
📌import torch
머신러닝 알못에게 학습이란 사치이다. 생활 속 물체들을 모아놓은 데이터셋을(COCO Dataset) 이미 잘 학습한 성능 좋은 Yolo모델을 가져와 사용만 하는 것이 프로젝트의 시작이었다. 먼저 파이썬을 위한 오픈소스 머신러닝 라이브러리인 파이토치에서 Yolo를 받아와 사용하였다.
import torch
model = torch.hub.load('ultralytics/yolov5', 'yolov5s', pretrained=True)단순한 두 줄 같아 보이지만 torch 모듈이 파이참에서 바로 설치가 되는 것이 아니라 anaconda에서 install 명령어를 사용하고, 인터프리터를 바꾸고 하느라 구글링을 1시간은 한 듯 하다. 이런 곁가지 작업이 실제 프로그래밍보다 훨씬 더 스트레스를 받는 것 같다.
블로그는 https://wooriel.tistory.com/40 의 도움을 받아 torch모듈을 무사히 import할 수 있었다.
📌Yolov5로 탐지한 사진 속객체의 좌표와 레이블
그 다음 Yolo 공식 배포 github자료를 유심히 살펴보고 사진에서 인식한 객체의 객체 명, 각 좌표 값들을 받아올 수 있는지를 확인해 보았다.
https://github.com/ultralytics/yolov5/issues/36
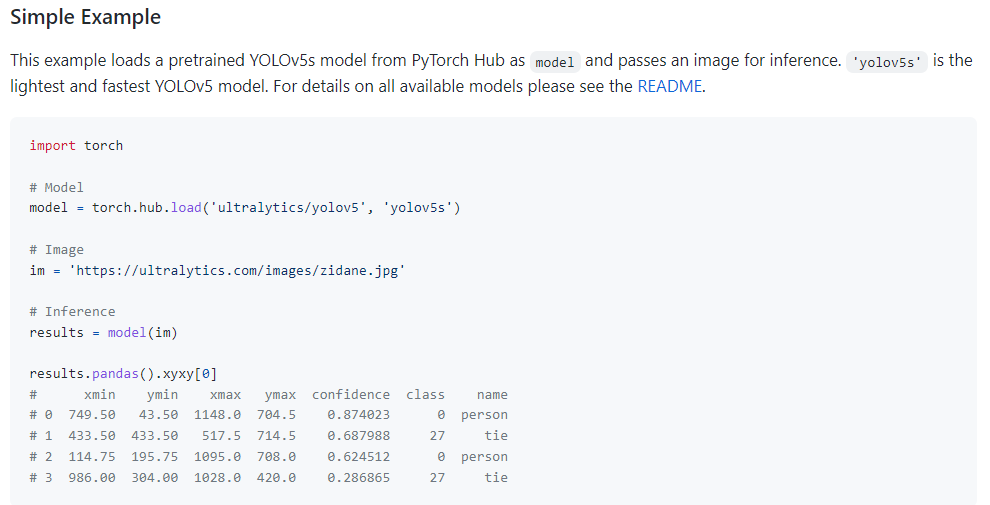
다행히 results.pandas().xyxy[0]를 출력시켰을 때 딕셔너리와 같이 각 탐지한 객체들의 좌표값, 신뢰도, 클래스 번호, 클래스 명을 모두 받아올 수 있었다.
그리고 이를 값으로 '반환'을 하려면
json.loads(picture_yolo_save(img).pandas().xyxy[0].to_json(orient="records")) 로 JSON 포맷 형태로 받아와 원하는 값에 리스트에 접근하듯이 접근할 수 있다.
def object_cords(img): # 탐지한 객체들의 좌표와 레이블을 반환해줌
return json.loads(picture_yolo_save(img).pandas().xyxy[0].to_json(orient="records"))📌다량의 사진들 크기를 일정하게 만들어주기
나의 프로젝트는 다량의 사진들을 문제은행으로 하여 무작위로 사진을 가져와, YOLO를 통하여 탐지한 객체들을 모자이크 시키고, 사용자가 맞추는 형태이다.
이를 위해서는 사진의 크기를 캔버스의 원하는 부분에 위치하게 하도록 일정한 크기로 맞춰줄 필요가 있다.
def resize_picture(img):
shrink_img = cv2.imread(img)
origin_width = shrink_img.shape[1] # width
# height
width = origin_width
while width > 531:
width = width * 0.9
width = int(width)
shrink_img = cv2.resize(shrink_img, (0, 0), fx=width / origin_width, fy=width / origin_width)
origin_height = shrink_img.shape[0]
height = origin_height
while height > 548:
height = height * 0.9
height = int(height)
shrink_img = cv2.resize(shrink_img, (0, 0), fx=height / origin_height, fy=height / origin_height)
# print(shrink_img.shape[0],shrink_img.shape[1])
return shrink_img사진 파일 크기가 너비 531px, 높이 548px이하가 되도록 반복문을 통하여 크기를 줄여주었다. 위 함수는, 모자이크가 되지 않은 정답 사진을 출력할 때에 사용된다.
