그 과정을 알아보자
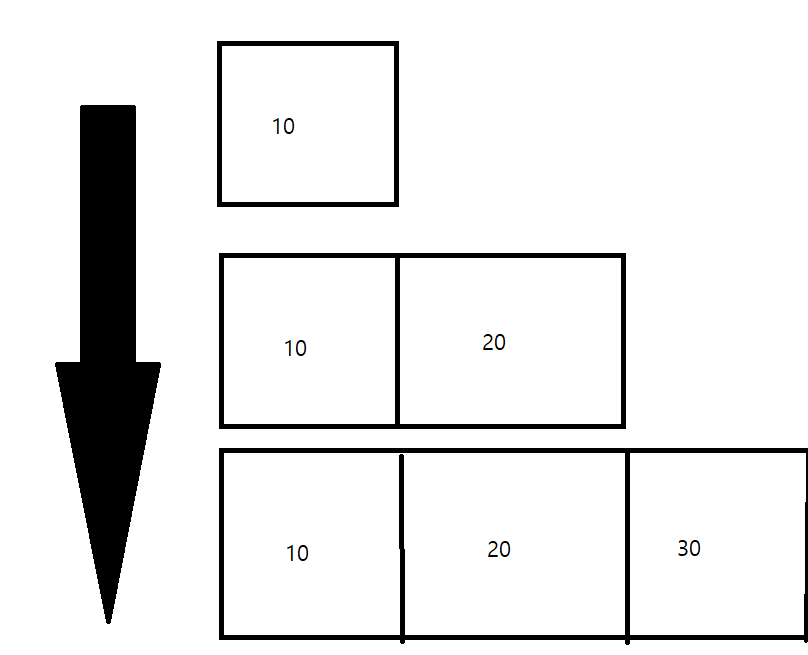
데이터가 들어 올 때마다 크기가 하나씩 늘어 나는것을 볼 수 있다.
배열과 리스트의 차이를 한눈에 볼 수 있는 그림을 보자.
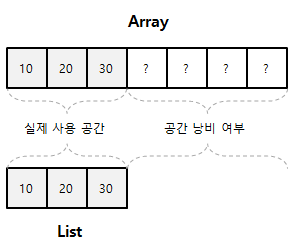
이런식으로 배열의 공간낭비 부분을 리스트는 가지고 있지 않다. 따라서 배열은 메모리 사용이 재사용이 불가능하지만 리스트는 데이터를 삭제하거나 등의 행동을 통해서 메모리 반환을 하기 때문에 메모리 재사용이 가능하다.
그렇다면 ArrayList가 배열의 업그레이드 버전이라는데 그렇다면 배열로 ArrayList를 구현할 수 있지않을까 ? 맞다. 가능하다. ArrayList형태를 직접 구현을 하면서 장점과 단점을 알아보자.
ArrayList 직접 구현하기
public static void main(String[] args) {
ArrayList object = new ArrayList(); //임의로 배열을 만들것이다.
}main 함수에 ArrayList의 인스턴스를 선언했으니 ArrayList클래스를 구현해보자.
public class ArrayList {
private int size = 0;
private Object[] elementData = new Object[100];
}
- 먼저 자료가 저장되고 읽고, 삭제되는 과정을 알기 위한 예제이므로 데이터 크기가 100인 배열로 선언했다.
- 데이터의 크기를 알려줄 size를 전역변수로 선언하였다.
add를 구현해보자.
만약에 10, 20, 30을 추가한다고 해보자. 그러면 이것을 코드로 나타내면
elementData[0] = 10;
elementData[1] = 20;
elementData[2] = 30;
이런식으로 인덱스 0부터 추가될 것이다. 이 구조를 쪼개 보자.
elementData[0] ㅡ> 10이 들어감 ㅡ> elementData[1]
ㅡ> 20이 들어감 ㅡ>elementData[2] ㅡ> 30이 들어감보면 데이터가 들어 가고 나서 인덱스의 숫자가 늘어나는 구조이다. 그렇다면 이거를 쉽게 풀어보자면 데이터가 하나씩 들어갈때마다 그 다음 실행되야 하는 인덱스는 현재데이터의 크기를 나타내는 말이지 않은가 ? 이것을 코드로 나타내보자.
public class ArrayList {
private int size = 0; //처음 데이터의 크기
private Object[] elementData = new Object[100];
public void add(Object element){
elementData[size] = element;
size++
}
}
elementData의 인덱스를 전역변수size로 설정- 해당
size의 끝에 데이터를 추가하고 데이터 추가 한 만큼size를 증가
그러면 만약에 원하는 위치에 데이터를 넣고 싶을 때는 어떻게 해야 할까 ?
