은닉층이 없는 신경망 모형을 Keras 모형으로 구성
-
은닉층이 없는 신경망은 MF알고리즘과 기본적으로 동일한 모형이다.
-
MF를 keras로 구현
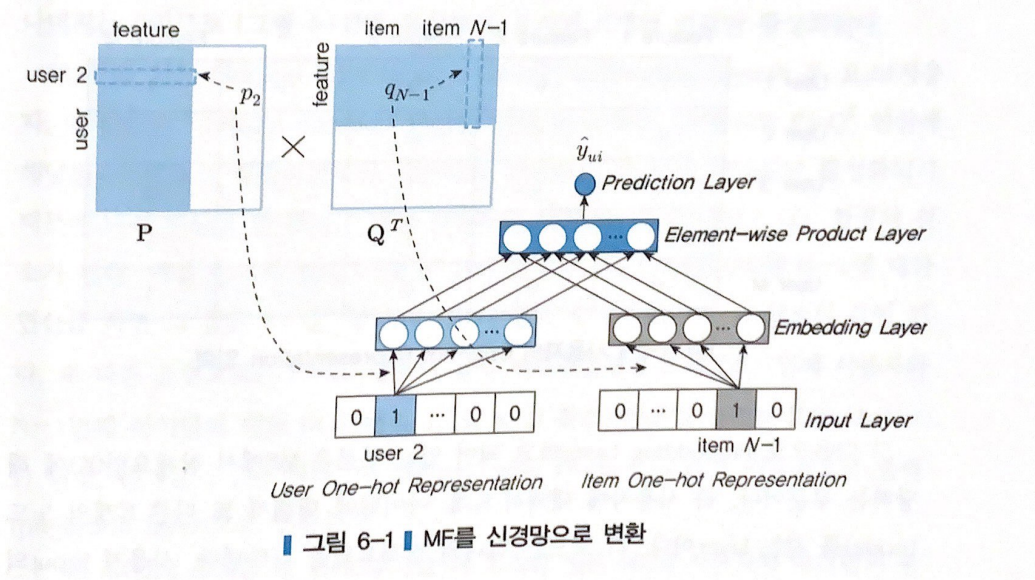
Input : 사용자, 아이템 데이터의 One-hot Encoding
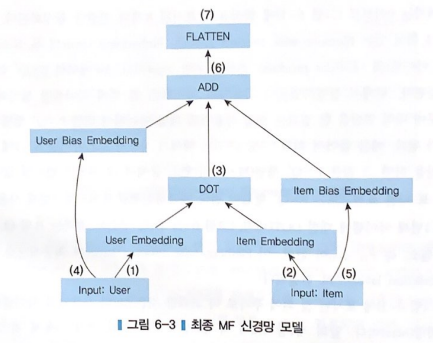
1) 사용자 입력은 K개의 노드를 갖는 User Embedding과 연결된다.
2) 아이템 입력은 K개의 노드를 갖는 Item Embedding과 연결된다.
3) User Embedding과 Item Embedding은 내적 연산으로 결합된다.
4) 사용자 입력은 1개의 노드를 갖는 User Bias Embedding과 연결된다.
5) 아이템 입력은 1개의 노드를 갖는 Item Bias Embedding과 연결된다.
6) User Bias Embedding과 Item Bias Embedding은 내적 연산에 더해진다.
7) Flatten Layer는 최종 데이터와 계산에 사용된 행렬의 차원을 맞춰준다.
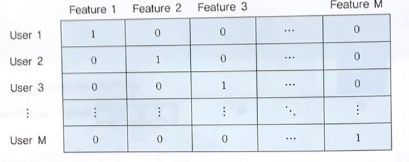
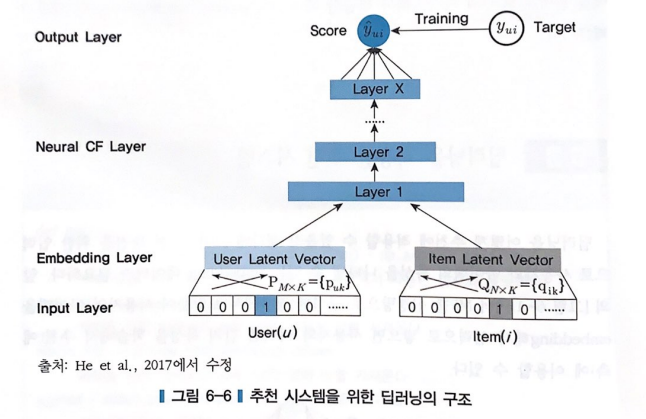
A) Input Layer : 사용자와 아이템으로부터 입력을 받는 부분
- User One-hot Representation : encoding의 속성 수 = user의 수
- Item One-hot Representation : encoding의 속성 수 = item의 수
-> One-hot Encoding을 거치면 행과 열의 차원이 같으며 대각 원소만 1을 가지는 행렬이 된다.
