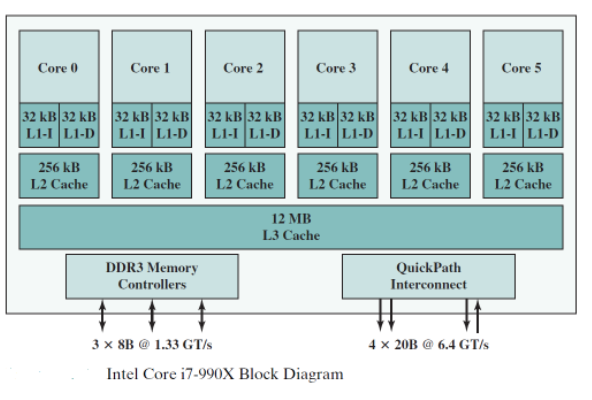
캐시 메모리
캐시 메모리의 존재를 운영체제가 알수 없을지라도, 다른 메모리 관리 하드웨어와 상호작용을 한다.
동기(Motivation)
프로세서는 명령어 사이클을 도는 동안 반드시 한번은 메모리에 접근한다.
처리기의 명령어 수행 속도는 명령어 사이클 시간에 의해 제약을 받는다.
이를 해결하기 위해서는 처리기와 메모리 간에 캐시와 같이 용량은 적으나 빠른 메모리를 제공하여 지역성의 원리를 이용해야한다
캐시의 원리
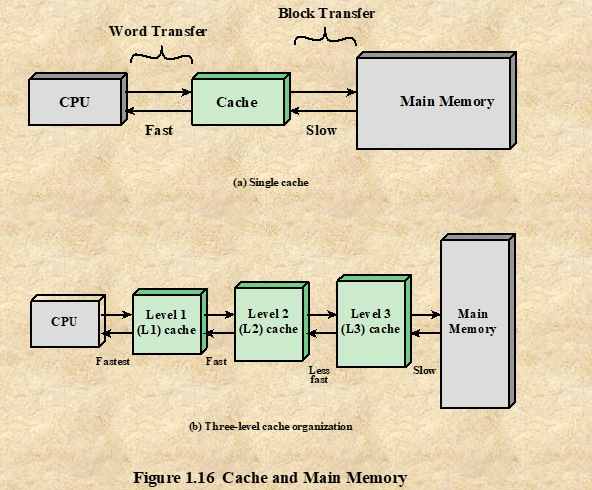
캐시 메모리의 목적
1. 자주 액세스하는 데이터와 명령어를 저장하여 CPU에서 빠르게 검색할 수 있도록 하는 것->지리적으로 서로 가깝고 자주 사용되는 데이터와 명령어를 메모리에 저장합니다.
2. 비용이 저렴한 대용량의 메모리를 제공
위 두가지는 그림(a)와 같다. 주기억 장치가 소용량이지만 속도가 빠른 캐시와 함께 사용된다.
그림(b)는 다단계 캐시 사용을 기술하고 있다.
L2캐시는 L1캐시보다 느리고 일반적으로 더 크고, L3 캐시는 L2 캐시보다 느리고 더 크다.
캐시 읽기 연산 다이어그램
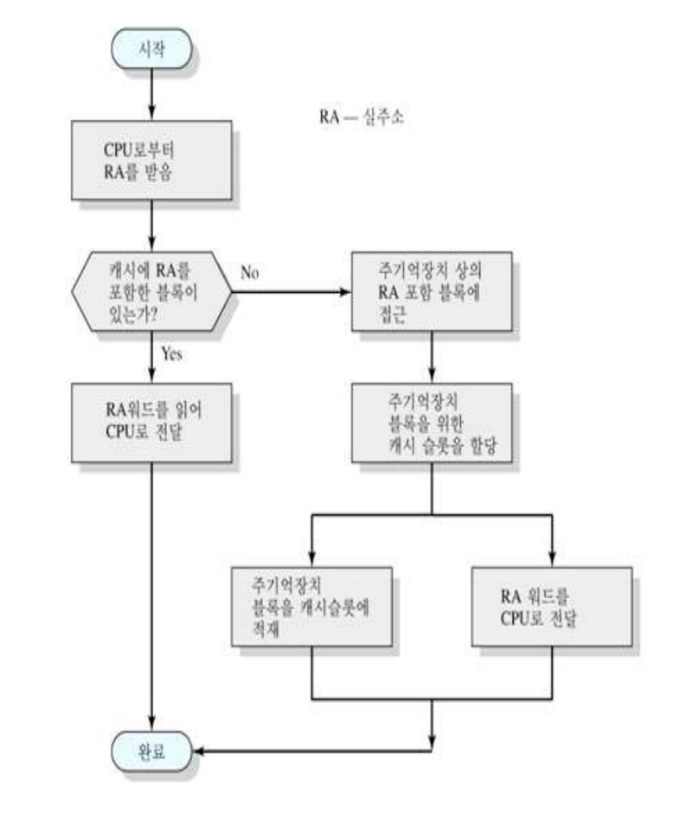
캐시 설계(Cache Design)
6가지로 크게 나뉜다.
