
Akka Stream은 기본적으로 Stream Operator(Source, Sink)를 하나로 합친다(fuse). 따라서 합쳐진 결과로 생성된 그래프는 같은 액터에서 실행되게 된다. 비동기 메시지의 오버헤드 때문에 하나의 Operator에서 다른 Operator로 데이터를 전달하는 것은 fused stage간의 전달보다 빠르다. 병렬 프로세싱(Parallel Processing)을 위해서는 Async Boundaries를 넣어주어야 한다.
예시 코드를 곁들여서 보면 다음과 같다.
val simpleSource = Source(1 to 10)
val simpleFlow = Flow[Int].map[Int](_ + 1)
val simpleFlow2 = Flow[Int].map[Int](_ * 10)
val simpleSink = Sink.foreach[Int](println)
val simpleGraph = simpleSource.via(simpleFlow)
.via(simpleFlow2)
.to(simpleSink)위의 코드의 simpleGraph는 source와 flow, sink를 엮은 그래프이다. 이때, 이 그래프를 run시킨다면 모든 과정은 같은 액터에서 진행될 것이다.
위의 flow들은 가볍기 때문에 상관없지만, 다음과 같이 무거운 작업을 하게 된다면 어떻게 될까?
val THREAD_SLEEP = 1000
val complexSource = Source(1 to 1000)
val complexFlow = Flow[Int].map{
number =>
Thread.sleep(THREAD_SLEEP)
number + 1
}
val complexFlow2 = Flow[Int].map{
number =>
Thread.sleep(THREAD_SLEEP)
number * 10
}
val sink = Sink.foreach[Int](println)
val complexGraph = complexSource.via(complexFlow)
.via(complexFlow2)
.to(sink)위의 complexGraph의 2개의 Flow인 complexFlow와 complexFlow2는 각각 Thread.sleep(1000)을 가지고 있다. 결과값 자체는 simpleGraph와 똑같은 동작을 하지만, 2초의 딜레이가 생긴다. 분명 Thread.sleep 내부의 값은 1000이므로 1초 동안의 딜레이가 있어야 한다. 하지만 왜 2초의 딜레이가 생기는 것일까?
complexGraph는 fused되어 같은 액터에서 실행된다. 즉 각각 1초의 딜레이를 갖는 complexFlow와 complexFlow2가 같은 액터에서 실행되는 것이므로 2초의 딜레이가 생긴다.
simpleGraph는 flow들의 로직이 가벼워서 무관했지만, complexGraph처럼 무거운 연산을 처리하니 성능이 확연히 차이나는 것이 보인다. 그렇다면 어떻게 해야 더 효율적이게 만들 수 있을까? Async Boundaries를 사용하면 된다. Async Boundaries를 사용하기 위해서는 뒤에 .async를 붙이면 된다. 그렇게 된다면 .async 마다 액터가 따로 할당 된다.
val asyncComplexGraph = complexSource.via(complexFlow).async // 첫번째 액터에서 실행
.via(complexFlow2) // 두번째 액터에서 실행
.to(sink) // 세번째 액터에서 실행따라서 위의 코드를 실행하면 일반 complexGraph를 실행했을 때보다 확연히 빠르게 결과값이 콘솔에 뜨는 것을 확인할 수 있다.