B) **Embedding Layer** : MF에서 잠재요인에 해당하는 부분 (사용자에 대해서 K개, 아이템에 대해서 K개의 노드를 갖는 층)
- 1개의 노드는 하나의 잠재요인을 의미한다.
- Input의 모든 feature는 Embedding layer의 모든 node와 연결된다.
- Input이 One-hot Encoding이기 때문에, 각 사용자 혹은 아이템별로 각각 K개의 연결이 활성화된다.
C) Element-wise Product Layer : Embedding 층의 두 요소 (사용자, 아이템)의 내적 연산을 위한 층
- 연산으로 예측평점행렬인 이 된다.
- Element-wise Product Layer은 최종 출력으로 연결된다.
D) 사용자 평가경향(user bias)와 아이템 평가경향(item bias) 고려
- 각각 하나의 노드를 갖는 층으로 모델화가 가능하다.
- 사용자의 경우 : 모든 사용자 입력 노드 m개와 연결된 하나의 노드
- 아이템의 경우 : 모든 아이템 입력 노드 N개와 연결된 하나의 노드
E) Flatten Layer: 우리가 필요한 최종 데이터와 지금까지 계산된 행렬의 차원을 맞춰주기 위해 차원을 줄여줌.
@ 전체 평균은 신경망 모델에 직접 넣으면 복잡하기 때문에 신경망 투입 전에 모두 빼주고, 최종 예측값에 더해준다.
Keras로 MF 구현
# 사용된 모듈
import pandas as pd
import numpy as np
import tensorflow as tf
from tensorflow.keras import layers
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input, Embedding, Dot, Add, Flatten
from tensorflow.keras.regularizers import l2
from tensorflow.keras.optimizers import SGD, Adamax# Variable 초기화
K = 200 # Latent factor 수 (잠재 요인의 수)
mu = ratings_train.rating.mean() # 전체 평균
M = ratings.user_id.max() + 1 # Number of users (사용자 아이디의 최대값 -> embedding에서 사용)
N = ratings.movie_id.max() + 1 # Number of movies (영화 아이디의 최대값)
# Keras model
# User input : 사용자 데이터 입력 형식
user = Input(shape=(1, ))
# Item input : 아이템 데이터 입력 형식
item = Input(shape=(1, ))
# (M, 1, K) : 사용자 임베딩 layer 지정 : M x K의 연결
P_embedding = Embedding(M, K, embeddings_regularizer=l2())(user)
# (N, 1, K) : 아이템 임베딩 layer 지정 : N x K의 연결
Q_embedding = Embedding(N, K, embeddings_regularizer=l2())(item)
# User bias term (M, 1, ) : 사용자 bias embedding layer 지정 : M x 1의 연결
user_bias = Embedding(M, 1, embeddings_regularizer=l2())(user)
# Item bias term (N, 1, ) : 아이템 bias embedding layer 지정 : N x 1의 연결
item_bias = Embedding(N, 1, embeddings_regularizer=l2())(item)
##### (2)
# (1, 1, 1) : 사용자, 아이템 임베딩 레이어를 내적 연산
R = layers.dot([P_embedding, Q_embedding], axes=2)
# 사용자 bias와 아이템 bias를 더함
R = layers.add([R, user_bias, item_bias])
# (1, 1) : 차원 압축(1차원 배열)
R = Flatten()(R)
# Model setting
model = Model(inputs=[user, item], outputs=R) #입력, 출력 정의
model.compile(
loss=RMSE,
optimizer=SGD(), #SGD, Adamax ...