1. 캐시 크기(Cache size)
적은 용랴의 캐시가 성능에 큰 영향을 미칠 수 있다.
2. 블록 크기(Block size)
캐시와 주기억 장치간에 교환되는 데이터 단위를 블록의 크기 라고 한다.
블록 크기가 커지면 유용한 데이터가 캐시로 이동된다. 하지만 너무 커지면 캐시 적중류이 낮아진다.-> 캐시로 새로 불려 들여온 데이터의 사용확률<데이터의 재사용 확률
3. 사상 함수(Mapping function)
새로운 데이터 블록이 캐시로 읽혀질떄, 사상함수는 그 블록이 캐시의 어느 위치에 저장될지를 결정한다.
제약조건
1. 하나의 블록을 읽어 들일 떄, 다른 블록이 교체되어야 할 수도 있다.
-> 근 미래에 다시 필요한 블록이 교체되는 확률을 최소화
2. 사상함수가 유연할수록, 지정된 블록이 캐시내에 있는지 판단하기 위한 캐시 탐색 회로가 더 복잡해진다.
4. 교체 알고리즘(Replacement Algorithm)
모든 캐시 슬롯이 채워져 있어 새로운 블록을 적재할 슬롯이 없을떄, 사상 함수의 제약조건을 만족하는 범위 내에서 교체할 블록을 선정
LRU(Least-Recently-Used)알고리즘을 이용해 가장 오랫동안 참조되지 않은 블록을 찾아낸다.
5. 쓰기 정책(Write Policy)
쓰기 정책은 메모리 쓰기 연산을 언제 수행할지 결정한다.
블록이 갱실될떄마다 쓰기가 발생할수 있다.
블록이 교체 될떄만 쓰기 정책이 이루어질 수 있는데
이떄 메모리 쓰기 연산을 최소화 해야하고, 주기억 장치의 자료가 아닌 이미 쓸모없어진 자료를 저장하고 있어 멀티프로세서 연산이나 입출력 모듈에 의한 직접 메모리 접근이 방해발들 수 있다.
6. 캐시 단계 수(number of cache levels)
다단계 캐시 구조를 뜻한다 위에 거 참조하셈
직접 메모리 접근
(번역 왜이래에ㅔㅔ에에)
프로그램 수행 중 I/O 연산 명령어와 만나면 처리기는 며려어를 수행하기 위해 해당 I/O 모듈에 명령을 내린다.
I/O 연산을 위해 사용 가능한 기법
프로그램된 입출력(Programmed I/O)
인터럽트 구동 입출력(Interrupt-driven I/O)
직접 메모리 접근(DMA)
프로그램된 입출력(Programmed I/O)
I/O 모듈이 요청된 행위를 수행하고나서 I/O 상태 레지스터 내의 관련 비트를 설정할 뿐 , 프로세서에 대해 인터럽트를 포함한 더 이상의 어떤 처리도 행하지 않는다.
-> 프로세서는 명령이 완료되었다고 판단할 떄까지 I/O 모듈의 상태를 주기적으로 점검한다.
프로그래밍된 I/O로 인해 전체 시스템의 성능 수준이 크게 저하된다.
인터럽트 구동 입출력(Interrupt-Driven I/O)
위 프로그램된 입출력의 문제인 성능 수준으로 인해 생긴 대안이다.
1.프로세서가 모듈에게 I/O 명령을 보낸 후 자신은 계속 다른 작업을 수행한다.
2.I/O 모듈이 프로세서와 데이터를 교환할 준비가 되면 프로세서를 중단하여 서비스를 요청한다.
3. 프로세서는 데이터 전송을 실행한 다음 이전 처리를 다시 시작한다.
프로그래밍 된 I/O보다 효율적이지만 메모리와 I/O 모듈 간에 데이터를 전송하려면 프로세서의 적극적인 개입이 필요하다.
I/O 형태는 두가지 문제를 가진다.
1. I/O 전송률은 프로세서가 장치를 점검하고 서비스하는 속도에 제한을 받는다.
2. 프로세서가 I/O 전송을 할 떄마다 많은 명령어들이 수행되어야 한다.
DMA(Direct Memory Access)
- 시스템 버스에서 별도의 모듈에 의해 수행되거나 I/O 모듈에 통합된다.
보통 대량의 데이터가 이동될때 사용된다.
