1. 파이썬 설치
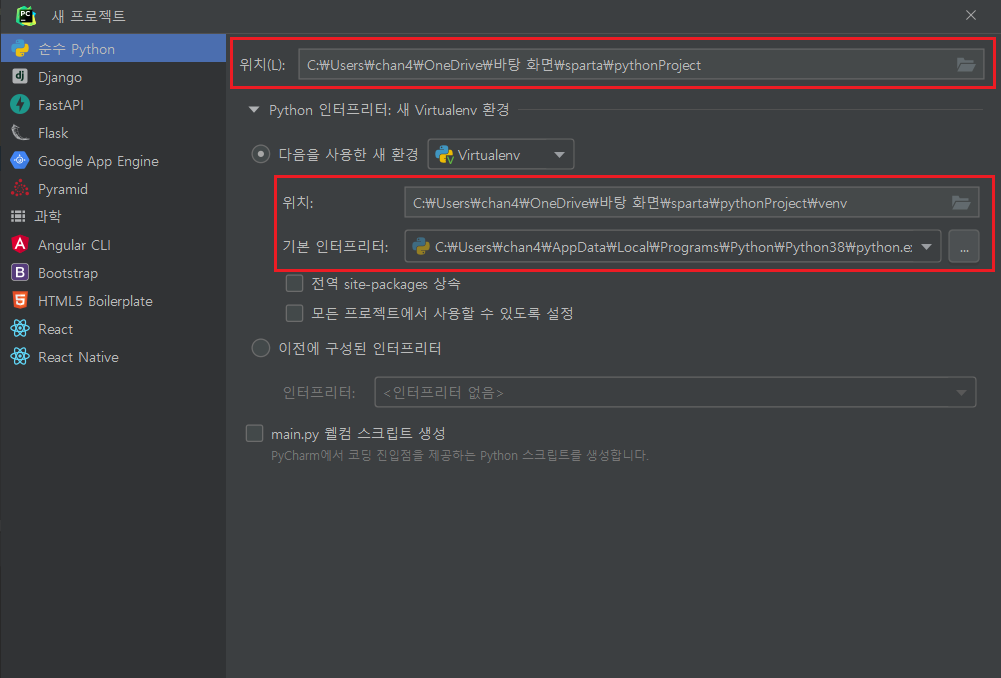
2. 새 프로젝트 생성
위치 : { project 경로 } / venv 폴더
기본 인터프리터 : Python38로 설정 되었는지 확인
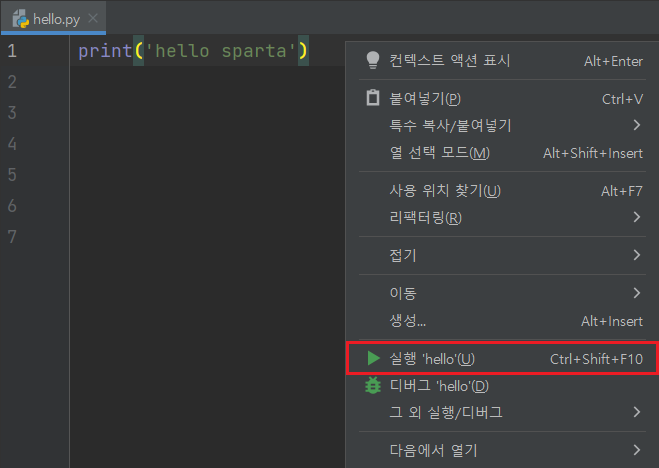
3. 기본 실행
코드 작성 후 오른쪽 마우스를 클릭하고 실행버튼 클릭
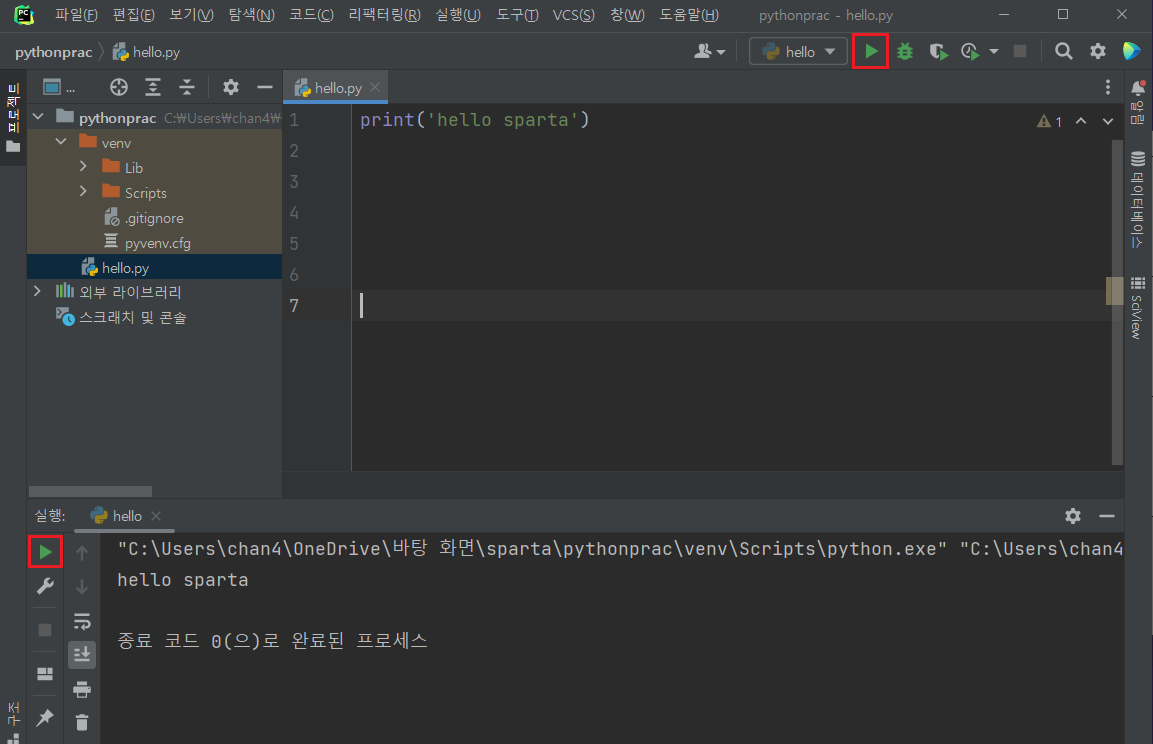
우측 상단이나 좌측 하단의 재생 버튼을 클릭해서 실행할 수 있다.