metrics=[RMSE] # 측정지표
)
model.summary() # 모델 요약 정보
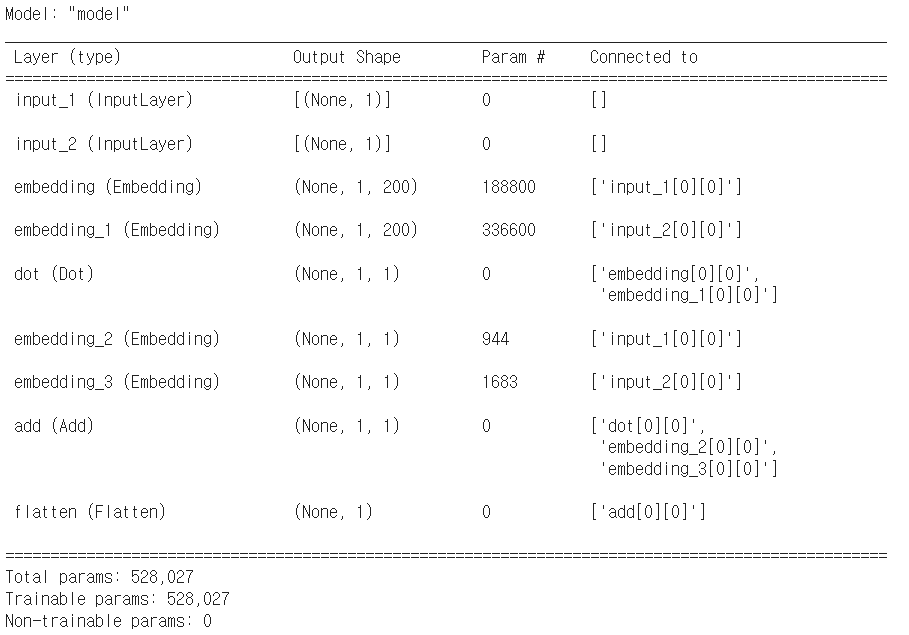
파라미터 개수
embedding : 사용자의 잠재 요인 (P) : 944 x 200 = 188,800
embedding_1 : 아이템의 잠재 요인 (Q) : 1683 x 200 = 336,600
embedding_2 : 사용자 bias layer -> 944 x 1
embedding_3 : 아이템 bias layer -> 1683 x 1
# Model fitting(학습)
result = model.fit(
x=[ratings_train.user_id.values, ratings_train.movie_id.values], #사용자와 아이템의 id를 입력으로
#출력은 평점 값에서 전체 평균을 빼서 사용
y=ratings_train.rating.values - mu,
epochs=60,
batch_size=256,
validation_data=(
[ratings_test.user_id.values, ratings_test.movie_id.values], #test-set의 입력
ratings_test.rating.values - mu
)
)
# Prediction
#예측 대상을 맨 처음 6개로 정함
user_ids = ratings_test.user_id.values[0:6]
movie_ids = ratings_test.movie_id.values[0:6]
#예측치를 구하고 전체 평균을 더해줌
predictions = model.predict([user_ids, movie_ids]) + mu
#실제값 출력
print("Actuals: \n", ratings_test[0:6])
print( )
#예측값 출력
print("Predictions: \n", predictions)
# RMSE check
def RMSE2(y_true, y_pred):
return np.sqrt(np.mean((np.array(y_true) - np.array(y_pred))**2))
#test-set
user_ids = ratings_test.user_id.values
movie_ids = ratings_test.movie_id.values
y_pred = model.predict([user_ids, movie_ids]) + mu #2차원의 array
y_pred = np.ravel(y_pred, order='C') #np.ravel을 사용하여 1차원 행렬로 바꾸기
y_true = np.array(ratings_test.rating) #실제 평점값
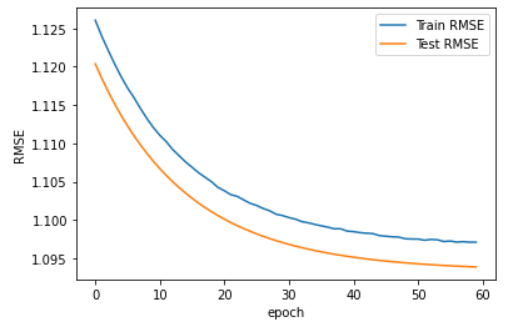
RMSE2(y_true, y_pred)RMSE값이 1.0946의 값이 출력된다. 4장에서는 RMSE값이 약 0.91의 값이 나왔는데, 본 코드에서 성능이 낮아진 이유는 MF와 Keras 모델이 기본적인 것은 같지만 구체적인 부분에서 최적화가 아직 되지 않았기 때문이다.