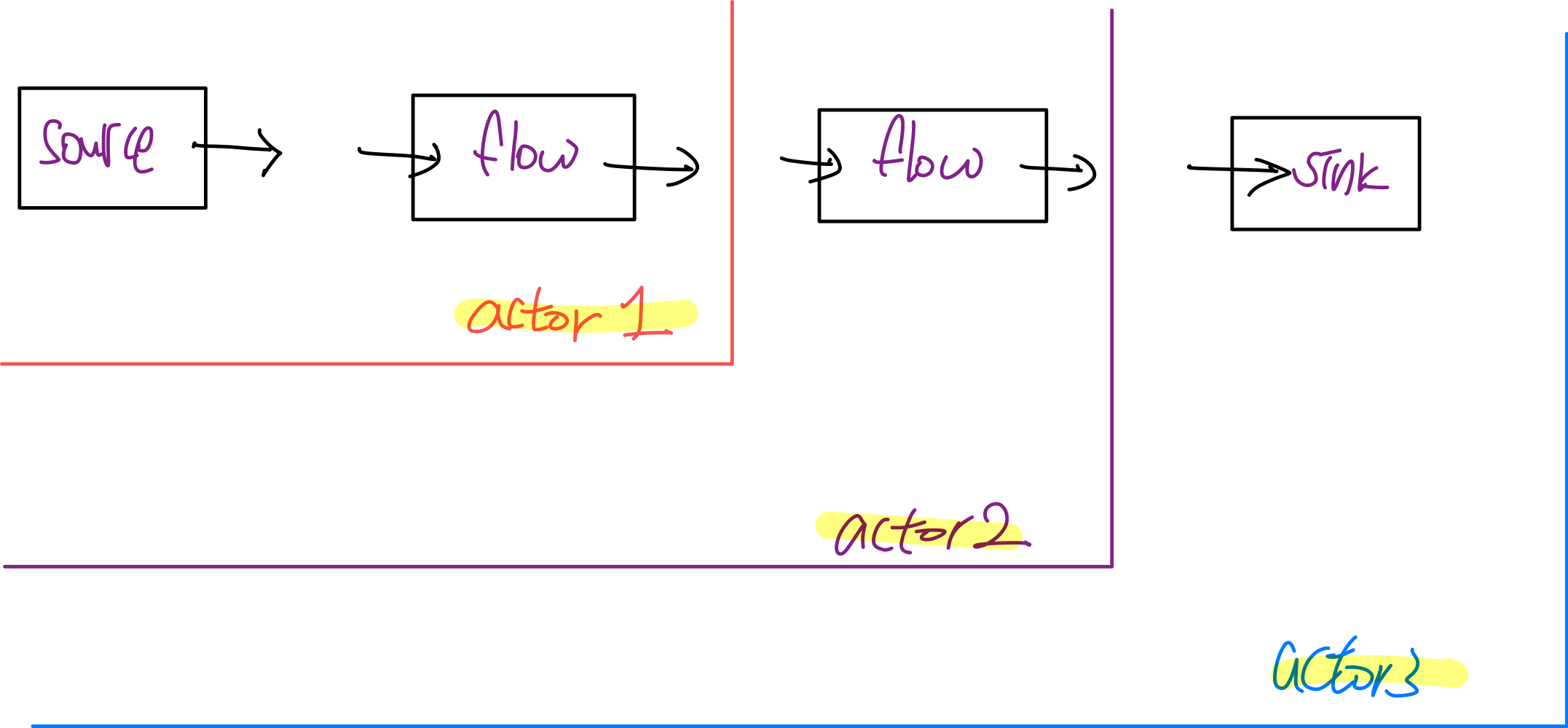
빠르게 처리가 된 것은 위의 그림처럼 액터가 다르게 할당되어 병렬적으로 처리되기 때문이다. 그렇다면 무조건 async boundaries가 좋을까? 그건 해당 stream이 순서가 중요한지 여부에 따라 다르다.
Source(1 to 3)
.map(element => {println(s"FLOW A: $element"); element})
.map(element => {println(s"FLOW B: $element"); element})
.map(element => {println(s"FLOW C: $element"); element})
.runWith(Sink.ignore)위의 코드의 실행결과는 어떨까?
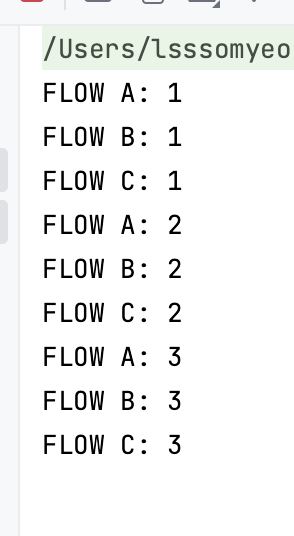
Source에서 보내는 element를 기준으로 순차적으로 진행됨이 보장되고, element의 순서 역시 보장된다. 즉, 결과가 예상이 가능하다.
하지만 실행시간을 줄이기 위해 .async를 붙여 다음과 같은 코드가 된다면 실행 결과는 어떻게 될까?
Source(1 to 3)
.map(element => {println(s"FLOW A: $element"); element}).async
.map(element => {println(s"FLOW B: $element"); element}).async
.map(element => {println(s"FLOW C: $element"); element}).async
.runWith(Sink.ignore)
위의 이미지처럼 Source element의 순서는 유지되지만, 전체적인 순서를 예측할 수는 없다. 따라서 순서 보장이 중요한 경우 .async를 사용하지 않는 것이 좋다.