(버튼으로도 실행 가능하나 다른 파일이 실행될 수 있으므로 위와 같이 파일을 실행하도록 하자)
4. 함수 작성
함수 작성 방법
함수 선언 후 아래줄에 들여쓰기로 함수 내용을 작성 한다.
def 함수명(파라미터1, 파라미터2):
실행문 작성 예시)
def sum(a,b):
return a+b
result = sum(1,2)
print(result)
def is_adult(age):
if age > 20:
print('성인입니다')
else:
print('청소년입니다')
fruits = ['사과','배','배','감','수박','귤','딸기','사과','배','수박']
for fruit in fruits:
print(fruit)
count = 0
for fruit in fruits:
if fruit == '사과':
count += 1
print(count)
people = [{'name': 'bob', 'age': 20},
{'name': 'carry', 'age': 38},
{'name': 'john', 'age': 7},
{'name': 'smith', 'age': 17},
{'name': 'ben', 'age': 27}]
for person in people:
if person['age'] > 20:
print(person['name'])
def sum(a,b):
return a+b
result = sum(1,2)
print(result)
def is_adult(age):
if age > 20:
print('성인입니다')
else:
print('청소년입니다')
fruits = ['사과','배','배','감','수박','귤','딸기','사과','배','수박']
for fruit in fruits:
print(fruit)
count = 0
for fruit in fruits:
if fruit == '사과':
count += 1
print(count)
people = [{'name': 'bob', 'age': 20},
{'name': 'carry', 'age': 38},
{'name': 'john', 'age': 7},
{'name': 'smith', 'age': 17},
{'name': 'ben', 'age': 27}]
for person in people:
if person['age'] > 20:
print(person['name'])
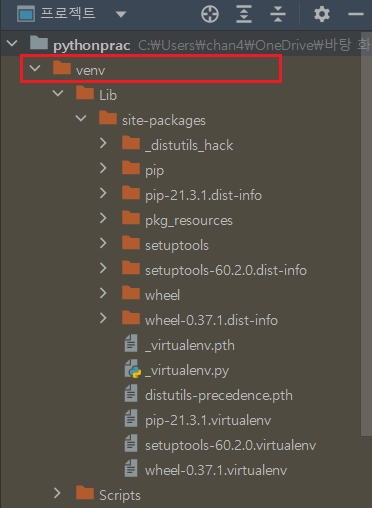
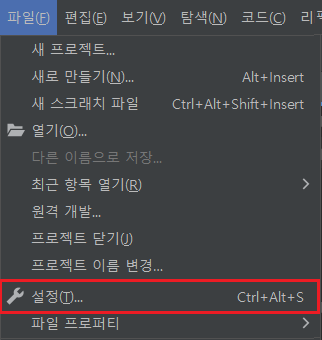
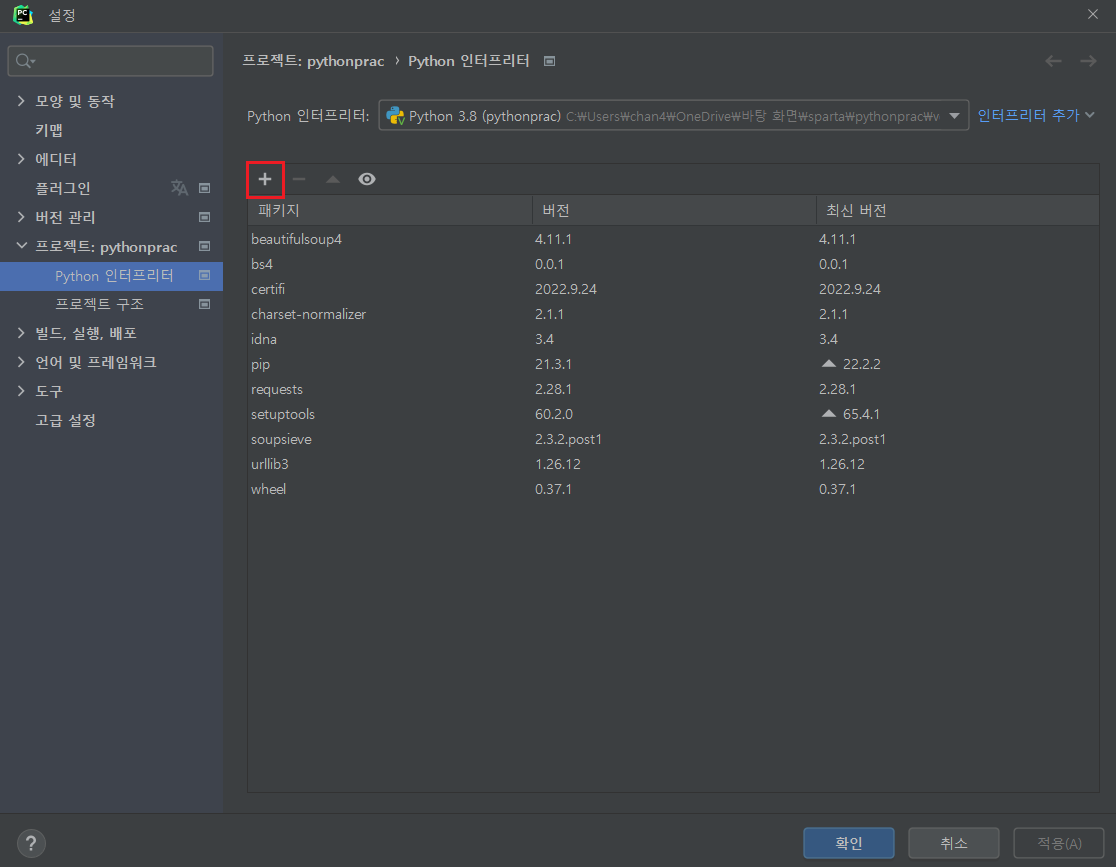
4. 가상환경
가상환경이란?
