2022.08.17 현재 4,560팀 5,575명이 75,221번의 제출 엔트리를 통해 참여하고 있다.
대회 종료까지는 8일이 남았고,
우리 팀은 46등, 은메달 권에 위치해있다. 며칠째 0.800 점수에서 벗어나지 못하고 있다....
0.001점을 올려 금메달권에 가고자 여러가지 방법을 시도중이고, 새로운 모델로서 TabNet을 고려하게 되었다.
한 번도 접하지 못한 모델이라 논문과 여러 요약본, 베이스라인 코드를 보면서 공부하고 적용해보고자 한다.
출처 논문의 링크는 여기
Tabular data & DL?
AMEX 캐글에서 다루는 데이터는 Tabular 데이터라고 할 수 있다. 쉽게 생각하면 엑셀에서 row & column으로 표현될 수 있는 데이터이다. 자세한 설명은 여기.
현재 참여하는 데이터의 특성상 딥러닝보다는 전통적인? Tree 계열의 앙상블 모델이 우수하다고 알려져있다. 배울때는 대략적으로 이해했는데, 다시 고민해보게 되었다.
Why Tree?
트리 기반 앙상블을 사용하는 이유
1. 분류/회귀 문제를 해결할 때 경계를 결정하기 쉽다.
2. 학습시키기에 빠르고 쉽다.
3. 높은 해석력 (feature importance)
위 3가지로 요약될 수 있다.
Why Deep-learning in Tabular data?
그렇다면 위 3가지 장점을 딥러닝의 장점과 결합하면 더 좋은 성능을 가지지 않을까 하는 시도인 것 같다.
딥러닝의 장점을 결합시킨다면,
1. 전처리, 피쳐엔지니어링 없이 학습 가능하다.
2. 딥러닝 모델에 해석력을 부여하자 (Sequential Attention Mechanism 적용)
좋다는 것은 실제 데이터에 적용해보면 알게될 것 같다..!
Architecture
실제 TabNet이 어떻게 구성돼있는지 이해해보고 AMEX 데이터로 베이스라인을 돌려보자.
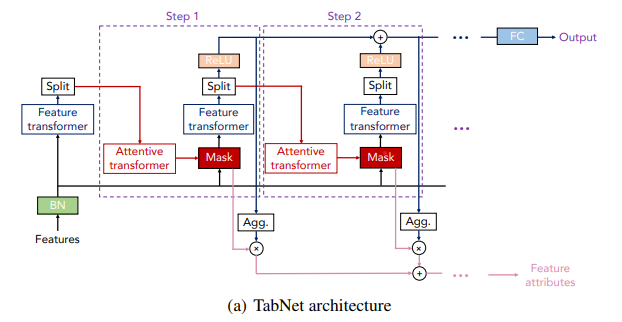
전체적인 구조를 봤을 때 (논문 제목에도 있지만) Attentive Transformer가 눈에 들어온다.
구글에서 만든 BERT 모형의 <Attention is all you need> 논문에서 많이 본 단어였다.
Transformer를 연구하면서 파생된 것 같다..!
자세한 설명은 여기 블로그에서 정말 쉽게 설명해주셨다.
Baseline - TabNet
1st try
(기본적인) 피쳐엔지니어링 해준 데이터셋을 가지고 먼저 돌려보았다. 총 1275개 피쳐 그리고 파라미터는 TabNet-training 코드에서 그대로 가져와서 사용했다.
처음 Pytorch pip 인스톨에서 에러가 난다면
!pip install --user pytorch-tabnet위 명령어를 시도해보시길!
첫 에폭부터 val_amex_score가 심상치 않았다..
참고한 캐글 코드에서는 아래와 같이 나왔는데,
epoch 0 | loss: 0.511 | val_0_auc: 0.91961 | val_0_accuracy: 0.8515 | val_0_amex_tabnet: 0.62966 | 0:00:25s
내가 돌린 코드는
epoch 0 | loss: 0.59655 | val_0_auc: 0.88705 | val_0_accuracy: 0.82154 | val_0_amex_tabnet: 0.53668 | 0:04:50s
이정도의 차이가 났다.
실행시간, 스코어, train loss 도 좋지 않았지만, 일단 조금 더 지켜보기로 했다.
참고한 코드에서는 60 epoch 까지가면 0.795까진 나오는것 같은데 피쳐엔지니어를 추가한 게 오히려 성능 저하시키는 느낌이었다.
2nd try
참고한 캐글 코드에서는 아래 리스트 것들만 전처리를 해주었다.
1. Average, Max, Min, Last (컬럼 골라서)
2. One Hot Encoding (범주형 변수)
3. fillna(0)
-> 435 features
따라서 나도 아주아주 기본적인 FE만 해주기로 했다.
1. Mean, Std, Last (모든 수치형 컬럼)
2. last (범주형 변수)
3. inf, fillna(-999)
-> 719 features
이렇게 줄였는데도,,
epoch 0 | loss: 0.59619 | val_0_auc: 0.86788 | val_0_accuracy: 0.78992 | val_0_amex_tabnet: 0.50974 | 0:02:56s
더 안좋아지는 것 같다는 느낌에, 일단 아예 같은 피쳐를 넣어서 보기로 했다.
3rd try
Reference