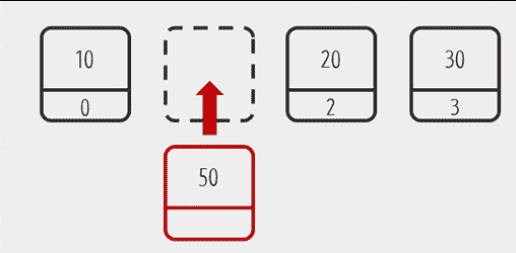
현재 10, 20, 30의 데이터를 가진 ArrayList가 있고 10과 20사이에 50 데이터를 꽂아 넣고 싶다고 가정하자.
이것을 코드로 나타내보자
add[1, 15] ((10(0)과 20(1)의 사이이니깐 50를 꽂아 넣을 위치는 1)그렇다면 List에는 어떻게 꽂힐까 ? 그림으로 보자
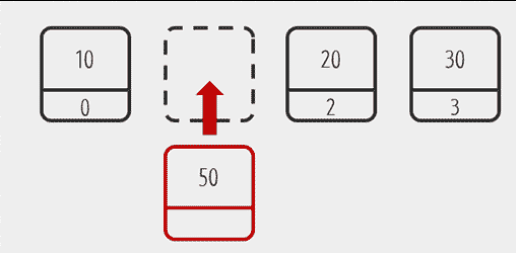
해당하는 위치에 50이 꽂히는 것을 볼 수 있다. 그리고 기존의 20과 30의 위치는 뒤로 밀리는 것을 볼 수 있다. 그렇다면 이것을 코드로 표현해보자
element[2] ㅡ> element[3] //인덱스 2의 위치를 3의 위치로 옮김
element[1] ㅡ> element[2] //인덱스 1의 위치를 2의 위치로 옮김
50 ㅡ> element[1] // 해당하는 데이터를 사용자가 원하는 인덱스의 위치에 꽂아넣음.public class ArrayList {
private int size = 0; //처음 데이터의 크기
private Object[] elementData = new Object[100];
public void add(int index, Object element){ //index와 데이터를 받아옴
for(int i = size-1; i >= index ; i--) {
elementData[i+1] = elementData[i];
}
elementData[index] = element;
size++;
}
}
- (하나 짚고 넘어가야 할 것은 size가 1이면 데이터는 한개가 담겨있는건데 컴퓨터는 0부터 세기 때문에 해당 데이터의 인덱스값은 0이다)
- 해당 데이터의 맨 끝부분에서 그 부분보다 한칸 더 이동하여 데이터를 담는다.
- 그 작업을 사용자가 원하는
index까지 실행한다.- 원하는
index자리까지 다 옮겼으면 해당하는index자리에 사용자가 원하는 데이터를 넣는다.- 데이터가 하나 추가 됏으니
size를 하나 추가한다.
리스트를 볼 수 있게 구현해보자
public class main {
public static void main(String[] args) {
ArrayList as = new ArrayList();
as.add(10);
as.add(20);
as.add(30);
System.out.println("as");
}
// 출력결과
DataStructure.Array.ArrayList@7a81197d리스트에 담긴 데이터를 보고 싶은데 주소값이 나오고 있다. 그렇다면 리스트를 볼 수 있게끔 구현해보자.
public class ArrayList {
public String toString() {
String str = "[";
for (int i= 0 ; i<size; i++) {
str+=elementData[i];
if(i < size -1) {
str+=",";
}
}
return str + "]";
}
}
- 리스트 형식을 위해 맨 처음에 "["를 추가
- 인덱스 0부터 해당 size크기까지 데이터를 문자열로 저장
- 마지막 인덱스 전까지 ","를 추가로 저장
출력결과 // [10,20,30]remove를 구현해보자
만약에 데이터가 10, 20, 30, 40담긴 리스트가 있다고 가정하자 그 중에 20을 빼내고 싶으면 어떻게 해야할까 ?
as.remove(1); (10(0), 20(1), 30(2), 40(3) 20의 인덱스는 1)element[1] ㅡ> 20이 나옴
element[2] ㅡ> element[1]
element[3] ㅡ> element[2]빠져나온 자리에 하나씩 당겨질 것이다. 이것을 코드로 구현해보자.
public class ArrayList {
public Object remove(int index){
Object Object = elementData[index];
for(int i = index ; i<= size-1; i++) {
elementData[i] = elementData[i+1];
}
size--;
return object;
}
}
object에 빠져나갈 해당 인덱스의 데이터를 임시로 담음.- 사용자가 지정한 인덱스의 위치보다 +1위치에 있는 데이터를 사용자가 지정한 인덱스의 위치로 담음.
- 해당 데이터의 인덱스끝까지 이 과정을 반복함.