파이썬에서 가상 환경(virtual environment)은 하나의 PC에서 프로젝트 별로 독룁된 파이썬 실행 환경(runtime/interpreter)을 사용할 수 있도록 해줍니다. 가상 환경을 사용하지 않으면 PC 내의 모든 프로젝트에서 운영체제에 설치된 하나의 파이썬 런타임을 사용하게 되고 동일한 위치에 외부 패키지를 설치하고 서로 공유하게 됩니다. 이럴 경우, 하나의 프로젝트에서 설치한 패키지의 버전이 다른 프로젝트에서 설치한 동일 패키지의 다른 버전과 충동을 일으킬 소지가 생기기 때문에, 프로젝트 별로 독립된 가상 환경을 구성하여 사용하는 것이 권장됩니다.
출처 : https://www.daleseo.com/python-venv/
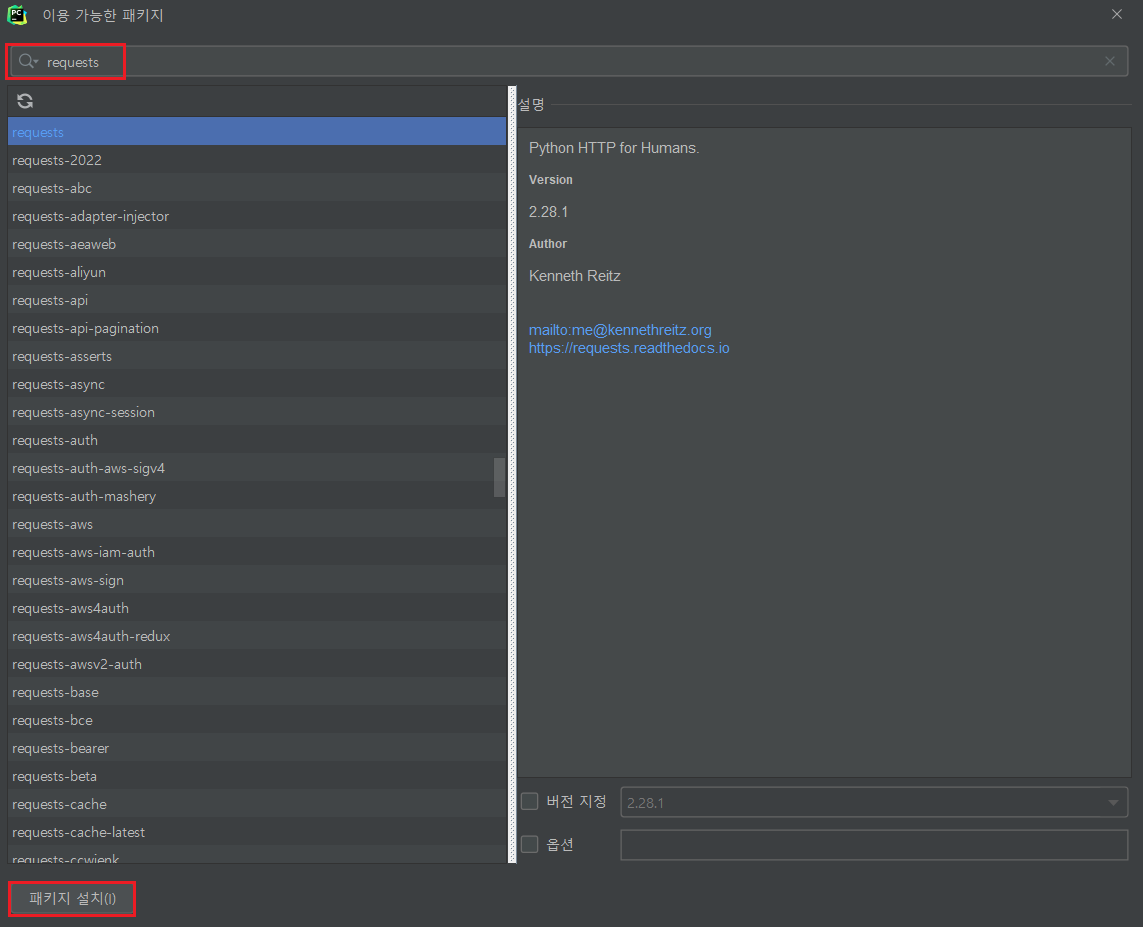
5. 패키지 사용해보기
1) request 패키지
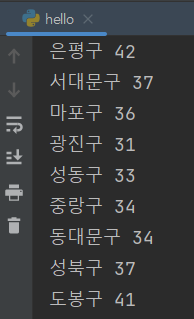
import requests # requests 라이브러리 설치 필요
r = requests.get('http://spartacodingclub.shop/sparta_api/seoulair')
rjson = r.json()
rows = rjson['RealtimeCityAir']['row']
for row in rows:
gu_name = row['MSRSTE_NM']
gu_mise = row['IDEX_MVL']
print(gu_name,gu_mise)
2) bs4 패키지
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
'''header는 브라우저가 요청한것 처리 실행하기 위해서'''
data = requests.get('https://movie.naver.com/movie/sdb/rank/rmovie.naver?sel=pnt&date=20210829',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
movies = soup.select('#old_content > table > tbody > tr')
print(movies)
for movie in movies:
a = movie.select_one('td.title > div > a')
if a is not None:
print(a.text)
'''None : 가로선 '''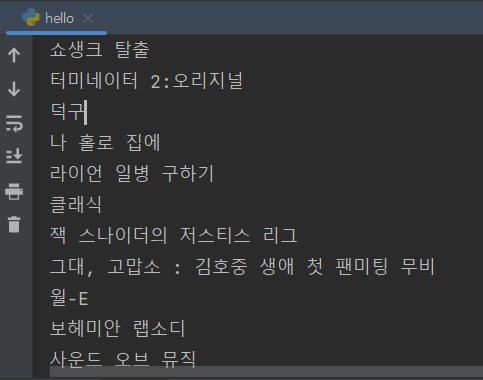
6. SQL VS NoSQL
1) SQL
SQL이란 무엇입니까?