딥러닝을 적용한 추천시스템
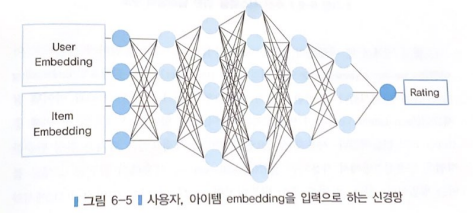
- 은닉층이 존재한다는 점에서 신경망으로 구현한 MF와 차이점이 있다.
- 사용자 잠재요인과 아이템 잠재요인이 합쳐져서 신경망의 첫번째 층이 구성된다.
- 잠재요인을 합치는 가장 간단한 방법은 인공신경망에서 사용되는 '결합'을 사용해서 앞뒤로 붙이는 것이다.
#P, Q, 사용자 bias, 아이템 bias를 붙여서 하나의 layer를 만든다.
R = Concatenate()([P_embedding, Q_embedding, user_bias, item_bias]) # (2K + 2, )
# Neural network
R = Dense(2048)(R) #노드가 2048개인 dense layer
R = Activation('linear')(R)
R = Dense(256)(R)
R = Activation('linear')(R)
#노드가 1개인 dense layer를 추가하고, 이 층이 출력에 연결된다.
R = Dense(1)(R)
model = Model(inputs=[user, item], outputs=R)
model.compile(
loss=RMSE,
optimizer=SGD(),
#optimizer=Adamax(),
metrics=[RMSE]
)
model.summary()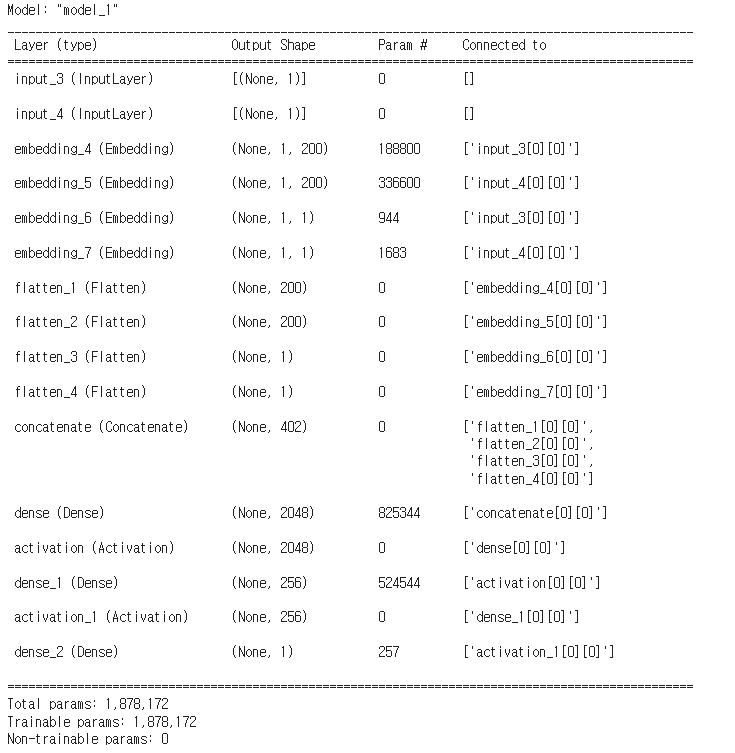
파라미터 개수
embedding_4 : 사용자의 잠재 요인 (P) : 944 x 200 = 188,800
embedding_5 : 아이템의 잠재 요인 (Q) : 1683 x 200 = 336,600
embedding_6 : 사용자 bias layer -> 944 x 1
embedding_7 : 아이템 bias layer -> 1683 x 1
concatenate : 200(user embedding) + 200(item embedding) + 1(user bias) + 1(item bias)
dense (Dense) : (402 + 1) x 2048(노드 개수) = 825,344
dense_1 (Dense) : (2048 + 1) x 256 = 524,544
dense_2 (Dense) : 256 + 1
# Model fitting
result = model.fit(
x=[ratings_train.user_id.values, ratings_train.movie_id.values],
y=ratings_train.rating.values - mu, #출력 : 사용자-아이템별 평점값 - 평균
epochs=65,
batch_size=512, #한 번에 연산하는 batch 크기 지정
validation_data=(
[ratings_test.user_id.values, ratings_test.movie_id.values],
ratings_test.rating.values - mu
)
)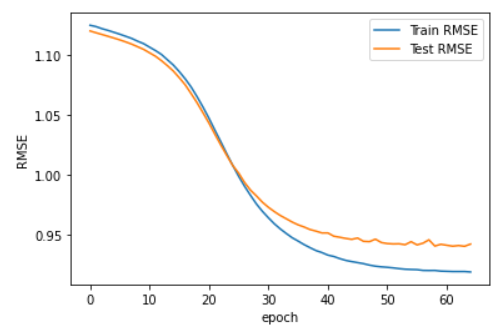
- rmse가 0.943으로 MF를 신경망으로 구현한 경우 보다는 rmse가 훨씬 향상되었음을 볼 수 있다.