- 데이터가 하나 빠져나갓으니
size감소.
get 구현하기
ArrayList의 장점이다. 인덱스의 위치를 알면 데이터를 아주빠르게 찾아올 수 있다.
public class ArrayList {
//ArrayList를 사용하는 이유 (인덱스의 위치를 알 경우에 데이터를 찾기 쉬움)
public Object get(int index) {
return elementData[index];
}
}간단하다. 해당하는 인덱스의 위치를 받아오면 해당하는 데이터를 반환해주면 된다.
indexOf 구현하기
ArrayList의 단점으로 볼 수 있다. 만약 위치를 모르고 해당 데이터를 찾으려면 처음부터 데이터가 나올때까지 다 뒤져봐야한다. 만약 찾으려는 데이터가 리스트의 맨끝에 있고 그 리스트의 데이터 개수가 1억개라 생각해보자. 그러면 엄청나게 자원이 들어갈 것이다.
해당 데이터의 위치를 찾는 함수를 구현해보자
public class ArrayList {
public int indexOf(Object element) {
for(int i = 0; i < size ; i++) {
if(elementData[i] == element) {
return i;
}
}
return -1;
}
}
- 해당 리스트의 첫번째 데이터 부터 마지막 데이터까지 반복
- 만약에 중간에 해당데이터와 사용자가 찾는 데이터가 일치하면 해당하는 인덱스값을 출력하고 반복문을 빠져나옴.
- 데이터를 못찾을 시에는 -1출력
Iterator(반복자) 구현
Iterator는 데이터들을 묶는 List나 Map, Set과 같은 자료구조에서 해당 데이터의 값을 받아 반복하는 함수이기 때문에 내부 생성을 통해 사용된다.
package DataStructure.Array;
public class ArrayList {
public ListIterator Iterator() {
return new Iterator();
}
class Iterator{
}
}
- ArrayList 클래스 안에
Iterator생성자를 메소드로 지정하고 클래스도 종속적인 클래스도 생성해준다.
Iterator의 next(), hasNext() 구현
Iterator의 next()함수는 데이터의 다음단계를 출력해주는 함수이다.
만약에 10, 20, 30이 담겨져 있는 list가 있다고 가정하자.
//list =[10, 20, 30]
list.next(); //10
list.next(); //20
list.next(); //30list[0] ㅡ> 10추출 ㅡ> list[1] ㅡ> 20추출 ㅡ> list[2] ㅡ> 30추출
이것을 코드로 나타내보자.
class ListIterator{
private int nextindex = 0;
public Object next() {
return get(nextindex++); //ArrayList의 get함수
}
}
- 값의 현재위치를 알려줄
nextindex를 선언한다. 맨 처음 위치는 0이다.- 한번 호출 할때마다
nextindex를 1씩증가시킨다.
(추출 된 뒤에 인덱스 값이 증가)
그러면 만약에 데이터가 1000개다 그러면 우리는 list.next()를 1000번할것인가 ? 그래서 나온게 hasNext()이다.
public boolean hasNext() {
return nextindex<size();
// size()함수는 따로 구현안했지만 return값으로 size를 출력해주는 함수이다.
}
- 앞서 말했다시피 size에서 -1을 해야 해당 데이터끝의 인덱스 값이 나온다.
- 따라서 값의 현재위치를 알려줄
nextindex가 데이터끝보다 작을 시에 트루가 나오게 한다.
while(list.hasNext()){
System.out.println(list.next());
}
//출력결과
10
20
30
Iterator의 previous(), hasprevious()구현
그러면 그 전단계로 돌아가려면 어떻게 해야할까 ?
public Object previous() {
return get(--nextindex);
}
public boolean hasPrevious() {
return nextindex>0;
}
previous(): 현재위치를 나타내는nextindex의 값을 줄이고 그 다음 데이터를 반환한다.- 해당위치가 0보다 클때 true를 출력.
while(li.hasNext()) {
System.out.println(li.next());
}
while(li.hasPrevious()) {
System.out.println(li.previous());
}
//출력결과
10
20
30
30
20
10Iterator의 remove() 구현하기
그렇다면 현재위치의 데이터를 삭제하고 싶으면 어떡할까 ?
public void remove() {
ArrayList.this.remove(nextindex-1);
nextindex--;
}
ArrayList의remove함수를 호출하고 현재위치인nextindex에서 -1을 하는 이유는 위쪽 remove함수에서 보면 알겠지만 예를 들어서 인덱스가 1인 데이터를 빼면 2위치의 데이터가 1로 옮겨지고 3의 데이터가 2로 옮겨지므로 해당하는 데이터의 위치보다 +1이 커야하는데 remove함수에서는 그것을 고려하여 로직이 구성되어 있다.- 앞서서
next()함수에서nextindex를 더했기 때문에 현재 위치보다 한칸 앞쪽을 가리키는 상태이다.- 실행 후 해당위치를 나타내는
nextindex를 1 감소시켜 빠져나간 데이터의 인덱스를 가리키도록 한다.
Iterator의 add() 구현하기
public void add(Object element) {
ArrayList.this.add(nextindex++, element);
}
ArrayList의add함수를 이용해 해당 위치인nextindex에 인덱스값으로 넣고 데이터를 넣는다.- 그 후 현재위치
nextindex를 1증가 시킨다.