NoSQL 데이터베이스를 이해했다면 이제는 과거에 가장 인기 있었던 SQL(Structured Query Language)로 액세스하는 관계형 데이터베이스와 이들을 비교해보겠습니다. 데이터가 고정된 열과 행을 가지고 있는 테이블에 저장되는 관계형 데이터베이스와 상호 작용할 때 SQL을 사용할 수 있습니다.
SQL 데이터베이스는 1970년대 초반에 사용자들로부터 많은 사랑을 받았습니다. 당시만 해도 스토리지가 매우 비쌌기 때문에 소프트웨어 엔지니어들은 데이터 중복을 줄이기 위해 데이터베이스를 정규화했습니다.
또한 1970년대의 소프트웨어 엔지니어들은 일반적으로 소프트웨어 개발에 있어 폭포수(waterfall) 모델을 따랐습니다. 개발이 시작되기 전에 프로젝트에 대한 상세한 계획이 수립되었습니다. 소프트웨어 엔지니어들은 저장이 필요한 모든 데이터를 신중하게 고려하기 위해 애써서 복잡한 엔터티-관계(E-R) 다이어그램을 만들었습니다. 이러한 선행 계획 모델로 인해 소프트웨어 엔지니어들은 개발 주기 동안 요구사항이 바뀔 경우, 이에 대처하느라 애를 먹었습니다. 그 결과, 프로젝트에서 예산이 초과되고 마감 기간을 넘겨서 사용자 요구를 충족하지 못하는 일이 잦았습니다.
2) NoSQL