여기서 주의할 점은 사진 크기를 줄이면, 객체를 탐지하던 좌표의 값도 이와 같은 비율로 줄여주어야 알맞은 위치의 좌표값을 사용할 수 있다.
📌객체의 좌표값을 사진을 축소한만큼 축소해주기
def shrink_object_cords(img, object_cords):
result_img = cv2.imread(img, cv2.IMREAD_ANYCOLOR)
origin_width = result_img.shape[1] # width
width = origin_width
while width > 531:
width = width * 0.9
for val in object_cords:
val['xmin'] = 0.9 * int(val['xmin'])
val['xmax'] = 0.9 * int(val['xmax'])
val['ymin'] = 0.9 * int(val['ymin'])
val['ymax'] = 0.9 * int(val['ymax'])
width = int(width)
result_img = cv2.resize(result_img, (0, 0), fx=width / origin_width, fy=width / origin_width)
origin_height = result_img.shape[0]
height = origin_height
while height > 548:
height = height * 0.9
for val in object_cords:
val['xmin'] = 0.9 * int(val['xmin'])
val['xmax'] = 0.9 * int(val['xmax'])
val['ymin'] = 0.9 * int(val['ymin'])
val['ymax'] = 0.9 * int(val['ymax'])
height = int(height)
result_img = cv2.resize(result_img, (0, 0), fx=height / origin_height, fy=height / origin_height)
return object_cords
shrink_object_cords(img,object_cords)는 앞서 말한 주의할 점에 근거하여 이미지와 원래의 객체들의 좌표가 매개변수로 주어지면, 축소된 좌표를 반환해준다.
📌탐지한 사진 속 객체 모자이크
def picture_yolo_mosaic(img, rate, object_cords): # yolo_save한 결과물을 가져와 모자이크를 줌
win_title = 'mosaic'
# result_vals = json.loads(picture_yolo_save(img).pandas().xyxy[0].to_json(orient="records"))#dict 형으로 x,y, 레이블 가져옴
result_img = cv2.imread(img, cv2.IMREAD_ANYCOLOR)
for val in object_cords: # 모자이크될 좌표 지정
x = int(val['xmin'])
y = int(val['ymin'])
w = int(val['xmax']) - int(val['xmin'])
h = int(val['ymax']) - int(val['ymin'])
if w and h:
roi = result_img[y:y + h, x:x + w] # 관심영역 지정
roi = cv2.resize(roi, (w // rate + 1, h // rate + 1)) # 1/rate 비율로 축소
# 원래 크기로 확대
roi = cv2.resize(roi, (w, h), interpolation=cv2.INTER_AREA)
result_img[y:y + h, x:x + w] = roi # 원본 이미지에 적용
else:
continue
result_img = cv2.rectangle(result_img, (x, y), (x + w, y + h), (255, 0, 0), 2)
origin_width = result_img.shape[1] # width
width = origin_width
while width > 531:
width = width * 0.9
for val in object_cords:
val['xmin'] = 0.9 * int(val['xmin'])
val['xmax'] = 0.9 * int(val['xmax'])
val['ymin'] = 0.9 * int(val['ymin'])
val['ymax'] = 0.9 * int(val['ymax'])
width = int(width)
result_img = cv2.resize(result_img, (0, 0), fx=width / origin_width, fy=width / origin_width)
origin_height = result_img.shape[0]
height = origin_height
while height > 548:
height = height * 0.9
for val in object_cords:
val['xmin'] = 0.9 * int(val['xmin'])
val['xmax'] = 0.9 * int(val['xmax'])
val['ymin'] = 0.9 * int(val['ymin'])
val['ymax'] = 0.9 * int(val['ymax'])
height = int(height)
result_img = cv2.resize(result_img, (0, 0), fx=height / origin_height, fy=height / origin_height)
return result_img, object_cordspicture_yolo_mosaic 함수는 사진, 모자이크 비율, 객체들의 좌표값 딕셔너리를 매개변수로 주면 모자이크를 해주는 함수이다.
모자이크 방식은 관심영역 roi를 받은 객체좌표로 지정하고, 그 영역을 rate의 비율로 축소한다음 다시 확대한다. 이 과정에서 축소된 픽셀의 크기만큼 확대가 되므로 픽셀의 수가 줄어들게 되는 것이다.
또한 이전 resize_picture(img)함수와 같은 코드를 삽입하여 똑같이 사진과 좌표를 축소시킨다.
이 때 축소된 좌표대로 각각 cv2.rectangle함수를 적용시켜 객체를 파란색으로 박스를 친다.
위 3개의 함수는 분명 겹치는 실행부가 많아 좀 더 모듈화를 효율적으로 할 수 있어보인다. 하지만 세 함수를 모두 main코드에서 사용하고 있으며 겹치는 실행부를 또다른 함수로 생성하는 것도 수정사항이 너무 많을 것 같아 내버려 두었다.
🔑3가지 함수를 적용하여 탐지한 객체별로 모자이크 된 사진을 띄워보았다.

저장한 사진을 화면에 띄우는 것은 어떤 함수를 통하여 했는지를 설명하기 위하여 다음 포스트에서는 생성한 문제들을 opencv 캔버스에 띄우는 show_quiz, show_question, show_answer 함수 작성을 다룬다.
