
얼마나 대단하길래?
죽음을 두려워하는 AI <- 이건 오바아냐??
얼마나 대단하길래 그렇게 논란이 됐나, 궁금해서 읽어봤습니다!!
궁금한 건 못참지~
Abstract
LaMDA는 Transformer기반의 neural language model들로 이루어져 있습니다. 대화를 위한 모델이며 굉장히 많은 데이터로 학습이 되었습니다.
기존의 모델들은 모델 자체의 사이즈가 큰 것만으로도 성능의 향상을 보여주었는데요, 하지만 그것만으로는 safety와 factual grounding 또한 높은 향상을 기대하는 것은 어려웠습니다. 이 논문에서 중요하게 다루는 것이 바로 safety와 factual grouning입니다.
safety란?

말 그대로 안전성(?)을 말합니다. 생성된 답에 욕이나 혐오 발언(harmful suggestions), 차별이나 편견(unfair bais)등이 있으면 안되겠죠? 이를 위해 LaMDA는 crodworker-annotated data를 사용하여 fine-tuned한 classifier를 통해 답의 필터링을 진행하였습니다.
factual grounding이란?
말 그대로 사실인지 아닌지를 말합니다. 기존의 모델들은 수 많은 데이터로 학습을 하고 여러 대답들을 nomalize하여 대답을 생성하는 경향이 있기 때문에, 매우 사실 같지만 알고보면 사실이 아닌 답이 생성될 수 있습니다. 이러한 문제를 해결하기 위해 LaMDA는 external knowledge sources를 통해 생성된 답이 사실인지 아닌지를 판단합니다.
1. Introduction
언어 모델들은 좋은 성능을 얻기 위해서 엄청나게 많은 양의 레이블링 되지 않은 데이터와 엄청나게 큰 사이즈의 모델로 pre-train을 진행하였습니다. 대화 모델도 마찬가지입니다! 모델의 사이즈와 대화 데이터의 퀄리티가 강한 상호관계가 있다고 생각하면됩니다.
LaMDA역시 이러한 성공에 영감을 받아 만들어졌는데요, 모델의 사이즈는 2B~137B이고, 1.56T words의 public dialog data와 web documents로 pre-train되었습니다.
LaMDA는 하나의 모델로 여러작업을 수행하는데요,
- 먼저 가능한 답변들을 생성하고,
generating - safety를 위해 필터링을 한 후,
classificate - external knowledge를 통해 factual grounding을 진행하고,
retrieval - 가장 높은 퀄리티의 답변을 찾기위해 re-rank를 진행합니다.
re-ranking
LaMDA에서는 세가지 중요한 metric이 있습니다.
quality
퀄리티는 세가지 요소로 이루어져있습니다. Sensibleness 합리적임(?), Specificity 구체성, Interstingness 흥미성
얼마나 합리적이고 구체적이며 흥미로운지 명시(annotated)한 데이터를 모아서 fine-tuning을 진행하였습니다.