- 다양한 layer와 학습 조건을 시도하며 최선의 세팅을 찾으며 성능 개선이 가능하다.
- 신경망의 최적화를 통한다면 더 좋은 결과를 얻을 수 있을 것이다.
- 데이터가 binary이거나 숫자가 아닌 데이터 혹은 sparse 데이터일 경우 딥러닝의 성능이 눈에띄게 좋을 것이라 예상된다.
딥러닝 모델에 변수 추가하기
- 사용자가 부여한 아이템의 평점 외에 다른 변수를 추가
- EX) 사용자와 아이템간의 다양한 특성 포함 (직업, 나이, 성별, 우편번호)
- 추가한 변수가 유의미하지 않다면 변수를 추가해도 예측력이 향상되지 않는다. 때문에 변수가 영향을 미칠것이라는 가정을 확인한 뒤 모델에 추가하는 것이 바람직하다.
### 직업을 추가 변수로 고려
### 가정 : 사용자의 직업에 따라 영화를 평가하는 패턴이 다르다.
import pandas as pd
import numpy as np
# csv 파일에서 불러오기
r_cols = ['user_id', 'movie_id', 'rating', 'timestamp']
ratings = pd.read_csv('u.data', names=r_cols, sep='\t',encoding='latin-1')
ratings = ratings[['user_id', 'movie_id', 'rating']].astype(int) # timestamp 제거
# train test 분리
from sklearn.utils import shuffle
TRAIN_SIZE = 0.75
ratings = shuffle(ratings)
cutoff = int(TRAIN_SIZE * len(ratings))
ratings_train = ratings.iloc[:cutoff]
ratings_test = ratings.iloc[cutoff:]
# **수정된 부분 1**
u_cols = ['user_id', 'age', 'sex', 'occupation', 'zip_code']
users = pd.read_csv('u.user', sep='|', names=u_cols, encoding='latin-1')
#사용자 데이터를 읽어와서 ID와 직업만 남긴다.
users = users[['user_id', 'occupation']]
# Convert occupation(string to integer)
# 직업이 STRING 형태인데 이를 숫자로 바꾸는 작업
occupation = {}
def convert_occ(x):
if x in occupation: #이미 존재하면 그 값을 반환
return occupation[x]
else:
occupation[x] = len(occupation)
#새로운 ELEMENT를 새로운 INT값과 함께 딕셔너리에 추가
return occupation[x] #새로운 int 반환
users['occupation'] = users['occupation'].apply(convert_occ)
L = len(occupation) #직업의 개수 - DL에서 embedding에 활용
#trainset과 사용자 직업을 merge
train_occ = pd.merge(ratings_train, users, on='user_id')['occupation']
test_occ = pd.merge(ratings_test, users, on='user_id')['occupation']
# **수정된 부분 1 끝**
import tensorflow as tf
from tensorflow.keras import layers
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input, Embedding, Dot, Add, Flatten
from tensorflow.keras.regularizers import l2
from tensorflow.keras.optimizers import SGD, Adam, Adamax
# Variable 초기화
K = 200 # Latent factor 수
mu = ratings_train.rating.mean() # 전체 평균
M = ratings.user_id.max() + 1 # Number of users
N = ratings.movie_id.max() + 1 # Number of movies
# Defining RMSE measure
def RMSE(y_true, y_pred):
return tf.sqrt(tf.reduce_mean(tf.square(y_true - y_pred)))
##### (2)
# Keras model
user = Input(shape=(1, ))
item = Input(shape=(1, ))
P_embedding = Embedding(M, K, embeddings_regularizer=l2())(user)
Q_embedding = Embedding(N, K, embeddings_regularizer=l2())(item)
user_bias = Embedding(M, 1, embeddings_regularizer=l2())(user)
item_bias = Embedding(N, 1, embeddings_regularizer=l2())(item)
# Concatenate layers
from tensorflow.keras.layers import Dense, Concatenate, Activation
P_embedding = Flatten()(P_embedding)
Q_embedding = Flatten()(Q_embedding)
user_bias = Flatten()(user_bias)
item_bias = Flatten()(item_bias)
# **수정된 부분 2**
occ = Input(shape=(1, )) #직업에 대한 입력을 새로 만든다.