단어 뜻 그 자체를 따지자면 "Not only SQL"로, SQL만을 사용하지 않는 데이터베이스 관리 시스템(DBMS)을 지칭하는 단어이다. 관계형 데이터베이스를 사용하지 않는다는 의미가 아닌, 여러 유형의 데이터베이스를 사용하는 것이다.
데이터를 조직하는 방법에는 리스트, 해시 테이블, 트리, 그래프 등의 다양한 방법이 있고 각각은 장점과 단점이 명확하기 때문에 단순히 NoSQL이라고만 해서는 너무 뜬구름 잡는 얘기가 된다. NoSQL이라는 단어는 RDBMS가 데이터베이스의 독점적인 지위를 차지하고 있는 현재 상황에 반발하는 정신을 담고 있다.
7. MongoDB연결
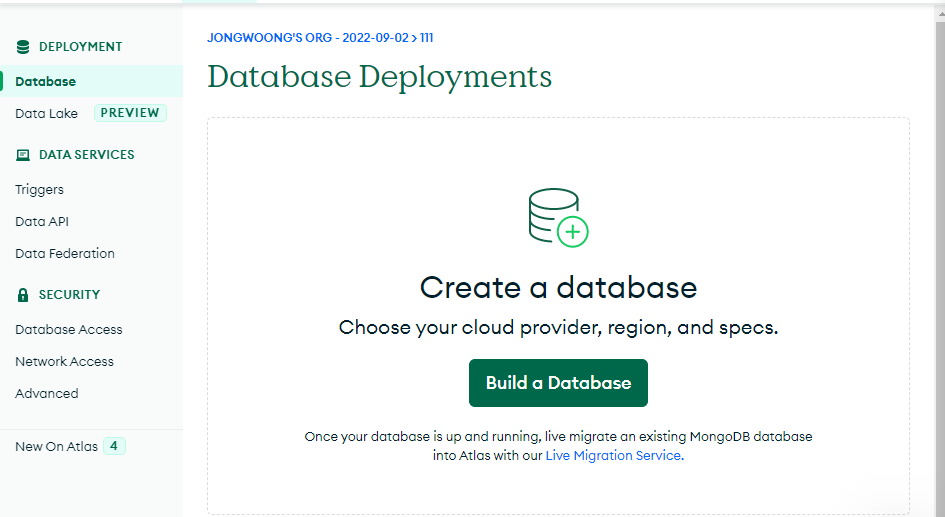

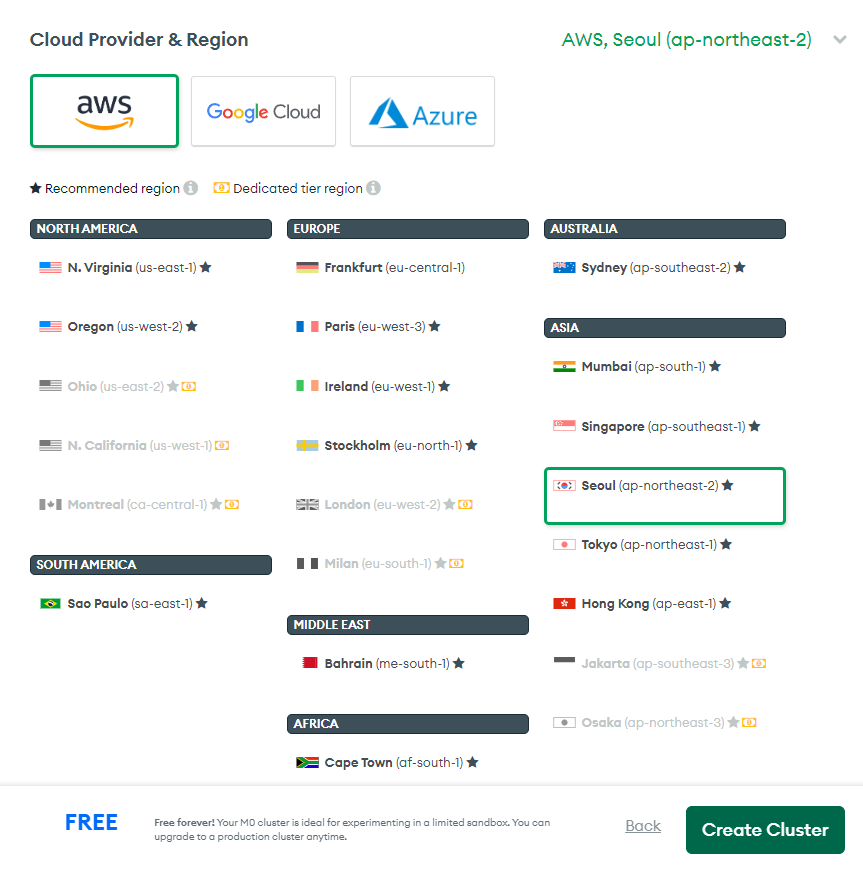
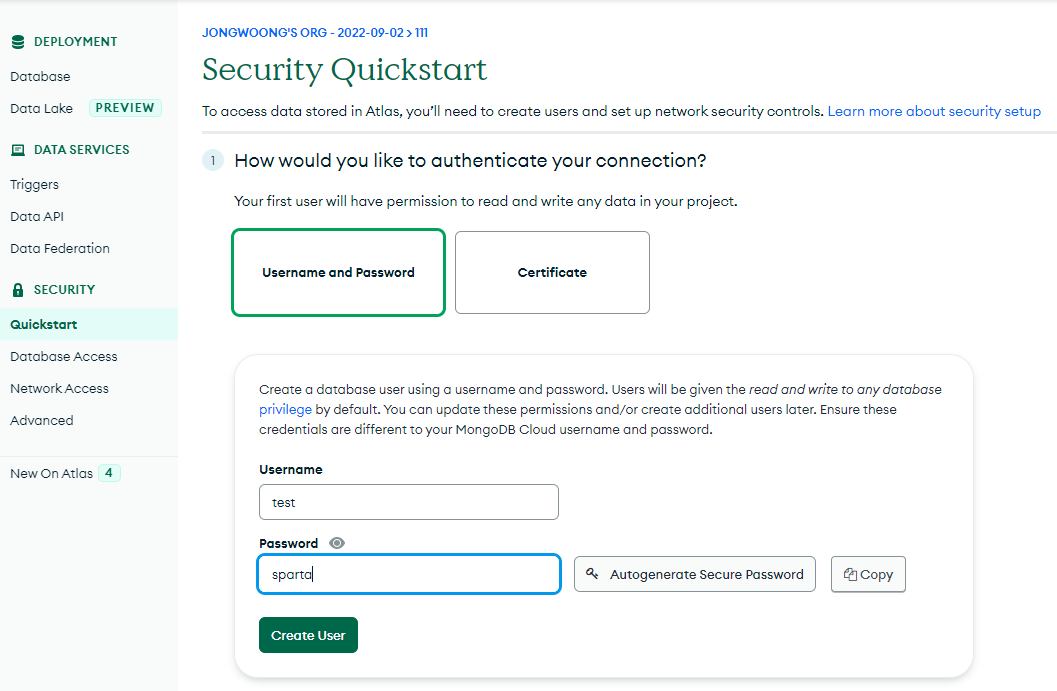
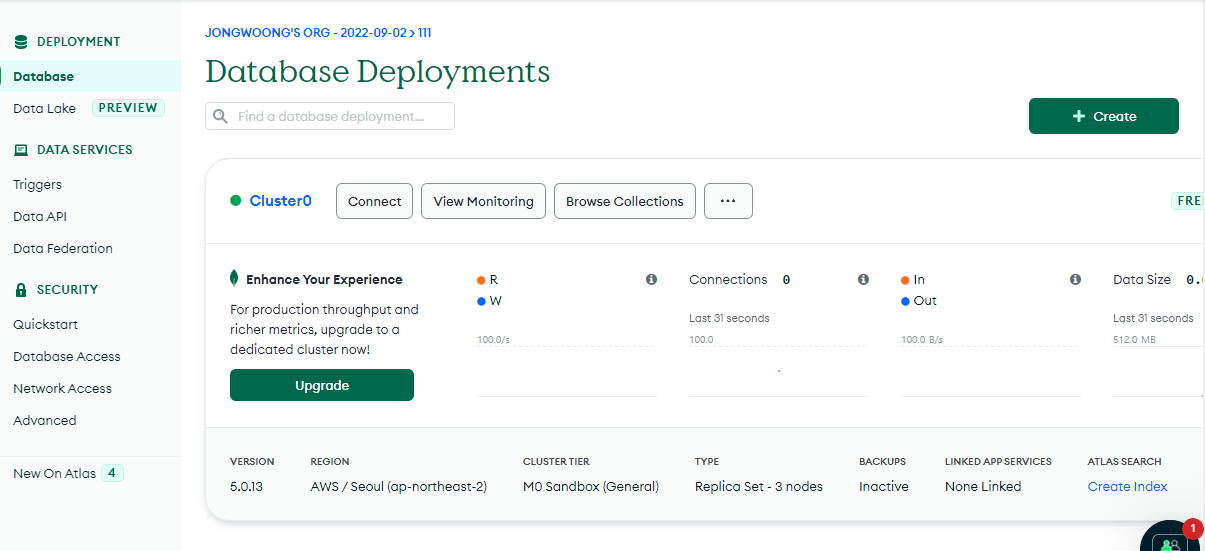
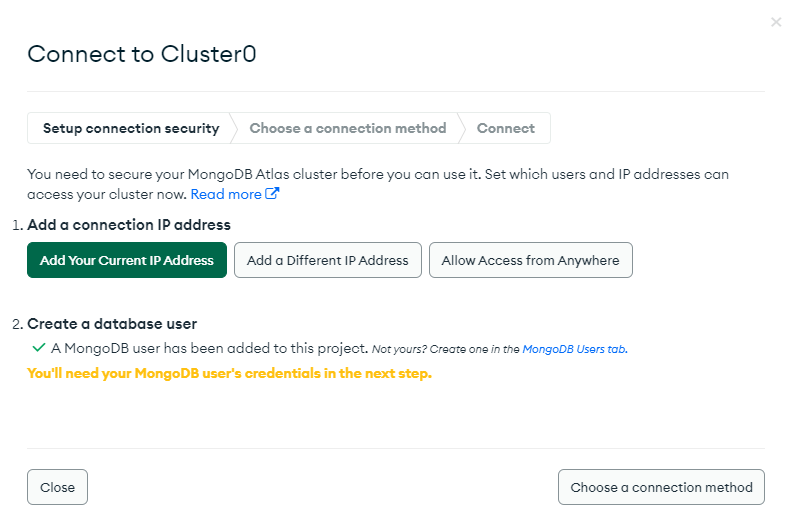
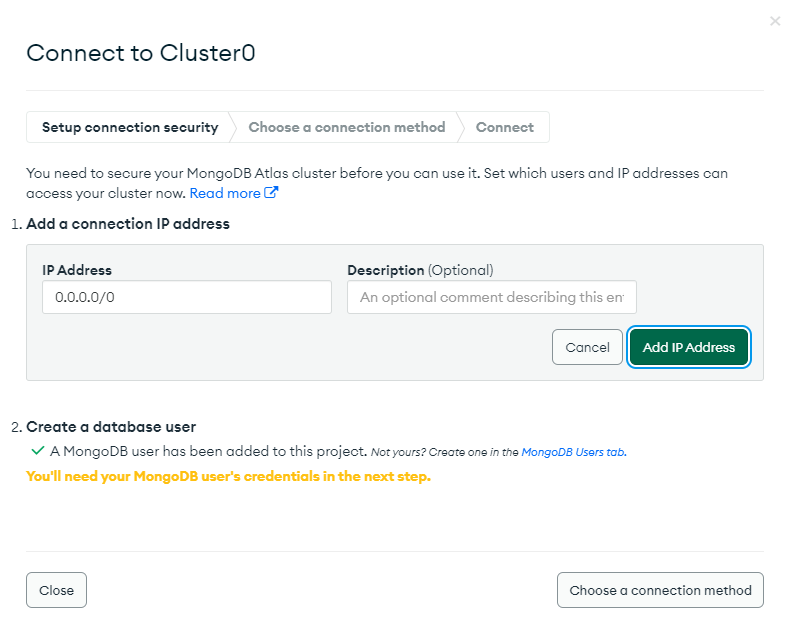
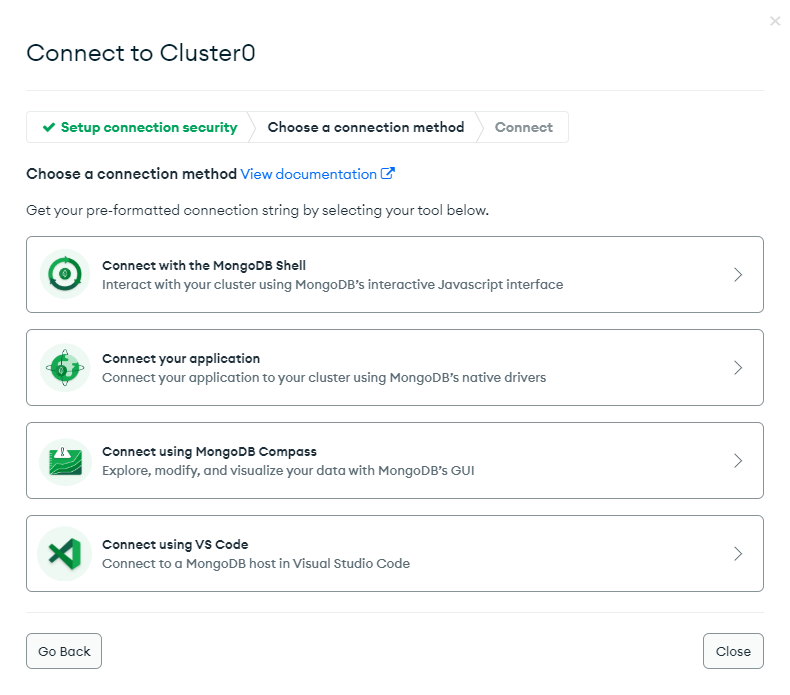
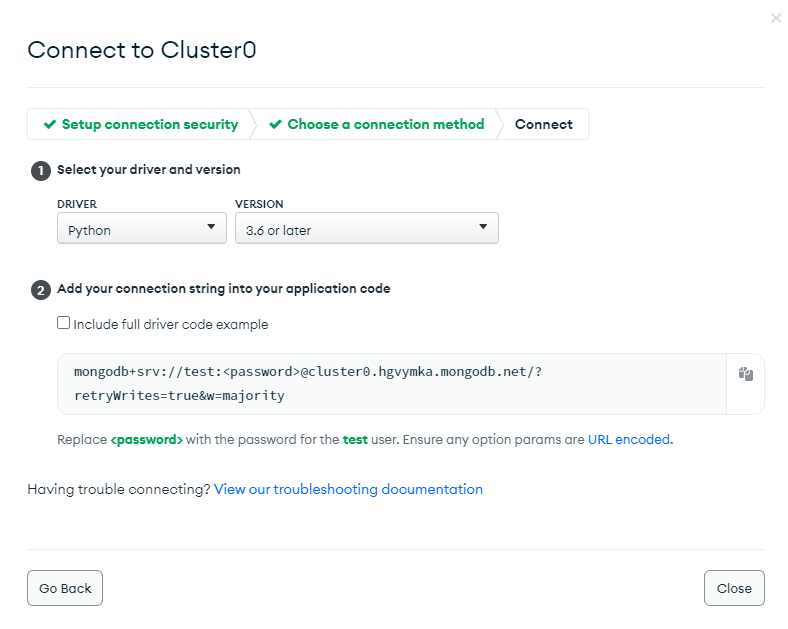
7. 데이터 Insert 하기
from pymongo import MongoClient
import certifi
ca = certifi.where()