프로세서가 한 블록의 데이터를 읽거나 쓰려 할떄, 다음과 같은 정보를 보내 DMA 모듈에 입출력을 명령한다.
. 읽기 요청인지 쓰기 요청인지 여부
. 관련 I/O 장치의 주소
. 읽거나 쓸 메모리 내의 시작 위치
. 읽거나 쓸 워드의 개수
즉 입출력 장치가 많이 느리니 CPU 방해말고 바로 버스 통해서 메모리랑 연결하는 기능이다. 그래서 인터럽트 구동 또는 프로그래밍된 I/O보다 효율성이 좋다.
멀티프로세서와 멀터코어 구조
찹 하나에 프로세서(Core)를 여러개 달아(병렬성구조) 성능을 향상 시키는데 그 방법으로는
대칭형 프로세서(Symmetric Multiprocessors,SMP)
멀티코어 컴퓨터, 클러스트 등 이 있다.
대칭형 프로세서(Symmetric Multiprocessors,SMP)
컴퓨터 하드웨어 구조나, 그 구조를 활용하는 운영체제의 행동양식이다.
특징
1. 두 개 이상의 유사한 수행 능력을 갖는 프로세서로 구성
2. 이들 프로세서는 버스나 다른 내부 연결 방식에 의해 상효 연결된, 주기억장치와 I/O 장치를 고유한다. 따라서 각 프로세서들이 메모리에 접근하는 시간은 거의 동일하다.
3. 동일한 장치에 이르는 경로들을 제공하는 채널이 동일하거나 달라도 모든 프로세서는 I/O 장치 접근을 공유하다.
4. 모든 처리기는 동일한 기능을 수행할 수 있다.
5. 시스템은 프로세서들과 작업, 태스크 , 파일 그리고 데이터 요소 수준에서 프로그램들 간의 상호작용을 제공하는 하나의 통합된 운영체제에 의해 제어된다.
장점
Performace(성능): 작업의 일부가 병렬로 처리될 수 있다면, 여러 개의 처리기로 구성된 시스템은 동일한 타입의 단일 처리기로 구성된 시스템에 비해 많은 성능 향상이 가능하다.
Availability(가용성): 하나가 고장나더라도 시스템은 다소 성능이 떨어진 상태에서 지속적으로 수행할 수 있다.
Incremental Growth(점진적 확장): 사용자느 성능 향상을 위해 필요할 떄마다 처리기를 추가로 설치 할 수 있다.
Scaling(크기조정): 벤더들은 시스템을 구성하는 처리기의 숭 ㅔ따라 가겨과 성능이 다른 다양한 제품을 공급할 수 있다.
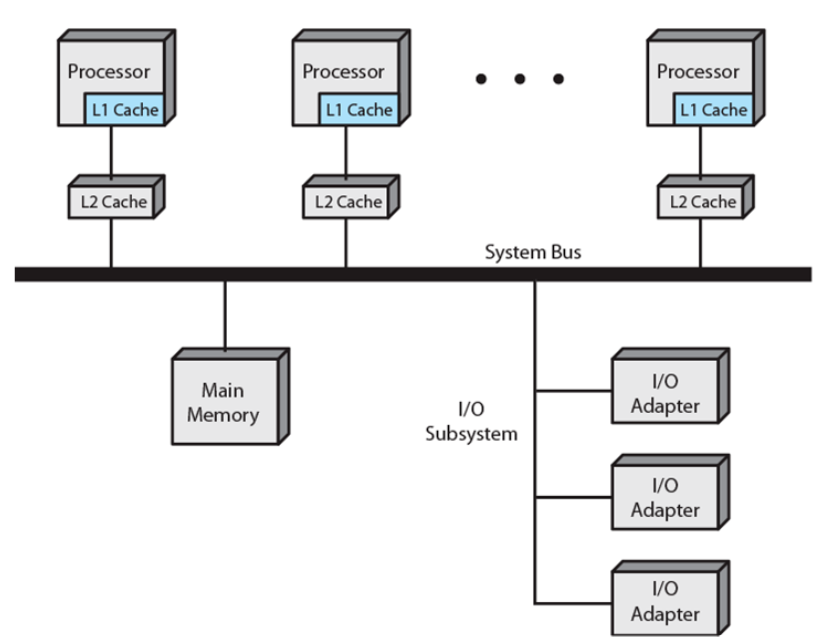
멀티코어 컴퓨터(Multicore Computer)
chip multiprocessor라고 알려져있다.
다이라 불리는 하나의 실리콘 조각에 두개 이상의 프로세서(core)가 결합되어 있고 각 코어는 독립된 프로세스의 모든 구성요소로 구성된다. 또한 멀티코어 칩에는 L2캐시와 경우에 따라 L3 캐시도 포함된다.