#직업을 세개의 잠재요인으로 embedding
occ_embedding = Embedding(L, 3, embeddings_regularizer=l2())(occ)
#다른 embedding과 동일하게 차원을 줄인다.
occ_layer = Flatten()(occ_embedding)
# P, Q, 사용자 bias, 아이템 bias, 직업 모두 합쳐서 새로운 층을 만든다.
R = Concatenate()([P_embedding, Q_embedding, user_bias, item_bias, occ_layer])
# **수정된 부분 2 끝 **
# Neural network
R = Dense(2048)(R)
R = Activation('linear')(R)
R = Dense(256)(R)
R = Activation('linear')(R)
R = Dense(1)(R)
# **수정된 부분 3**
#직업까지 input값으로 넣어준다.
model = Model(inputs=[user, item, occ], outputs=R)
# **수정된 부분 3 끝 **
model.compile(
loss=RMSE,
optimizer=SGD(),
#optimizer=Adamax(),
metrics=[RMSE]
)
model.summary()
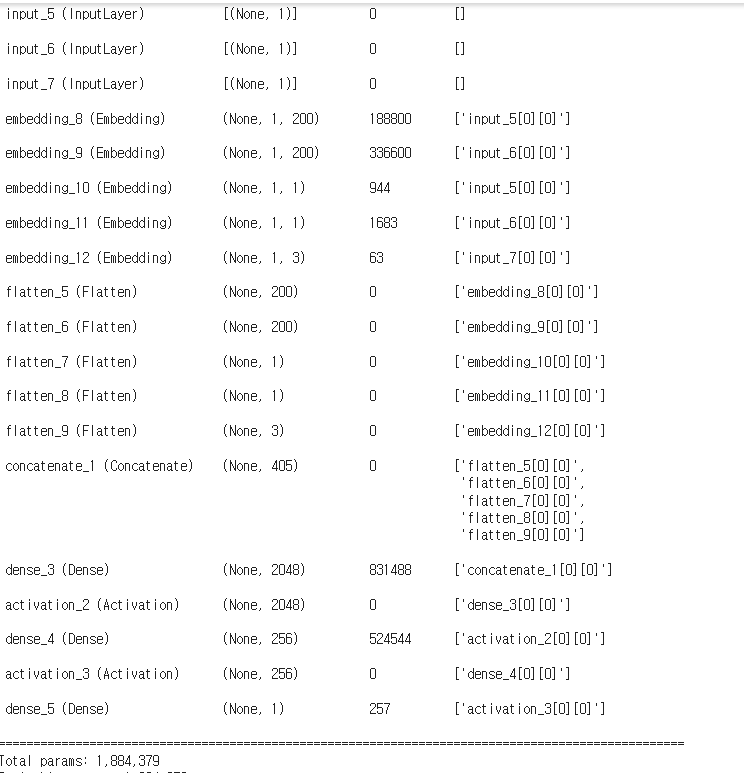
- concatenate layer의 노드의 수가 405개(200+200+1+1+직업 embedding 3)임을 볼 수 있다.
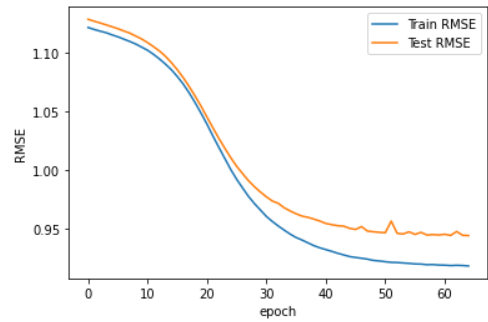
- RMSE가 0.944임을 알 수 있고, 이는 직업을 고려하지 않았을 때와 비해서 크게 향상되지 않았음을 알 수 있다.
- 때문에 직업이 사용자의 평가 패턴과 상관관계가 있다고 보기는 어렵다.