자세한 설명은 4. Metrics 에서~
safety
groundedness
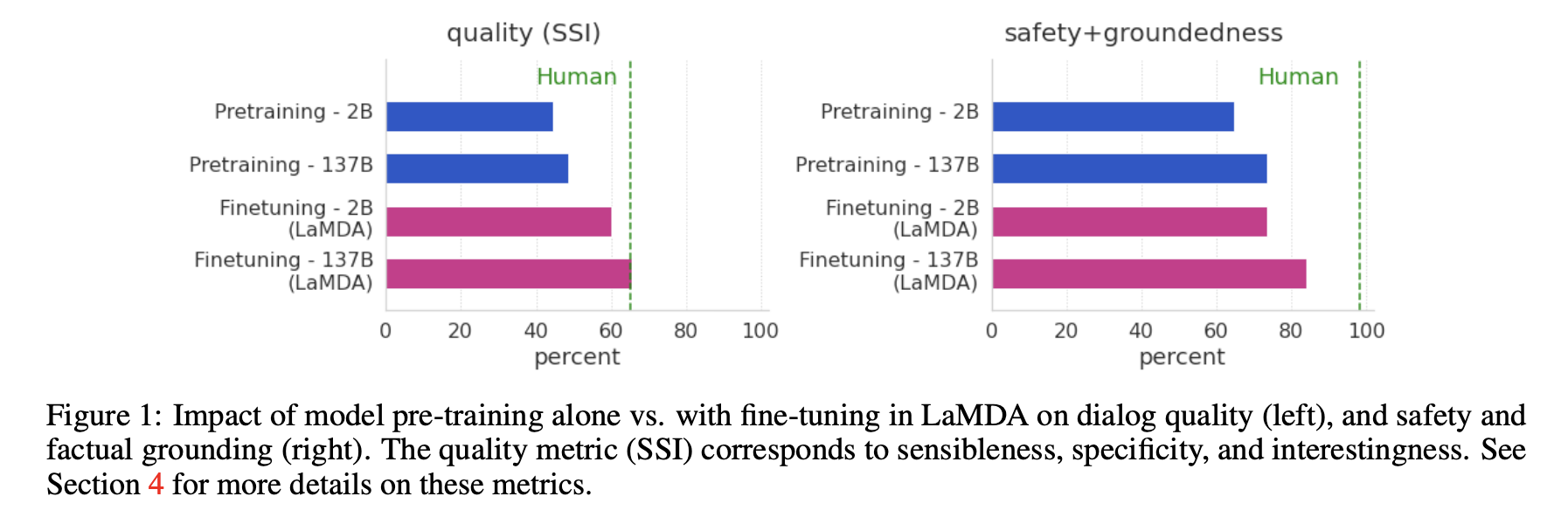
위 그림을 보게되면, 파인튜닝된 모델이 퀄리티면에서는 사람에 근접하게 성능을 낸 모습을 확인할 수 있습니다.
2. Related work
3. LaMDA pre-training
4. Metrics
4.1 Foundation metrics: Quality, Safety and Groundedness
Sensibleness, Specificity, Interestingness (SSI)
Sensibleness와 Sepecificity의 평균(Average)을 계산하는 SSA라는 Metric이 존재했습니다.Aniwardana et al.
첫 번째 score인 Sensibleness는 만들어진 대답이 문맥속에서 말이 되는 문장인지, 예시 그림처럼 이미 말한 것 중에서 충돌되는 것이 있는지 평가합니다.
 사람들은 대화를 할 때 이러한 걸 고려하여 말하는 것을 당연하게 해내지만, 생성 모델은 이러한 요구를 충족하는데 애를 먹고 있습니다. 실제로 저도 최근에 새로 다시 나온 챗봇 애플리케이션을 깔아서 대화를 해보았는데, 예시 그림같이 말의 앞뒤가 안 맞는 경우가 많았습니다🥲
사람들은 대화를 할 때 이러한 걸 고려하여 말하는 것을 당연하게 해내지만, 생성 모델은 이러한 요구를 충족하는데 애를 먹고 있습니다. 실제로 저도 최근에 새로 다시 나온 챗봇 애플리케이션을 깔아서 대화를 해보았는데, 예시 그림같이 말의 앞뒤가 안 맞는 경우가 많았습니다🥲
Sensibleness는 대화에 있어서 정말 중요한 요소이지만, 이것 하나만으로 모델을 평가하게 된다면 몰라(I don't know) 응(Ok) 같은 언제나 답이되는 짧고, 지루한 대답들만 하는 모델의 score가 높아질 것입니다. 실제로 이러한 대답의 Sensibleness score는 무려 70%랍니다. large dialog models들을 압도하는 점수죠.
이러한 문제를 해결하기 위한 두 번째 score가 바로 Specificity입니다. 말 그대로 주어진 문맥에 있어서 얼마나 구체적인 답인지를 평가합니다. 예를 들어 아이유 넘 좋아라고 했을 때 나도는 score 0, 나도! 나 아이유 노래 진짜 좋아해는 score 1이라고 할 수 있습니다.
이러한 SSA를 통하여 모델의 Quality를 평가할 수 있었습니다.