client = MongoClient('mongodb+srv://test:sparta@cluster0.yhkjgex.mongodb.net/?retryWrites=true&w=majority',tlsCAFile=ca)
db = client.dbsparta
doc = {
"name":"bob",
"age":27
}
db.users.insert_one(doc)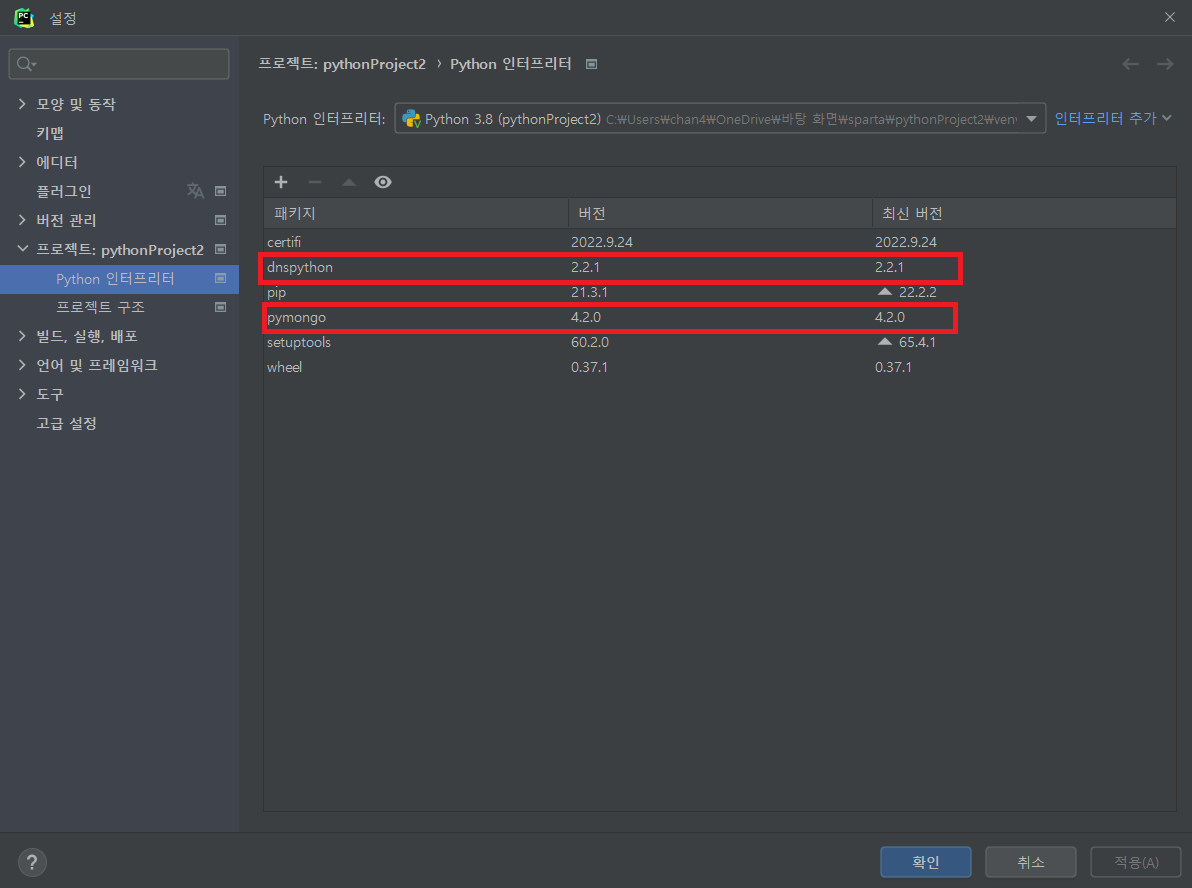
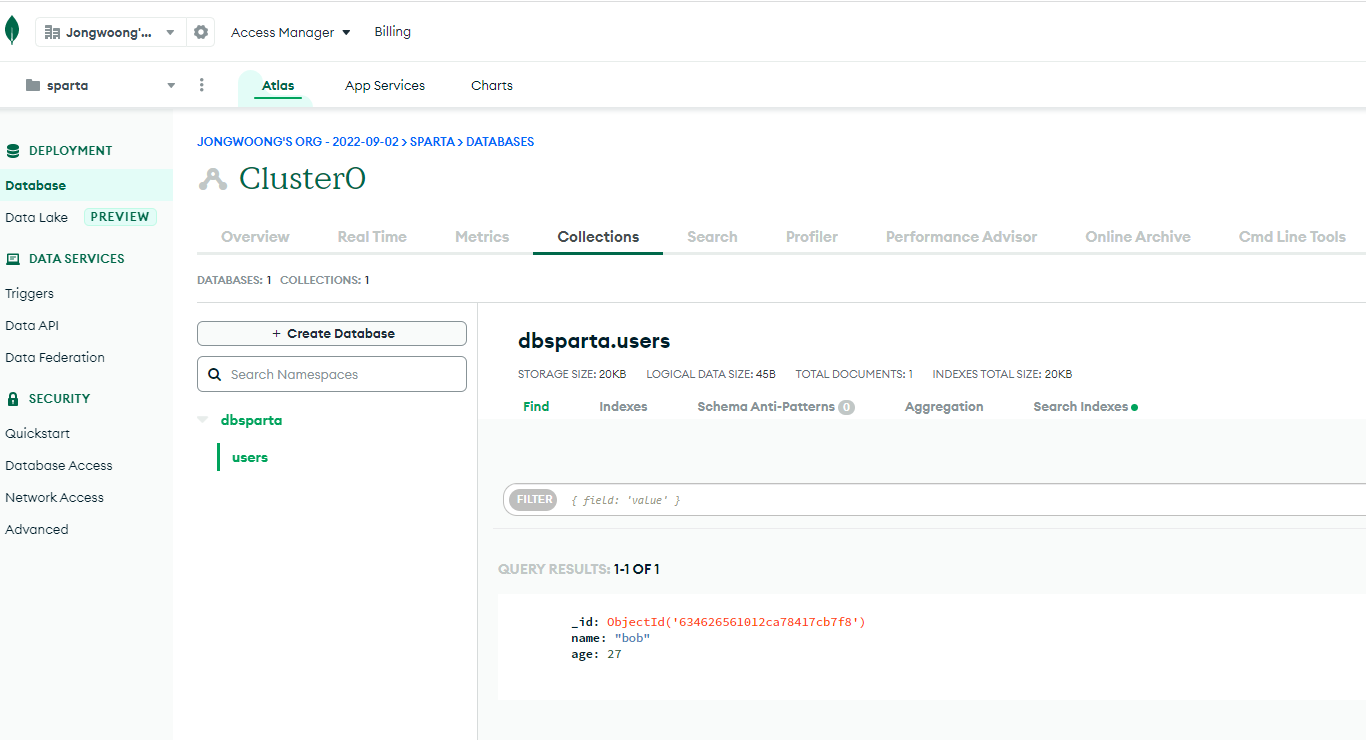
8. 데이터 CRUD
# 저장 - 예시
doc = {'name':'bobby','age':21}
db.users.insert_one(doc)
# 한 개 찾기 - 예시
user = db.users.find_one({'name':'bobby'})
# 여러개 찾기 - 예시 ( _id 값은 제외하고 출력)
all_users = list(db.users.find({},{'_id':False}))
# 바꾸기 - 예시
db.users.update_one({'name':'bobby'},{'$set':{'age':19}})
# 지우기 - 예시
db.users.delete_one({'name':'bobby'})9. 크롤링한 데이터 가져오고 DB에 저장
import requests