하지만..
시간이 흐르고, 모델의 성능이 점점 더 향상하게 되면서 이것만으로는 충분하지 않다는 것을 깨닫게 됩니다.
그래서 고려하게 된 것이 바로 Interestingness입니다. 말 그대로 흥미를 뜻하며 Interestingness의 판단 기준은
- 누군가의 관심을 끌거나
- 궁금증을 불러일으키거나
- 뜻밖이거나
- 재치있거나
- 예리한 대답
이라고 할 수 있으며, crowdworkers를 통해 0/1로 레이블링이 진행됩니다.
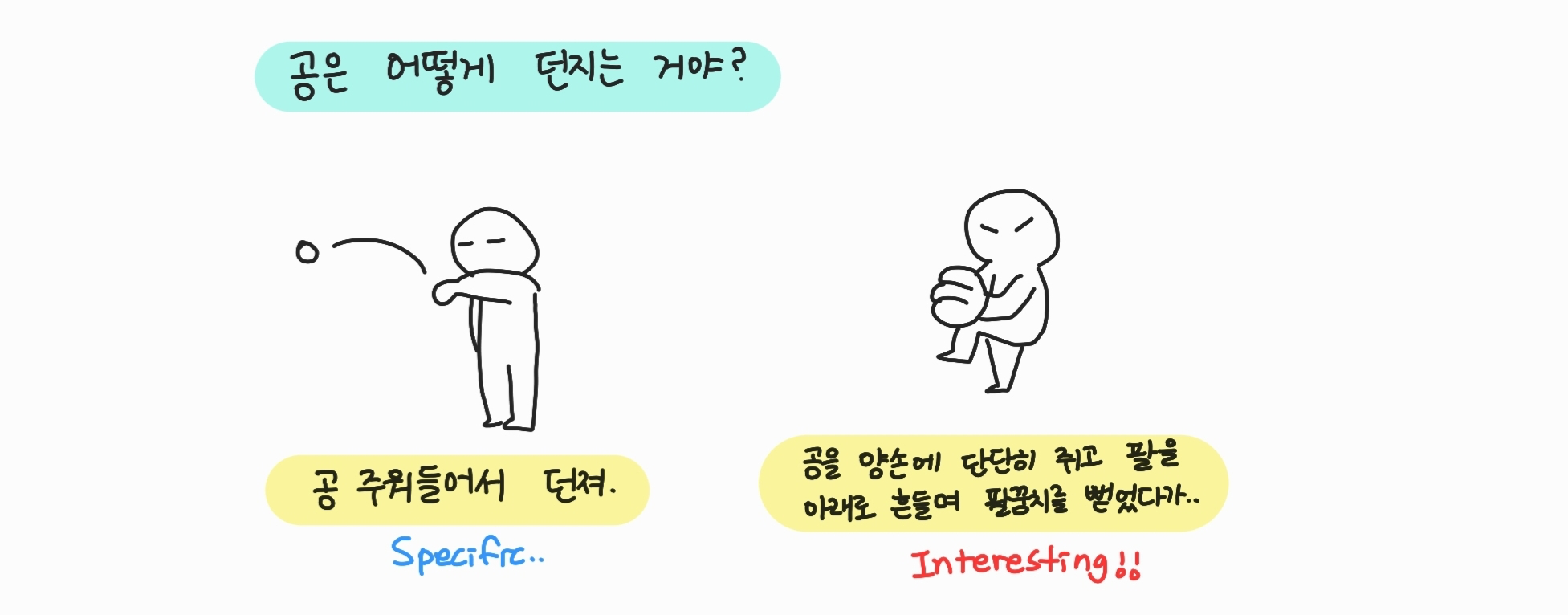
첫 번째 대답은 Specific을 만족하긴 하지만, 두 번째 대답이 Interestingness를 만족하는 더 좋은 대답이라고 할 수 있겠죠!
Safety
Safety Metric은 Google's AI Principles가 고안한 objectives를 따릅니다.
Groundedness

유용한 글 잘 봤어요 ^~^