from bs4 import BeautifulSoup
# URL을 읽어서 HTML를 받아오고,
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://movie.naver.com/movie/sdb/rank/rmovie.naver?sel=pnt&date=20210829',headers=headers)
# HTML을 BeautifulSoup이라는 라이브러리를 활용해 검색하기 용이한 상태로 만듦
soup = BeautifulSoup(data.text, 'html.parser')
# select를 이용해서, tr들을 불러오기
movies = soup.select('#old_content > table > tbody > tr')
# movies (tr들) 의 반복문을 돌리기
for movie in movies:
# movie 안에 a 가 있으면,
a_tag = movie.select_one('td.title > div > a')
if a_tag is not None:
rank = movie.select_one('td:nth-child(1) > img')['alt'] # img 태그의 alt 속성값을 가져오기
title = a_tag.text # a 태그 사이의 텍스트를 가져오기
star = movie.select_one('td.point').text # td 태그 사이의 텍스트를 가져오기
doc = {
'title' : title,
'rank' : rank,
'star' : star
}
db.movies.insert_one(doc)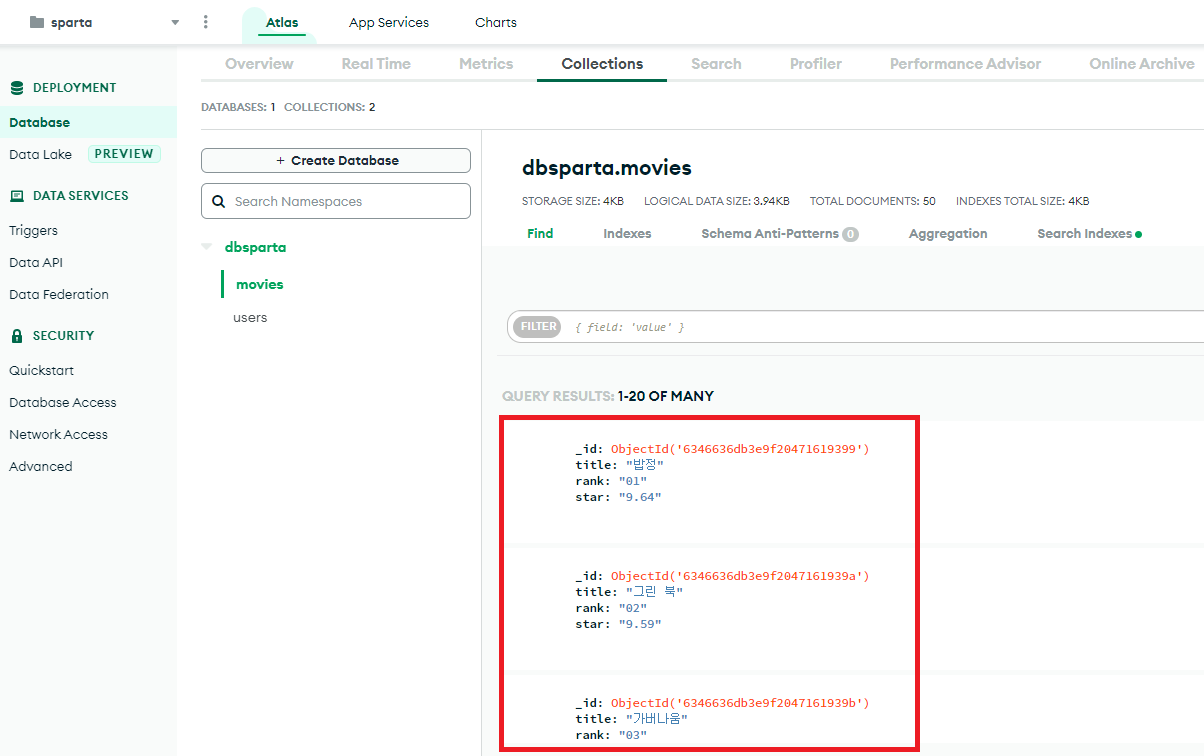
10. 과제
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
'''header는 브라우저가 요청한것 처리 실행하기 위해서'''
data = requests.get('https://www.genie.co.kr/chart/top200?ditc=M&rtm=N&ymd=20210701',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
songs = soup.select('#body-content > div.newest-list > div > table > tbody> tr')
for song in songs:
if song is not None:
title = song.select_one('td.check > input')['title']
rank = song.select_one('td.number').text
artist = song.select_one('td.info > a.artist.ellipsis').text
print(title, rank, artist)